11.2. الأداء الحسابي#
بالنسبة لبعض التطبيقات، يُعد أداء المقدرات (بشكل رئيسي زمن الوصول والإنتاجية في وقت التنبؤ) أمرًا بالغ الأهمية. قد يكون من المثير للاهتمام أيضًا مراعاة إنتاجية التدريب، ولكن هذا غالبًا ما يكون أقل أهمية في إعداد الإنتاج (حيث يحدث غالبًا في وضع عدم الاتصال).
سنُراجع هنا أوامر الحجم التي يمكنك توقعها من عدد من مقدرات scikit-learn في سياقات مختلفة ونُقدّم بعض النصائح والحيل للتغلب على اختناقات الأداء.
يتم قياس زمن الوصول للتنبؤ على أنه الوقت المنقضي اللازم لإجراء تنبؤ (على سبيل المثال، بالميلي ثانية). غالبًا ما يُنظر إلى زمن الوصول على أنه توزيع، وغالبًا ما يُركز مهندسو العمليات على زمن الوصول عند نسبة مئوية مُعطاة من هذا التوزيع (على سبيل المثال، النسبة المئوية 90).
يتم تعريف إنتاجية التنبؤ على أنها عدد التنبؤات التي يمكن للبرنامج تقديمها في مقدار مُعين من الوقت (على سبيل المثال، بالتنبؤات في الثانية).
جانب مهم من تحسين الأداء هو أنه يمكن أن يُؤثر سلبًا على دقة التنبؤ. في الواقع، غالبًا ما تعمل النماذج الأبسط (على سبيل المثال، الخطية بدلاً من غير الخطية، أو ذات معلمات أقل) بشكل أسرع ولكنها لا تستطيع دائمًا أن تأخذ في الاعتبار نفس الخصائص الدقيقة للبيانات مثل النماذج الأكثر تعقيدًا.
