1.12. خوارزميات متعددة التصنيف ومتعددة الإخراج#
يغطي هذا القسم من دليل المستخدم الوظائف المتعلقة بمشاكل التعلم المتعدد، بما في ذلك: multiclass:، و: multilabel:، و: multioutput: التصنيف والتراجع.
تطبق الوحدات النمطية في هذا القسم: meta-estimators:، والتي تتطلب توفير مقدر أساسي في منشئها. تعمل الميتا-مقدرات على توسيع وظائف المقدر الأساسي لدعم مشاكل التعلم المتعدد، والتي يتم تحقيقها من خلال تحويل مشكلة التعلم المتعدد إلى مجموعة من المشاكل البسيطة، ثم تناسب مقدر واحد لكل مشكلة.
يغطي هذا القسم وحدتين نمطيتين: sklearn.multiclass: وsklearn.multioutput:. يوضح الرسم البياني أدناه أنواع المشاكل التي تتحمل كل وحدة نمطية المسؤولية عنها، والمقدرات الفوقية المقابلة التي توفرها كل وحدة نمطية.
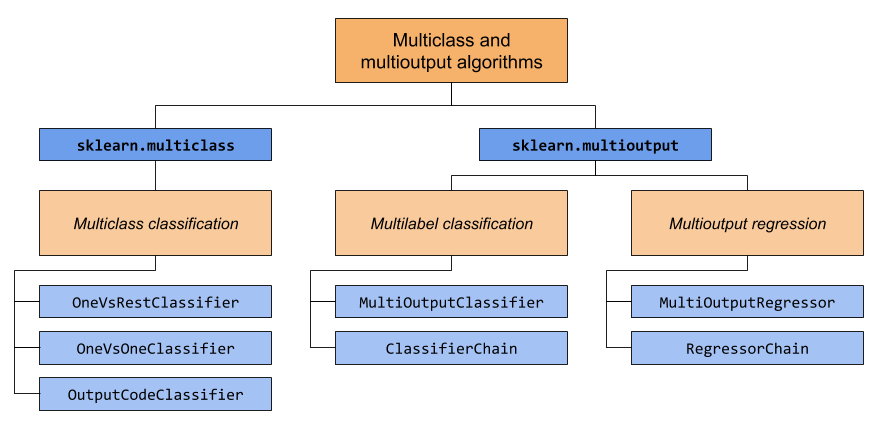
يوفر الجدول أدناه مرجعًا سريعًا حول الاختلافات بين أنواع المشاكل. يمكن العثور على تفسيرات أكثر تفصيلاً في الأقسام اللاحقة من هذا الدليل.
فيما يلي ملخص لمقدرات scikit-learn التي تحتوي على دعم التعلم المتعدد المدمج، مجمعة حسب الاستراتيجية. لا تحتاج إلى المقدرات الفوقية التي توفرها هذه الوحدة النمطية إذا كنت تستخدم أحد هذه المقدرات. ومع ذلك، يمكن أن توفر المقدرات الفوقية استراتيجيات إضافية تتجاوز ما هو مدمج:
متعدد الفئات بشكل أساسي:
svm.LinearSVC(إعداد multi_class="crammer_singer")linear_model.LogisticRegression(مع معظم المحللين)linear_model.LogisticRegressionCV(مع معظم المحللين)
متعدد الفئات كـ One-Vs-One:
gaussian_process.GaussianProcessClassifier(إعداد multi_class = "one_vs_one")
متعدد الفئات كـ One-Vs-The-Rest:
gaussian_process.GaussianProcessClassifier(إعداد multi_class = "one_vs_rest")svm.LinearSVC(إعداد multi_class="ovr")linear_model.LogisticRegression(معظم المحللين)linear_model.LogisticRegressionCV(معظم المحللين)
دعم متعدد الفئات:
دعم متعدد الفئات متعدد الإخراج:
1.12.1. متعدد الفئات#
متعدد الفئات هو مهمة تصنيف مع أكثر من فئتين. يمكن تصنيف كل عينة على أنها فئة واحدة فقط.
