11.1. استراتيجيات للقياس حسابيًا: بيانات أكبر#
بالنسبة لبعض التطبيقات، يُمثل مقدار الأمثلة والميزات (أو كليهما) و/أو السرعة التي يجب معالجتها بها تحديًا للطرق التقليدية. في هذه الحالات، لدى scikit-learn عدد من الخيارات التي يمكنك مراعاتها لجعل نظامك قابلًا للتطوير.
11.1.1. التطوير مع حالات باستخدام التعلم خارج النواة#
التعلم خارج النواة (أو "الذاكرة الخارجية") هو أسلوب يُستخدم للتعلم من البيانات التي لا يمكن أن تتناسب مع ذاكرة الكمبيوتر الرئيسية (RAM).
فيما يلي رسم تخطيطي لنظام مُصمم لتحقيق هذا الهدف:
طريقة لتدفق الحالات
طريقة لاستخراج الميزات من الحالات
خوارزمية تزايدية
11.1.1.1. تدفق الحالات#
بشكل أساسي، قد تكون 1 قارئًا يُعطي حالات من ملفات على محرك أقراص ثابت أو قاعدة بيانات أو من تدفق شبكة، إلخ. ومع ذلك، فإن التفاصيل حول كيفية تحقيق ذلك تتجاوز نطاق هذه الوثائق.
11.1.1.2. استخراج الميزات#
قد تكون 2 أي طريقة ذات صلة لاستخراج الميزات من بين أساليب استخراج الميزات المختلفة التي تدعمها scikit-learn. ومع ذلك، عند العمل مع البيانات التي تحتاج إلى تحويل متجهي وحيث لا تكون مجموعة الميزات أو القيم معروفة مُسبقًا، يجب على المرء توخي الحذر بشكل صريح. من الأمثلة الجيدة تصنيف النصوص حيث من المُرجّح أن يتم العثور على مصطلحات غير معروفة أثناء التدريب. من الممكن استخدام مُحوّل متجهي ذي حالة إذا كان إجراء تمريرات متعددة على البيانات أمرًا معقولًا من وجهة نظر التطبيق. وإلا، يمكن للمرء زيادة الصعوبة باستخدام أداة استخراج ميزات عديمة الحالة. حاليًا، الطريقة المُفضّلة للقيام بذلك هي استخدام ما يُسمى خدعة التجزئة كما هو مُطبّق بواسطة sklearn.feature_extraction.FeatureHasher لمجموعات البيانات ذات المتغيرات الفئوية المُمَثلة كقائمة من قواميس بايثون أو sklearn.feature_extraction.text.HashingVectorizer لمستندات نصية.
11.1.1.3. التعلم التزايدي#
أخيرًا، بالنسبة لـ 3، لدينا عدد من الخيارات داخل scikit-learn. على الرغم من أنه لا يمكن لجميع الخوارزميات التعلم بشكل تزايدي (أي دون رؤية جميع الحالات في وقت واحد)، فإن جميع المقدرات التي تُطبّق واجهة برمجة تطبيقات partial_fit هي مُرشّحة. في الواقع، إن القدرة على التعلم بشكل تزايدي من دفعة صغيرة من الحالات (تُسمى أحيانًا "التعلم عبر الإنترنت") هي مفتاح التعلم خارج النواة لأنها تضمن أنه في أي وقت من الأوقات لن يكون هناك سوى كمية صغيرة من الحالات في الذاكرة الرئيسية. قد يتضمن اختيار حجم جيد للدفعة الصغيرة التي تُوازن بين الصلة وحجم الذاكرة بعض الضبط [1].
فيما يلي قائمة بالمقدرات التزايدية لمهام مُختلفة:
بالنسبة للتصنيف، هناك شيء مهم يجب ملاحظته وهو أنه على الرغم من أن إجراء استخراج الميزات عديم الحالة قد يكون قادرًا على التعامل مع سمات جديدة/غير مرئية، فإن المُتعلم التزايدي نفسه قد لا يكون قادرًا على التعامل مع فئات أهداف جديدة/غير مرئية. في هذه الحالة، يجب عليك تمرير جميع الفئات المُمكنة إلى أول استدعاء partial_fit باستخدام المعلمة classes=.