11.2.1. زمن الوصول للتنبؤ#
أحد أكثر المخاوف مُباشرةً التي قد تكون لدى المرء عند استخدام/اختيار مجموعة أدوات تعلم الآلة هو زمن الوصول الذي يمكن من خلاله إجراء التنبؤات في بيئة إنتاج.
العوامل الرئيسية التي تُؤثر على زمن الوصول للتنبؤ هي
عدد الميزات
تمثيل بيانات الإدخال وتفرقها
تعقيد النموذج
استخراج الميزات
المعلمة الرئيسية الأخيرة هي أيضًا إمكانية إجراء تنبؤات في وضع مُجمّع أو وضع واحد في كل مرة.
11.2.1.1. الوضع المُجمّع مقابل الوضع الذري#
بشكل عام، يُعد إجراء التنبؤات بشكل مُجمّع (العديد من المثيلات في نفس الوقت) أكثر كفاءة لعدد من الأسباب (قابلية التنبؤ بالتفرع، وذاكرة التخزين المؤقت لوحدة المعالجة المركزية، وتحسينات مكتبات الجبر الخطي، وما إلى ذلك). نرى هنا في إعداد مع عدد قليل من الميزات أنه بغض النظر عن اختيار المقدّر، فإن الوضع المُجمّع يكون دائمًا أسرع، وبالنسبة لبعضها من 1 إلى 2 أوامر من حيث الحجم:
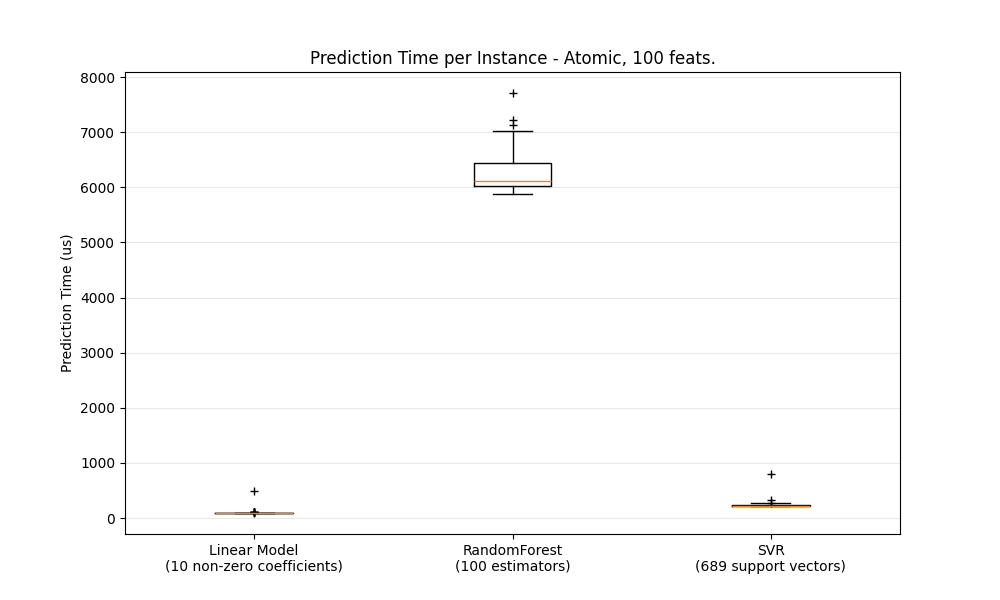
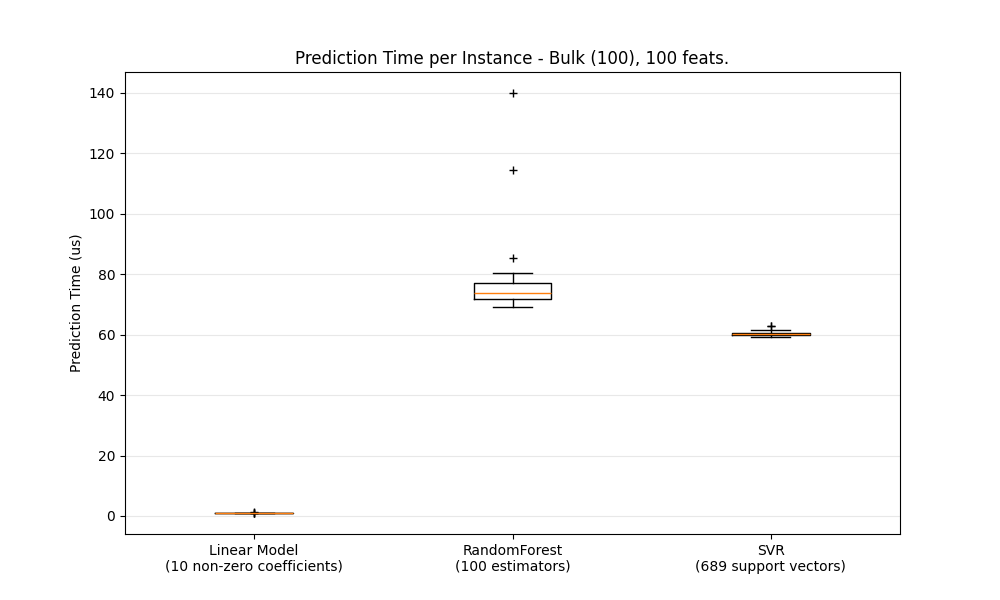
لمقارنة المقدرات المختلفة لحالتك، يمكنك ببساطة تغيير معلمة n_features في هذا المثال: تأخير التنبؤ. يجب أن يُعطيك هذا تقديرًا لترتيب حجم زمن الوصول للتنبؤ.