على سبيل المثال، التصنيف باستخدام الميزات المستخرجة من مجموعة من صور الفاكهة، حيث يمكن أن تكون كل صورة إما برتقالية أو تفاحة أو كمثرى. كل صورة هي عينة واحدة ويتم تصنيفها كواحدة من 3 فئات ممكنة. يفترض التصنيف متعدد الفئات أن كل عينة يتم تعيينها لفئة واحدة فقط - لا يمكن أن تكون عينة واحدة، على سبيل المثال، كمثرى وتفاحة.
على الرغم من أن جميع مصنفات scikit-learn قادرة على التصنيف متعدد الفئات، فإن المقدرات الفوقية التي تقدمها sklearn.multiclass تسمح بتغيير الطريقة التي تتعامل بها مع أكثر من فئتين لأن هذا قد يكون له تأثير على أداء المصنف (سواء من حيث خطأ التعميم أو الموارد الحسابية المطلوبة).
1.12.1.1. تنسيق الهدف#
تمثيلات multiclass: الصالحة لـ: func:~sklearn.utils.multiclass.type_of_target (y) هي:
1d أو متجه عمودي يحتوي على أكثر من قيمتين منفصلتين. مثال على متجه "y" لـ 4 عينات:
>>> import numpy as np >>> y = np.array(['apple', 'pear', 'apple', 'orange']) >>> print(y) ['apple' 'pear' 'apple' 'orange']
مصفوفة ثنائية كثيفة أو متفرقة ذات شكل
(n_samples, n_classes)مع عينة واحدة لكل صف، حيث يمثل كل عمود فئة واحدة. مثال على كل من المصفوفة الثنائية الكثيفة والمتفرقة "y" لـ 4 عينات، حيث الأعمدة، بالترتيب، هي التفاح والبرتقال والكمثرى:>>> import numpy as np >>> from sklearn.preprocessing import LabelBinarizer >>> y = np.array(['apple', 'pear', 'apple', 'orange']) >>> y_dense = LabelBinarizer().fit_transform(y) >>> print(y_dense) [[1 0 0] [0 0 1] [1 0 0] [0 1 0]] >>> from scipy import sparse >>> y_sparse = sparse.csr_matrix(y_dense) >>> print(y_sparse) <Compressed Sparse Row sparse matrix of dtype 'int64' with 4 stored elements and shape (4, 3)> Coords Values (0, 0) 1 (1, 2) 1 (2, 0) 1 (3, 1) 1
لمزيد من المعلومات حول: class:~sklearn.preprocessing.LabelBinarizer، راجع: preprocessing_targets:.
1.12.1.2. OneVsRestClassifier#
تتمثل استراتيجية one-vs-rest، المعروفة أيضًا باسم one-vs-all، في: class:~sklearn.multiclass.OneVsRestClassifier. تتكون الاستراتيجية من تناسب مصنف واحد لكل فئة. بالنسبة لكل مصنف، يتم تناسب الفئة مقابل جميع الفئات الأخرى. بالإضافة إلى كفاءتها الحسابية (فقط n_classes من المصنفات مطلوبة)، تتمثل إحدى مزايا هذا النهج في إمكانية تفسيرها. نظرًا لأن كل فئة ممثلة بمصنف واحد فقط، فمن الممكن اكتساب المعرفة حول الفئة من خلال فحص المصنف المقابل لها. هذه هي الاستراتيجية الأكثر استخدامًا وهي خيار افتراضي جيد.
فيما يلي مثال على التعلم متعدد الفئات باستخدام OvR:
>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsRestClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsRestClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
OneVsRestClassifier يدعم أيضًا التصنيف متعدد الفئات. لاستخدام هذه الميزة، قم بتغذية المصنف بمصفوفة مؤشرات، حيث تشير الخلية [i, j] إلى وجود التصنيف j في العينة i.
أمثلة
1.12.1.3. OneVsOneClassifier#
OneVsOneClassifier يقوم ببناء مصنف واحد لكل زوج من الفئات. في وقت التنبؤ، يتم اختيار الفئة التي حصلت على معظم الأصوات. في حالة التعادل (بين فئتين بنفس عدد الأصوات)، يتم اختيار الفئة ذات مستوى الثقة الأعلى في التصنيف التراكمي من خلال جمع مستويات الثقة في التصنيف الثنائي المزدوج التي يحسبها المصنفات الثنائية الأساسية.