هناك جانب آخر يجب مراعاته عند اختيار خوارزمية مناسبة وهو أن ليس كلها تُعطي نفس الأهمية لكل مثال بمرور الوقت. أي أن Perceptron لا يزال حساسًا للأمثلة ذات التسميات السيئة حتى بعد العديد من الأمثلة، بينما تكون عائلات SGD* و PassiveAggressive* أكثر قوة لهذا النوع من القطع الأثرية. على العكس من ذلك، يميل الأخير أيضًا إلى إعطاء أهمية أقل للأمثلة المُختلفة بشكل ملحوظ، ولكنها مُعلمة بشكل صحيح، عندما تأتي متأخرة في التدفق حيث ينخفض مُعدل تعلمها بمرور الوقت.
11.1.1.4. أمثلة#
أخيرًا، لدينا مثال كامل لـ Out-of-core classification of text documents. يهدف إلى توفير نقطة انطلاق للأشخاص الذين يرغبون في بناء أنظمة تعلم خارج النواة ويُوضح معظم المفاهيم التي تمت مناقشتها أعلاه.
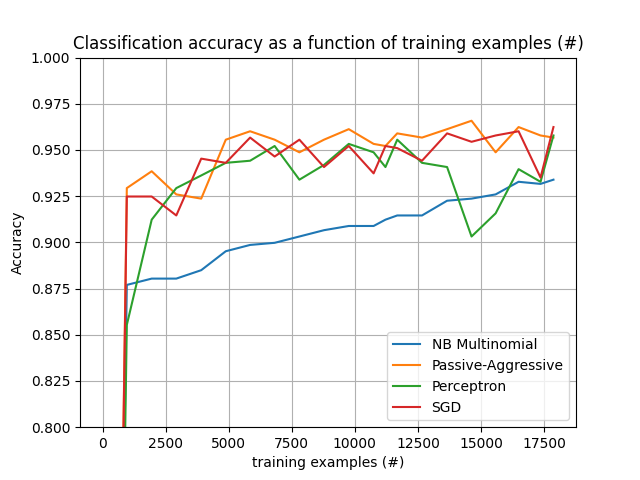
علاوة على ذلك، يُظهر أيضًا تطور أداء الخوارزميات المختلفة مع عدد الأمثلة المُعالجة.
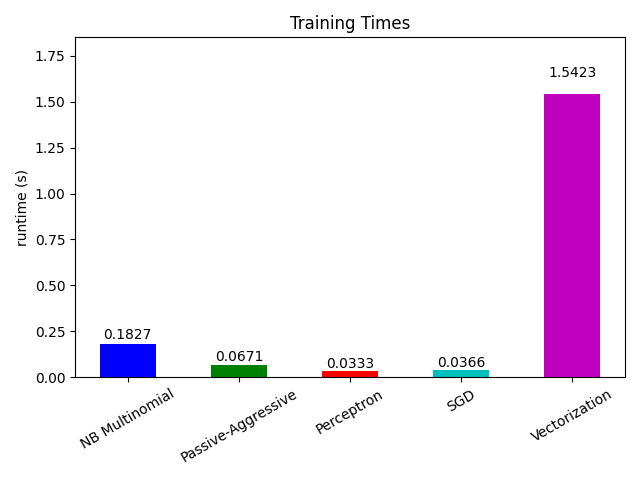
بالنظر الآن إلى وقت حساب الأجزاء المختلفة، نرى أن تحويل المتجهات أغلى بكثير من التعلم نفسه. من بين الخوارزميات المختلفة، MultinomialNB هي الأغلى، ولكن يمكن تخفيف نفقاتها العامة عن طريق زيادة حجم الدفعات الصغيرة (تمرين: غيّر minibatch_size إلى 100 و 10000 في البرنامج وقارن).