11.2.1.2. تكوين Scikit-learn لتقليل النفقات العامة للتحقق من الصحة#
تُجري Scikit-learn بعض التحقق من الصحة على البيانات التي تزيد من النفقات العامة لكل استدعاء لـ predict والوظائف المماثلة. على وجه الخصوص، يتضمن التحقق من أن الميزات محدودة (ليست NaN أو لانهائية) تمريرة كاملة على البيانات. إذا تأكدت من أن بياناتك مقبولة، فيمكنك إزالة التحقق من محدوديتها عن طريق تعيين متغير البيئة SKLEARN_ASSUME_FINITE إلى سلسلة غير فارغة قبل استيراد scikit-learn، أو تكوينها في بايثون باستخدام set_config. لمزيد من التحكم من هذه الإعدادات العامة، يسمح لك config_context بتعيين هذا التكوين ضمن سياق مُحدّد:
>>> import sklearn
>>> with sklearn.config_context(assume_finite=True):
... pass # إجراء التعلم/التنبؤ هنا مع تقليل التحقق من الصحة
لاحظ أن هذا سيُؤثر على جميع استخدامات assert_all_finite ضمن السياق.
11.2.1.3. تأثير عدد الميزات#
من الواضح أنه عندما يزداد عدد الميزات، يزداد أيضًا استهلاك الذاكرة لكل مثال. في الواقع، بالنسبة لمصفوفة من \(M\) مثيلات مع \(N\) ميزات، فإن تعقيد المساحة يكون في \(O(NM)\). من منظور الحوسبة، فهذا يعني أيضًا أن عدد العمليات الأساسية (على سبيل المثال، عمليات الضرب لحاصل ضرب المتجه والمصفوفة في النماذج الخطية) يزداد أيضًا. هنا رسم بياني لتطور زمن الوصول للتنبؤ مع عدد الميزات:
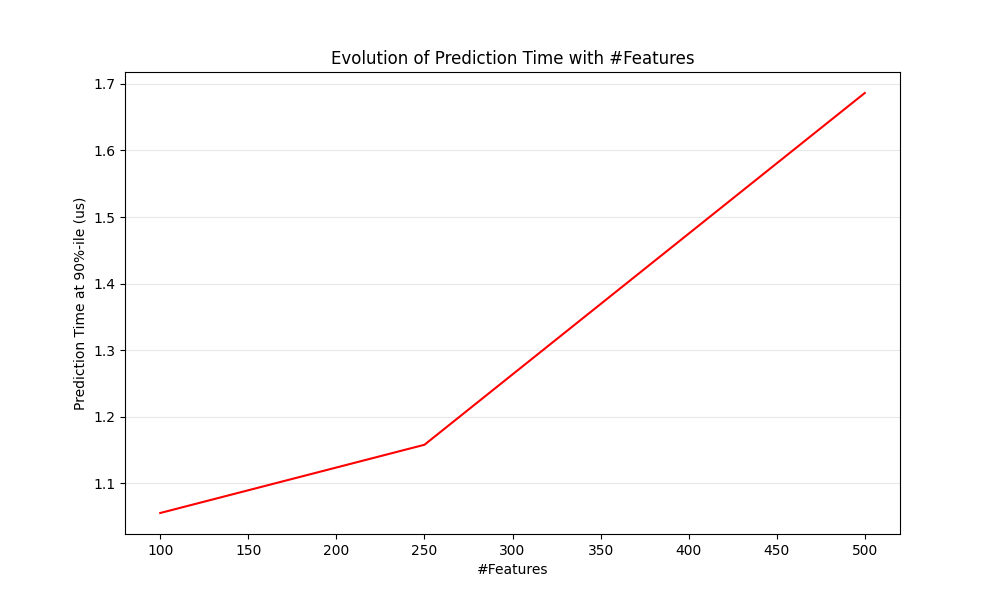
بشكل عام، يمكنك توقع أن يزداد وقت التنبؤ خطيًا على الأقل مع عدد الميزات (يمكن أن تحدث حالات غير خطية اعتمادًا على حجم الذاكرة الإجمالي والمقدر).