نظرًا لأنه يتطلب ملاءمة n_classes * (n_classes - 1) / 2 من المصنفات، فإن هذه الطريقة تكون عادةً أبطأ من one-vs-the-rest، بسبب تعقيدها O(n_classes^2). ومع ذلك، قد تكون هذه الطريقة مفيدة للخوارزميات مثل خوارزميات النواة التي لا تتدرج جيدًا مع n_samples. ويرجع ذلك إلى أن كل مشكلة تعلم فردية لا تتضمن سوى جزء صغير من البيانات، في حين أن مجموعة البيانات الكاملة تستخدم n_classes مرات مع one-vs-the-rest. الدالة القرارية هي نتيجة تحويل أحادي للتصنيف أحادي مقابل واحد.
فيما يلي مثال على التعلم متعدد الفئات باستخدام OvO:
>>> from sklearn import datasets
>>> from sklearn.multiclass import OneVsOneClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> OneVsOneClassifier(LinearSVC(random_state=0)).fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
مراجع
"Pattern Recognition and Machine Learning. Springer", Christopher M. Bishop, page 183, (First Edition)
1.12.1.4. OutputCodeClassifier#
تختلف استراتيجيات Output-Code-based اختلافًا كبيرًا عن one-vs-the-rest وone-vs-one. مع هذه الاستراتيجيات، يتم تمثيل كل فئة في مساحة Euclidean، حيث يمكن أن يكون كل بُعد إما 0 أو 1. طريقة أخرى لوضعها هي أن كل فئة يتم تمثيلها بواسطة كود ثنائي (صفيف من 0 و1). المصفوفة التي تتتبع موقع/كود كل فئة تسمى كتاب الكود. حجم الكود هو أبعاد المساحة المذكورة أعلاه. بديهيًا، يجب تمثيل كل فئة بواسطة كود فريد قدر الإمكان ويجب تصميم كتاب الكود لتحسين دقة التصنيف. في هذا التنفيذ، نستخدم ببساطة كتاب كود تم إنشاؤه بشكل عشوائي كما هو موضح في [3] على الرغم من أنه قد يتم إضافة طرق أكثر تفصيلاً في المستقبل.
في وقت الملاءمة، يتم ملاءمة مصنف ثنائي واحد لكل بت في كتاب الكود. في وقت التنبؤ، يتم استخدام المصنفات لمشروع نقاط جديدة في مساحة الفئة ويتم اختيار الفئة الأقرب إلى النقاط.
في OutputCodeClassifier، تسمح سمة "code_size" للمستخدم بالتحكم في عدد المصنفات التي سيتم استخدامها. إنه نسبة مئوية من إجمالي عدد الفئات.
سيحتاج رقم بين 0 و1 إلى مصنفات أقل من one-vs-the-rest. من الناحية النظرية، log2(n_classes) / n_classes كافٍ لتمثيل كل فئة بشكل لا لبس فيه. ومع ذلك، في الممارسة العملية، قد لا يؤدي ذلك إلى دقة جيدة لأن log2(n_classes) أصغر بكثير من n_classes.
سيحتاج رقم أكبر من 1 إلى مزيد من المصنفات من one-vs-the-rest. في هذه الحالة، سيقوم بعض المصنفات نظريًا بتصحيح أخطاء المصنفات الأخرى، وبالتالي اسم "تصحيح الأخطاء". ومع ذلك، في الممارسة العملية، قد لا يحدث ذلك لأن أخطاء المصنفات ستكون عادةً مترابطة. يكون للرموز الإخراجية لتصحيح الأخطاء تأثير مشابه لـ bagging.
