2.7. كشف القيم الغريبة والقيم المتطرفة#
تتطلب العديد من التطبيقات القدرة على تحديد ما إذا كانت مشاهدة جديدة تنتمي إلى نفس توزيع المشاهدات الموجودة (إنها قيمة داخلية)، أو يجب اعتبارها مختلفة (إنها قيمة متطرفة). غالبًا ما تُستخدم هذه القدرة لتنظيف مجموعات البيانات الحقيقية. يجب التمييز بين أمرين مهمين:
- كشف القيم المتطرفة:
تحتوي بيانات التدريب على قيم متطرفة تُعرّف على أنها مشاهدات بعيدة عن الأخرى. وبالتالي، تحاول مقدرات كشف القيم المتطرفة ملاءمة المناطق التي تتركز فيها بيانات التدريب بشكل كبير، متجاهلة المشاهدات الشاذة.
- كشف القيم الغريبة:
بيانات التدريب غير ملوثة بالقيم المتطرفة، ونحن مهتمون باكتشاف ما إذا كانت مشاهدة جديدة قيمة متطرفة. في هذا السياق، تُسمى القيمة المتطرفة أيضًا بالقيم الغريبة.
يُستخدم كل من كشف القيم المتطرفة وكشف القيم الغريبة لكشف الشذوذ، حيث يهتم المرء باكتشاف المشاهدات الشاذة أو غير العادية. يُعرف كشف القيم المتطرفة أيضًا باسم كشف الشذوذ غير الخاضع للإشراف، وكشف القيم الغريبة باسم كشف الشذوذ شبه الخاضع للإشراف. في سياق كشف القيم المتطرفة، لا يمكن للقيم المتطرفة/الشذوذ أن تُشكّل مجموعة كثيفة حيث تفترض المقدرات المتاحة أن القيم المتطرفة/الشذوذ تقع في مناطق منخفضة الكثافة. على العكس من ذلك، في سياق كشف القيم الغريبة، يمكن للجِدّة/الشذوذ أن تُشكّل مجموعة كثيفة طالما أنها في منطقة منخفضة الكثافة من بيانات التدريب، والتي تُعتبر طبيعية في هذا السياق.
يُوفر مشروع scikit-learn مجموعة من أدوات تعلم الآلة التي يمكن استخدامها لكل من كشف القيم الغريبة أو القيم المتطرفة. يتم تطبيق هذه الاستراتيجية مع الكائنات التي تتعلم بطريقة غير خاضعة للإشراف من البيانات:
estimator.fit(X_train)
يمكن بعد ذلك فرز المشاهدات الجديدة على أنها قيم داخلية أو قيم متطرفة باستخدام طريقة predict:
estimator.predict(X_test)
يتم تسمية القيم الداخلية بـ 1، بينما يتم تسمية القيم المتطرفة بـ -1. تستخدم طريقة التنبؤ عتبة على دالة التهديف الأولية التي يحسبها المقدّر. يمكن الوصول إلى دالة التهديف هذه من خلال طريقة score_samples، بينما يمكن التحكم في العتبة بواسطة المعلمة contamination.
يتم تعريف طريقة decision_function أيضًا من دالة التهديف، بحيث تكون القيم السالبة قيمًا متطرفة والقيم غير السالبة قيمًا داخلية:
estimator.decision_function(X_test)
لاحظ أن neighbors.LocalOutlierFactor لا يدعم طرق predict و decision_function و score_samples افتراضيًا، ولكن فقط طريقة fit_predict، حيث كان من المفترض أصلاً تطبيق هذا المقدّر لكشف القيم المتطرفة. يمكن الوصول إلى درجات شذوذ عينات التدريب من خلال السمة negative_outlier_factor_.
إذا كنت تُريد حقًا استخدام neighbors.LocalOutlierFactor لكشف القيم الغريبة، أي التنبؤ بالتسميات أو حساب درجة شذوذ البيانات الجديدة غير المرئية، فيمكنك إنشاء مثيل للمقدر باستخدام المعلمة novelty المُعيّنة إلى True قبل ملاءمة المقدّر. في هذه الحالة، fit_predict غير متوفرة.