11.2.1.4. تأثير تمثيل بيانات الإدخال#
يُوفر Scipy هياكل بيانات مصفوفة متفرقة مُحسّنة لتخزين البيانات المتفرقة. السمة الرئيسية للتنسيقات المتفرقة هي أنك لا تُخزّن الأصفار، لذلك إذا كانت بياناتك متفرقة، فإنك تستخدم ذاكرة أقل بكثير. ستأخذ القيمة غير الصفرية في تمثيل متفرق (CSR أو CSC) في المتوسط موضع عدد صحيح واحد 32 بت + القيمة العائمة 64 بت + 32 بت إضافية لكل صف أو عمود في المصفوفة. يمكن أن يُسرّع استخدام مُدخلات متفرقة على نموذج خطي كثيف (أو متفرق) التنبؤ بشكل كبير نظرًا لأن الميزات ذات القيمة غير الصفرية فقط تُؤثر على حاصل الضرب النقطي، وبالتالي تنبؤات النموذج. لذلك، إذا كان لديك 100 قيمة غير صفرية في فضاء ذي أبعاد 1e6، فأنت تحتاج فقط إلى 100 عملية ضرب وجمع بدلاً من 1e6.
ومع ذلك، قد يستفيد الحساب على تمثيل كثيف من عمليات المتجهات المُحسّنة للغاية والترابط المتعدد في BLAS، ويميل إلى أن يؤدي إلى عدد أقل من فقدان ذاكرة التخزين المؤقت لوحدة المعالجة المركزية. لذلك، يجب أن يكون التفرق عادةً مرتفعًا جدًا (بحد أقصى 10٪ غير أصفار، ليتم التحقق منه اعتمادًا على الجهاز) ليكون تمثيل الإدخال المتفرق أسرع من تمثيل الإدخال الكثيف على جهاز به العديد من وحدات المعالجة المركزية وتطبيق BLAS مُحسّن.
فيما يلي نموذج شفرة لاختبار تفرق مُدخلاتك:
def sparsity_ratio(X):
return 1.0 - np.count_nonzero(X) / float(X.shape[0] * X.shape[1])
print("input sparsity ratio:", sparsity_ratio(X))
كقاعدة عامة، يمكنك اعتبار أنه إذا كانت نسبة التفرق أكبر من 90٪، فمن المحتمل أن تستفيد من التنسيقات المتفرقة. تحقق من وثائق تنسيقات المصفوفة المتفرقة لـ Scipy لمزيد من المعلومات حول كيفية بناء (أو تحويل بياناتك إلى) تنسيقات مصفوفة متفرقة. في معظم الأوقات، تعمل تنسيقات CSR و CSC بشكل أفضل.
11.2.1.5. تأثير تعقيد النموذج#
بشكل عام، عندما يزداد تعقيد النموذج، من المفترض أن تزداد القدرة التنبؤية وزمن الوصول. عادةً ما تكون زيادة القدرة التنبؤية أمرًا مثيرًا للاهتمام، ولكن بالنسبة للعديد من التطبيقات، من الأفضل ألا نزيد زمن الوصول للتنبؤ كثيرًا. سنُراجع الآن هذه الفكرة لعائلات مُختلفة من النماذج الخاضعة للإشراف.
بالنسبة لـ sklearn.linear_model (على سبيل المثال، Lasso و ElasticNet و SGDClassifier/Regressor و Ridge & RidgeClassifier و PassiveAggressiveClassifier/Regressor و LinearSVC و LogisticRegression...)، فإن دالة القرار التي يتم تطبيقها في وقت التنبؤ هي نفسها (حاصل ضرب نقطي)، لذلك يجب أن يكون زمن الوصول مُكافئًا.
فيما يلي مثال باستخدام SGDClassifier مع جزاء elasticnet. يتم التحكم في قوة التنظيم بشكل عام بواسطة المعلمة alpha. مع alpha عالية بما فيه الكفاية، يمكن للمرء بعد ذلك زيادة معلمة l1_ratio لـ elasticnet لفرض مُستويات مُختلفة من التفرق في معاملات النموذج. يتم تفسير التفرق الأعلى هنا على أنه تعقيد أقل للنموذج حيث نحتاج إلى عدد أقل من المعاملات لوصفه بالكامل. بالطبع، يُؤثر التفرق بدوره على وقت التنبؤ حيث يستغرق حاصل الضرب النقطي المتفرق وقتًا يتناسب تقريبًا مع عدد المعاملات غير الصفرية.