فيما يلي مثال على التعلم متعدد الفئات باستخدام Output-Codes:
>>> from sklearn import datasets
>>> from sklearn.multiclass import OutputCodeClassifier
>>> from sklearn.svm import LinearSVC
>>> X, y = datasets.load_iris(return_X_y=True)
>>> clf = OutputCodeClassifier(LinearSVC(random_state=0), code_size=2, random_state=0)
>>> clf.fit(X, y).predict(X)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
مراجع
"Solving multiclass learning problems via error-correcting output codes", Dietterich T., Bakiri G., Journal of Artificial Intelligence Research 2, 1995.
1.12.2. متعدد الفئات#
متعدد الفئات (مرتبط ارتباطًا وثيقًا بـ متعدد الإخراج التصنيف) هو مهمة تصنيف تقوم بتصنيف كل عينة باستخدام "m" من التصنيفات من "n_classes" من الفئات الممكنة، حيث يمكن أن يكون "m" من 0 إلى "n_classes" شاملاً. يمكن اعتبار ذلك بمثابة تشغيل "n_classes" من مهام التصنيف الثنائية، على سبيل المثال مع: class:~sklearn.multioutput.MultiOutputClassifier. يعالج هذا النهج كل تسمية بشكل مستقل في حين أن مصنفات متعددة التصنيف قد تعالج الفئات المتعددة في نفس الوقت، مع مراعاة السلوك المترابط بينها.
على سبيل المثال، التنبؤ بالموضوعات ذات الصلة بوثيقة نصية أو فيديو. قد تكون الوثيقة أو الفيديو حول أحد الموضوعات "الدين" أو "السياسة" أو "المالية" أو "التعليم"، أو العديد من فئات الموضوعات أو كلها.
1.12.2.1. تنسيق الهدف#
تمثيل صالح لـ: term:multilabel y هو مصفوفة ثنائية كثيفة أو متفرقة ذات شكل (n_samples, n_classes). يمثل كل عمود فئة. تشير "1" في كل صف إلى الفئات الإيجابية التي تم تصنيف العينة بها. مثال على مصفوفة كثيفة "y" لـ 3 عينات:
>>> y = np.array([[1, 0, 0, 1], [0, 0, 1, 1], [0, 0, 0, 0]])
>>> print(y)
[[1 0 0 1]
[0 0 1 1]
[0 0 0 0]]
يمكن أيضًا إنشاء مصفوفات ثنائية كثيفة باستخدام: class:~sklearn.preprocessing.MultiLabelBinarizer. لمزيد من المعلومات، راجع: preprocessing_targets:.
مثال على نفس "y" في شكل مصفوفة متفرقة:
>>> y_sparse = sparse.csr_matrix(y)
>>> print(y_sparse)
<Compressed Sparse Row sparse matrix of dtype 'int64'
with 4 stored elements and shape (3, 4)>
Coords Values
(0, 0) 1
(0, 3) 1
(1, 2) 1
(1, 3) 1
1.12.2.2. MultiOutputClassifier#
يمكن إضافة دعم التصنيف متعدد الفئات إلى أي مصنف باستخدام: class:~sklearn.multioutput.MultiOutputClassifier. تتكون هذه الاستراتيجية من ملاءمة مصنف واحد لكل هدف. يسمح هذا بالتصنيفات متعددة المتغيرات الهدف. الغرض من هذه الفئة هو تمديد المقدرات لتكون قادرة على تقدير سلسلة من وظائف الهدف (f1، f2، f3...، fn) والتي يتم تدريبها على مصفوفة X واحدة للتنبؤ بسلسلة من الاستجابات (y1، y2، y3...، yn).
يمكنك العثور على مثال للاستخدام لـ: class:~sklearn.multioutput.MultiOutputClassifier كجزء من القسم حول: ref:multiclass_multioutput_classification نظرًا لأنه تعميم للتصنيف متعدد الفئات للإخراج الثنائي بدلاً من الإخراج الثنائي.
1.12.2.3. ClassifierChain#
سلاسل المصنفات (انظر: class:~sklearn.multioutput.ClassifierChain) هي طريقة لدمج عدد من المصنفات الثنائية في نموذج متعدد الفئاتات قادر على استغلال الارتباطات بين الأهداف.