تحذير
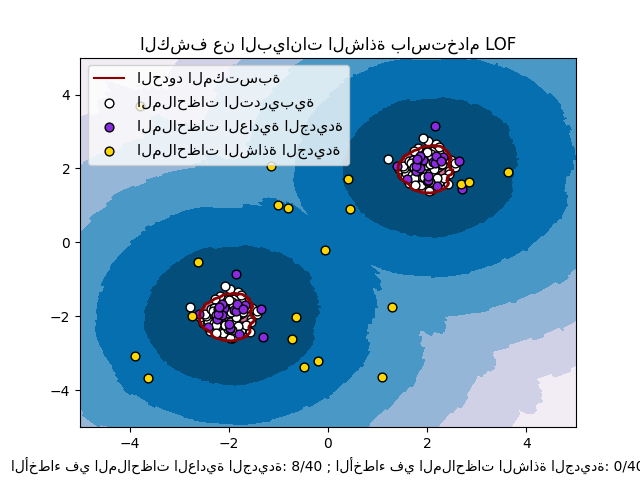
كشف القيم الغريبة باستخدام مُعامل القيم المتطرفة المحلي
عندما يتم تعيين novelty إلى True، انتبه إلى أنه يجب عليك فقط استخدام predict و decision_function و score_samples على البيانات الجديدة غير المرئية وليس على عينات التدريب، لأن هذا سيؤدي إلى نتائج خاطئة. بمعنى آخر، لن تكون نتيجة predict هي نفس نتيجة fit_predict. يمكن دائمًا الوصول إلى درجات شذوذ عينات التدريب من خلال السمة negative_outlier_factor_.
يتم تلخيص سلوك neighbors.LocalOutlierFactor في الجدول التالي.
2.7.1. نظرة عامة على أساليب كشف القيم المتطرفة#
مقارنة بين خوارزميات كشف القيم المتطرفة في scikit-learn. لا يُظهر مُعامل القيم المتطرفة المحلي (LOF) حد قرار باللون الأسود لأنه لا يحتوي على طريقة تنبؤ لتطبيقها على البيانات الجديدة عند استخدامه لكشف القيم المتطرفة.
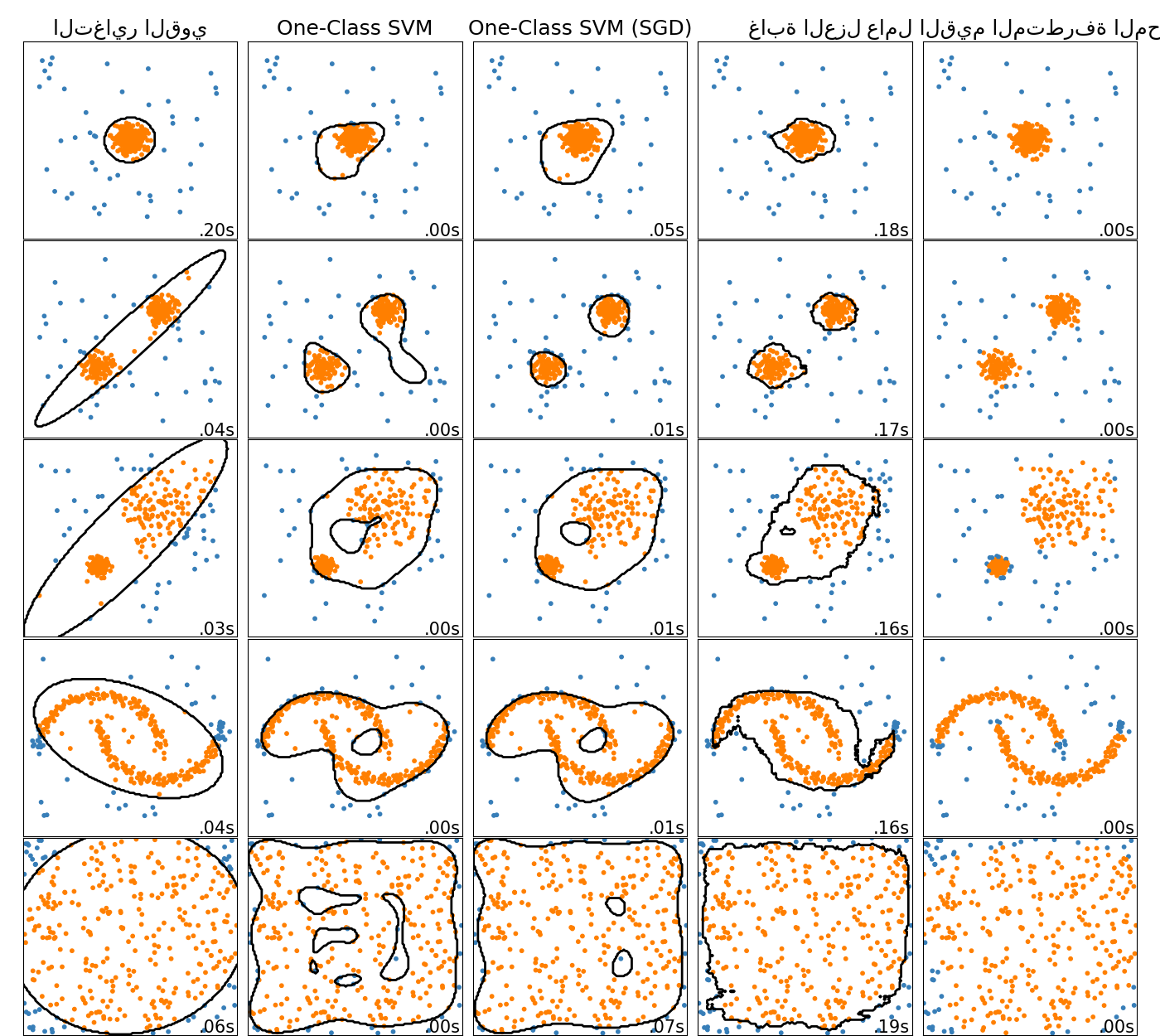
ensemble.IsolationForest و neighbors.LocalOutlierFactor يعملان بشكل جيد إلى حد معقول على مجموعات البيانات التي تم أخذها في الاعتبار هنا. من المعروف أن svm.OneClassSVM حساسة للقيم المتطرفة، وبالتالي لا تُقدم أداءً جيدًا جدًا لكشف القيم المتطرفة. ومع ذلك، فإن كشف القيم المتطرفة في الأبعاد العالية، أو بدون أي افتراضات حول توزيع البيانات الداخلية، يُمثل تحديًا كبيرًا. لا يزال من الممكن استخدام svm.OneClassSVM مع كشف القيم