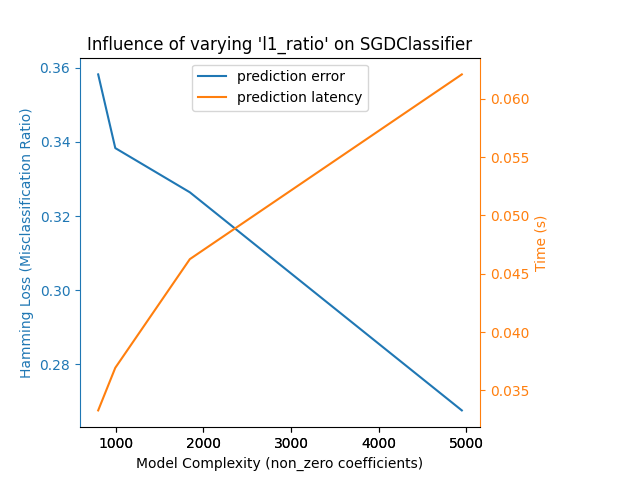
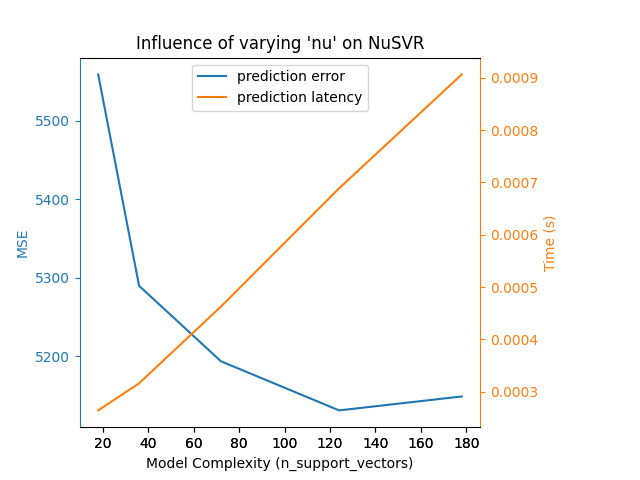
بالنسبة لعائلة خوارزميات sklearn.svm ذات نواة غير خطية، يرتبط زمن الوصول بعدد متجهات الدعم (كلما قلّ، كان أسرع). يجب أن ينمو زمن الوصول والإنتاجية (بشكل مقارب) خطيًا مع عدد متجهات الدعم في نموذج SVC أو SVR. ستُؤثر النواة أيضًا على زمن الوصول حيث يتم استخدامها لحساب إسقاط متجه الإدخال مرة واحدة لكل متجه دعم. في الرسم البياني التالي، تم استخدام معلمة nu لـ NuSVR للتأثير على عدد متجهات الدعم.
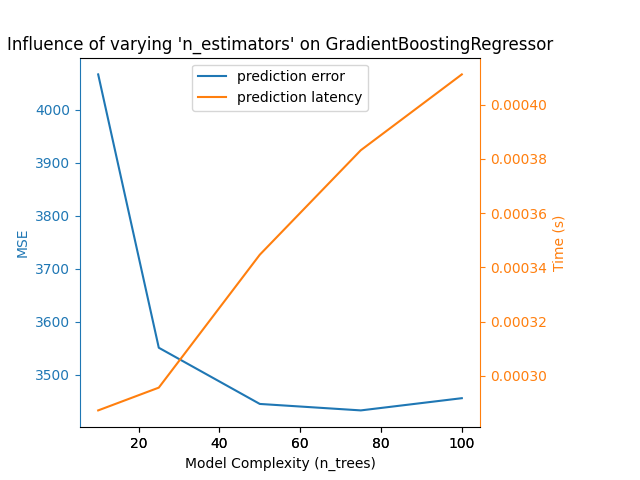
بالنسبة لـ sklearn.ensemble من الأشجار (على سبيل المثال، RandomForest و GBT و ExtraTrees وما إلى ذلك)، يلعب عدد الأشجار وعمقها الدور الأكثر أهمية. يجب أن يتدرج زمن الوصول والإنتاجية خطيًا مع عدد الأشجار. في هذه الحالة، استخدمنا مُباشرةً معلمة n_estimators لـ GradientBoostingRegressor.