لمشكلة التصنيف متعدد الفئاتات مع N من الفئات، يتم تعيين N من المصنفات الثنائية رقمًا صحيحًا بين 0 وN-1. تحدد هذه الأرقام الصحيحة ترتيب النماذج في السلسلة. يتم بعد ذلك ملاءمة كل مصنف باستخدام بيانات التدريب المتاحة بالإضافة إلى التصنيفات الحقيقية للفئات التي تم تعيين نماذجها برقم أقل.
عند التنبؤ، لن تكون التصنيفات الحقيقية متاحة. بدلاً من ذلك، يتم تمرير تنبؤات كل نموذج إلى النماذج اللاحقة في السلسلة لاستخدامها كميزات.
من الواضح أن ترتيب السلسلة مهم. لا يمتلك النموذج الأول في السلسلة أي معلومات حول التصنيفات الأخرى في حين أن النموذج الأخير في السلسلة لديه ميزات تشير إلى وجود جميع التصنيفات الأخرى. بشكل عام، لا يعرف المرء الترتيب الأمثل للنماذج في السلسلة لذا عادةً ما يتم ترتيب العديد من السلاسل بشكل عشوائي وتتم متوسطة تنبؤاتها معًا.
مراجع
Jesse Read, Bernhard Pfahringer, Geoff Holmes, Eibe Frank, "Classifier Chains for Multi-label Classification", 2009.
1.12.3. متعدد الفئات متعدد الإخراج#
متعدد الفئات متعدد الإخراج (المعروف أيضًا باسم متعدد المهام التصنيف) هو مهمة تصنيف تقوم بتصنيف كل عينة بمجموعة من الخصائص غير الثنائية. كل من عدد الخصائص وعدد الفئات لكل خاصية أكبر من 2. وبالتالي، يعالج المقدر الواحد عدة مهام تصنيف مشتركة. هذا تعميم لمهمة التصنيف متعدد الفئاتات، والتي تعتبر فقط السمات الثنائية، وكذلك تعميم لمهمة التصنيف متعدد الفئاتات، حيث يتم النظر في خاصية واحدة فقط.
على سبيل المثال، تصنيف خصائص "نوع الفاكهة" و"اللون" لمجموعة من صور الفاكهة. تحتوي الخاصية "نوع الفاكهة" على الفئات الممكنة: "تفاحة"، و"كمثرى"، و"برتقال". تحتوي الخاصية "اللون" على الفئات الممكنة: "أخضر"، و"أحمر"، و"أصفر"، و"برتقالي". كل عينة هي صورة لفاكهة، ويتم إخراج التصنيف لكل من الخاصيتين ويكون كل تصنيف واحدًا من الفئات الممكنة للخاصية المقابلة.
ملاحظة: جميع المصنفات التي تعالج مهام متعدد الفئات متعدد الإخراج (المعروفة أيضًا باسم مهام التصنيف متعدد المهام)، تدعم مهمة التصنيف متعدد الفئاتات كحالة خاصة. يتشابه التصنيف متعدد المهام مع مهمة التصنيف متعدد الإخراج مع صيغ نموذج مختلفة. لمزيد من المعلومات، راجع وثائق المقدر ذات الصلة.
فيما يلي مثال على التصنيف متعدد الفئات متعدد الإخراج:
>>> from sklearn.datasets import make_classification
>>> from sklearn.multioutput import MultiOutputClassifier
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.utils import shuffle
>>> import numpy as np
>>> X, y1 = make_classification(n_samples=10, n_features=100,
... n_informative=30, n_classes=3,
... random_state=1)
>>> y2 = shuffle(y1, random_state=1)
>>> y3 = shuffle(y1, random_state=2)
>>> Y = np.vstack((y1, y2, y3)).T
>>> n_samples, n_features = X.shape # 10,100
>>> n_outputs = Y.shape[1] # 3
>>> n_classes = 3
>>> forest = RandomForestClassifier(random_state=1)
>>> multi_target_forest = MultiOutputClassifier(forest, n_jobs=2)
>>> multi_target_forest.fit(X, Y).predict(X)
array([[2, 2, 0],
[1, 2, 1],
[2, 1, 0],
[0, 0, 2],
[0, 2, 1],
[0, 0, 2],
[1, 1, 0],
[1, 1, 1],
[0, 0, 2],
[2, 0, 0]])
تحذير
حاليًا، لا توجد مقاييس في: mod:sklearn.metrics
تدعم مهمة التصنيف متعدد الفئات متعدد الإخراج.