في أي حال، كن حذرًا من أن تقليل تعقيد النموذج يمكن أن يُؤثر سلبًا على الدقة كما هو مذكور أعلاه. على سبيل المثال، يمكن معالجة مشكلة غير قابلة للفصل خطيًا باستخدام نموذج خطي سريع، ولكن من المُرجّح جدًا أن تتأثر القدرة التنبؤية في هذه العملية.
11.2.1.6. زمن الوصول لاستخراج الميزات#
عادةً ما تكون معظم نماذج scikit-learn سريعة جدًا حيث يتم تطبيقها إما مع ملحقات Cython المُجمّعة أو مكتبات الحوسبة المُحسّنة. من ناحية أخرى، في العديد من تطبيقات العالم الحقيقي، تُسيطر عملية استخراج الميزات (أي تحويل البيانات الأولية مثل صفوف قاعدة البيانات أو حزم الشبكة إلى مصفوفات numpy) على وقت التنبؤ الإجمالي. على سبيل المثال، في مهمة تصنيف نص رويترز، تستغرق عملية التحضير بأكملها (قراءة وتحليل ملفات SGML، وتحديد رموز النص وتجزئته إلى فضاء متجه مشترك) من 100 إلى 500 مرة أطول من رمز التنبؤ الفعلي، اعتمادًا على النموذج المُختار.
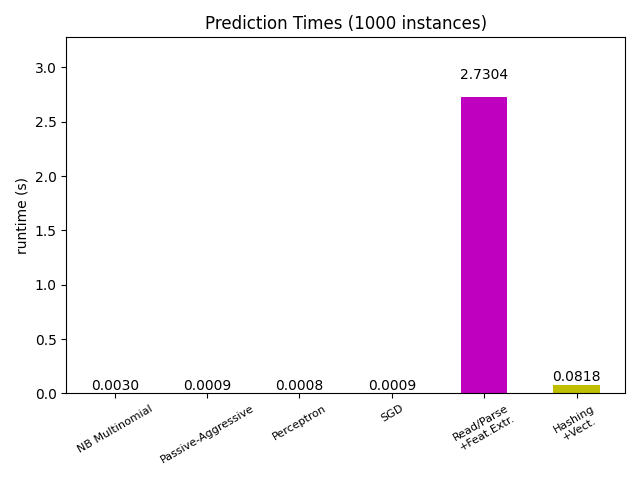
في كثير من الحالات، يُوصى بتوقيت وتوصيف رمز استخراج الميزات الخاص بك بعناية، حيث قد يكون مكانًا جيدًا للبدء في التحسين عندما يكون زمن الوصول الإجمالي لديك بطيئًا جدًا لتطبيقك.
11.2.2. إنتاجية التنبؤ#
هناك مقياس مهم آخر يجب الاهتمام به عند تحديد حجم أنظمة الإنتاج وهو الإنتاجية، أي عدد التنبؤات التي يمكنك إجراؤها في مقدار مُعين من الوقت. فيما يلي معيار من مثال تأخير التنبؤ الذي يقيس هذه الكمية لعدد من المقدرات على بيانات مُصطنعة:
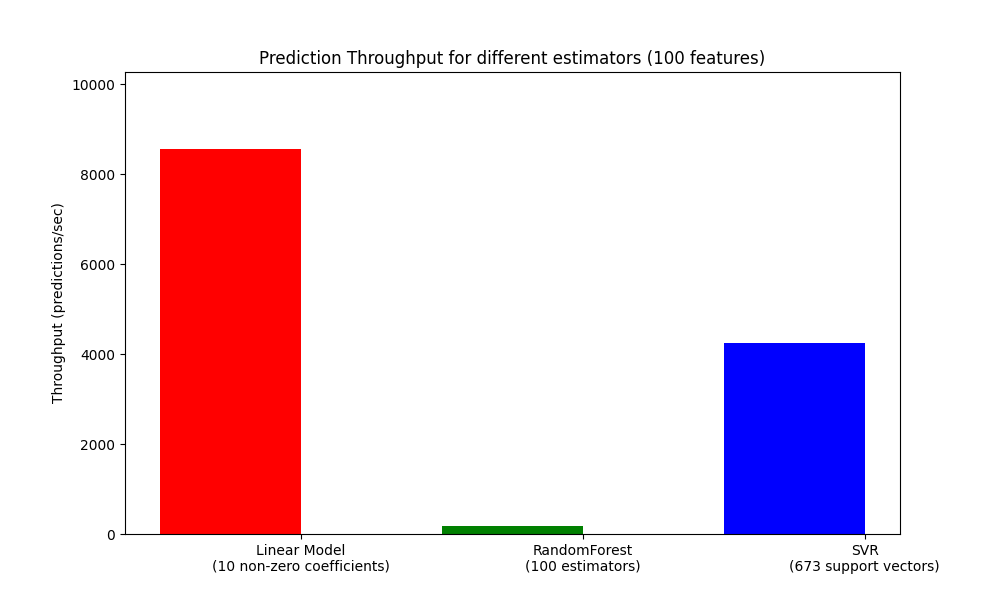
يتم تحقيق هذه الإنتاجية في عملية واحدة. من الطرق الواضحة لزيادة إنتاجية تطبيقك هي إنشاء مثيلات إضافية (عادةً عمليات في بايثون بسبب GIL) التي تُشارك نفس النموذج. قد يُضيف المرء أيضًا أجهزة لتوزيع الحمل. ومع ذلك، فإن الشرح المُفصّل لكيفية تحقيق ذلك يتجاوز نطاق هذه الوثائق.
11.2.3. نصائح وحيل#
11.2.3.1. مكتبات الجبر الخطي#
نظرًا لأن scikit-learn تعتمد بشكل كبير على Numpy/Scipy والجبر الخطي بشكل عام، فمن المنطقي أن تهتم بشكل صريح بإصدارات هذه المكتبات. بشكل أساسي، يجب عليك التأكد من أن Numpy مبنية باستخدام مكتبة BLAS / LAPACK مُحسّنة.
لا تستفيد جميع النماذج من تطبيقات BLAS و Lapack المُحسّنة. على سبيل المثال، لا تعتمد النماذج القائمة على أشجار القرار (العشوائية) عادةً على استدعاءات BLAS في حلقاتها الداخلية، ولا تعتمد أيضًا نوى SVMs (SVC، SVR، NuSVC، NuSVR). من ناحية أخرى، سيستفيد النموذج الخطي المُطبق مع استدعاء BLAS DGEMM (عبر numpy.dot) بشكل كبير من تطبيق BLAS مُحسّن وسيؤدي إلى تسريع أوامر الحجم مقارنةً بـ BLAS غير المُحسّن.
يمكنك عرض تطبيق BLAS / LAPACK المستخدم بواسطة تثبيت NumPy / SciPy / scikit-learn الخاص بك باستخدام الأمر التالي:
python -c "import sklearn; sklearn.show_versions()"
تتضمن تطبيقات BLAS / LAPACK المُحسّنة ما يلي:
Atlas (تحتاج إلى ضبط مُحدّد للجهاز عن طريق إعادة البناء على الجهاز الهدف)
OpenBLAS
MKL
أطر عمل Apple Accelerate و vecLib (OSX فقط)
يمكن العثور على مزيد من المعلومات في صفحة تثبيت NumPy وفي منشور المدونة هذا من دانيال نوري الذي يحتوي على بعض إرشادات التثبيت اللطيفة خطوة بخطوة لـ Debian / Ubuntu.