1.12.3.1. تنسيق الهدف#
تمثيل صالح لـ: term:multioutput y هو مصفوفة كثيفة ذات شكل
(n_samples, n_classes) من تصنيفات الفئات. تجميع عمودي لـ 1d
multiclass المتغيرات. مثال على "y" لـ 3 عينات:
>>> y = np.array([['apple', 'green'], ['orange', 'orange'], ['pear', 'green']])
>>> print(y)
[['apple' 'green']
['orange' 'orange']
['pear' 'green']]
1.12.4. متعدد الإخراج التراجع#
متعدد الإخراج التراجع يتنبأ بالعديد من الخصائص الرقمية لكل عينة. كل خاصية هي متغير رقمي وعدد الخصائص المراد التنبؤ بها لكل عينة أكبر من أو يساوي 2. بعض المقدرات التي تدعم التراجع متعدد الإخراج أسرع من مجرد تشغيل n_output من المقدرات.
على سبيل المثال، التنبؤ بكل من سرعة الرياح واتجاه الرياح، بالدرجات، باستخدام البيانات التي يتم الحصول عليها من موقع معين. كل عينة ستكون بيانات يتم الحصول عليها من موقع واحد وسيتم إخراج كل من سرعة الرياح والاتجاه لكل عينة.
المقدرات التالية تدعم التراجع متعدد الإخراج بشكل أصلي:
1.12.4.1. تنسيق الهدف#
تمثيل صالح لـ: term:multioutput y هو مصفوفة كثيفة ذات شكل
(n_samples, n_output) من العوامات. تجميع عمودي لـ: term:continuous المتغيرات. مثال على "y" لـ 3 عينات:
>>> y = np.array([[31.4, 94], [40.5, 109], [25.0, 30]])
>>> print(y)
[[ 31.4 94. ]
[ 40.5 109. ]
[ 25. 30. ]]
1.12.4.2. MultiOutputRegressor#
يمكن إضافة دعم التراجع متعدد الإخراج إلى أي مقدر تراجع باستخدام: class:~sklearn.multioutput.MultiOutputRegressor. تتكون هذه الاستراتيجية من ملاءمة مقدر واحد لكل هدف. نظرًا لأن كل هدف يمثله مقدر واحد بالضبط، فمن الممكن اكتساب المعرفة حول الهدف من خلال فحص المقدر المقابل له. نظرًا لأن: class:~sklearn.multioutput.MultiOutputRegressor يقوم بملاءمة مقدر واحد لكل هدف، فلا يمكنه الاستفادة من الارتباطات بين الأهداف.
فيما يلي مثال على التراجع متعدد الإخراج:
>>> from sklearn.datasets import make_regression
>>> from sklearn.multioutput import MultiOutputRegressor
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_regression(n_samples=10, n_targets=3, random_state=1)
>>> MultiOutputRegressor(GradientBoostingRegressor(random_state=0)).fit(X, y).predict(X)
array([[-154.75474165, -147.03498585, -50.03812219],
[ 7.12165031, 5.12914884, -81.46081961],
[-187.8948621 , -100.44373091, 13.88978285],
[-141.62745778, 95.02891072, -191.48204257],
[ 97.03260883, 165.34867495, 139.52003279],
[ 123.92529176, 21.25719016, -7.84253 ],
[-122.25193977, -85.16443186, -107.12274212],
[ -30.170388 , -94.80956739, 12.16979946],
[ 140.72667194, 176.50941682, -17.50447799],
[ 149.37967282, -81.15699552, -5.72850319]])
1.12.4.3. RegressorChain#
سلاسل المقدرات (انظر: class:~sklearn.multioutput.RegressorChain) هي مشابهة لـ: class:~sklearn.multioutput.ClassifierChain كطريقة لدمج عدد من التراجعات في نموذج متعدد الأهداف قادر على استغلال الارتباطات بين الأهداف.