11.2.3.2. الحد من ذاكرة العمل#
تتضمن بعض الحسابات عند تطبيقها باستخدام عمليات المتجهات القياسية numpy استخدام كمية كبيرة من الذاكرة المؤقتة. قد يؤدي هذا إلى استنفاد ذاكرة النظام. حيث يمكن إجراء الحسابات في أجزاء ذات ذاكرة ثابتة، نحاول القيام بذلك، ونسمح للمستخدم بالتلميح إلى الحد الأقصى لحجم ذاكرة العمل هذه (افتراضيًا 1 غيغابايت) باستخدام set_config أو config_context. يقترح ما يلي تحديد ذاكرة العمل المؤقتة بـ 128 ميغابايت:
>>> import sklearn
>>> with sklearn.config_context(working_memory=128):
... pass # القيام بالعمل المجزأ هنا
مثال على عملية مجزأة تلتزم بهذا الإعداد هو pairwise_distances_chunked، مما يُسهّل حساب عمليات التخفيض حسب الصفوف لمصفوفة مسافة زوجية.
11.2.3.3. ضغط النموذج#
يُهم ضغط النموذج في scikit-learn النماذج الخطية فقط في الوقت الحالي. في هذا السياق، هذا يعني أننا نُريد التحكم في تفرق النموذج (أي عدد الإحداثيات غير الصفرية في متجهات النموذج). من الجيد عمومًا دمج تفرق النموذج مع تمثيل بيانات الإدخال المتفرقة.
فيما يلي نموذج شفرة يُوضح استخدام طريقة sparsify():
clf = SGDRegressor(penalty='elasticnet', l1_ratio=0.25)
clf.fit(X_train, y_train).sparsify()
clf.predict(X_test)
في هذا المثال، نُفضّل جزاء elasticnet لأنه غالبًا ما يكون حلًا وسطًا جيدًا بين ضغط النموذج وقدرة التنبؤ. يمكن للمرء أيضًا ضبط معلمة l1_ratio بشكل أكبر (بالاقتران مع قوة التنظيم alpha) للتحكم في هذه المقايضة.
ينتج عن المعيار النموذجي على البيانات المُصطنعة انخفاضًا بأكثر من 30٪ في زمن الوصول عندما يكون كل من النموذج والإدخال متفرقين (بنسبة 0.000024 و 0.027400 من المعاملات غير الصفرية على التوالي). قد تختلف المسافة المقطوعة اعتمادًا على تفرق وحجم بياناتك ونموذجك. علاوة على ذلك، يمكن أن يكون التفرق مفيدًا جدًا لتقليل استخدام الذاكرة لنماذج التنبؤ المنشورة على خوادم الإنتاج.
11.2.3.4. إعادة تشكيل النموذج#
تتكون إعادة تشكيل النموذج من تحديد جزء فقط من الميزات المتاحة لملاءمة نموذج. بعبارة أخرى، إذا تجاهل نموذج ما الميزات أثناء مرحلة التعلم، فيمكننا بعد ذلك تجريدها من الإدخال. هذا له فوائد عديدة. أولاً، يُقلل من النفقات العامة للذاكرة (وبالتالي الوقت) للنموذج نفسه. يسمح أيضًا بتجاهل مكونات اختيار الميزات الصريحة في خط أنابيب بمجرد أن نعرف الميزات التي يجب الاحتفاظ بها من تشغيل سابق. أخيرًا، يمكن أن يُساعد في تقليل وقت المعالجة واستخدام الإدخال/الإخراج في المراحل السابقة في طبقات الوصول إلى البيانات واستخراج الميزات من خلال عدم جمع وبناء الميزات التي يتجاهلها النموذج. على سبيل المثال، إذا كانت البيانات الأولية تأتي من قاعدة بيانات، فيمكن أن تجعل من الممكن كتابة استعلامات أبسط وأسرع أو تقليل استخدام الإدخال/الإخراج عن طريق جعل الاستعلامات تُعيد سجلات أخف. في الوقت الحالي، يجب إجراء إعادة التشكيل يدويًا في scikit-learn. في حالة الإدخال المتفرق (خاصةً بتنسيق CSR)، يكفي عمومًا عدم إنشاء الميزات ذات الصلة، وترك أعمدتها فارغة.