المتطرفة، ولكنه يتطلب ضبطًا دقيقًا للمعلمة الفائقة nu للتعامل مع القيم المتطرفة ومنع التوافق الزائد. تُوفر linear_model.SGDOneClassSVM تطبيقًا لـ One-Class SVM خطي مع تعقيد خطي في عدد العينات. يتم استخدام هذا التطبيق هنا مع تقنية تقريب النواة للحصول على نتائج مشابهة لـ svm.OneClassSVM التي تستخدم نواة غاوسية افتراضيًا. أخيرًا، تفترض covariance.EllipticEnvelope أن البيانات غاوسية وتتعلم شكل بيضاوي. لمزيد من التفاصيل حول المقدرات المختلفة، ارجع إلى المثال مقارنة خوارزميات الكشف عن الشذوذ لكشف القيم المتطرفة في مجموعات بيانات تجريبية والأقسام أدناه.
أمثلة
انظر مقارنة خوارزميات الكشف عن الشذوذ لكشف القيم المتطرفة في مجموعات بيانات تجريبية لمقارنة
svm.OneClassSVMوensemble.IsolationForestوneighbors.LocalOutlierFactorوcovariance.EllipticEnvelope.انظر تقييم خوارزميات كشف الشواذ للحصول على مثال يُظهر كيفية تقييم مقدرات كشف القيم المتطرفة،
neighbors.LocalOutlierFactorوensemble.IsolationForest، باستخدام منحنيات ROC منmetrics.RocCurveDisplay.
2.7.2. كشف القيم الغريبة#
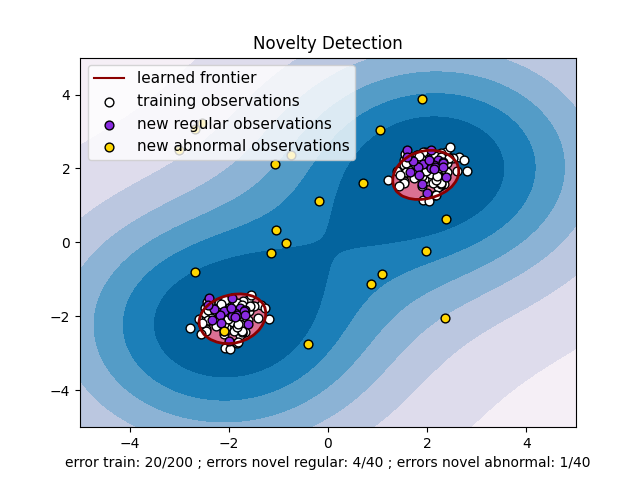
خذ في الاعتبار مجموعة بيانات من \(n\) مشاهدات من نفس التوزيع الموصوف بواسطة \(p\) ميزات. خذ في الاعتبار الآن أننا نُضيف مشاهدة واحدة أخرى إلى مجموعة البيانات هذه. هل المشاهدة الجديدة مختلفة عن الأخرى لدرجة أننا نشك في أنها منتظمة؟ (أي هل تأتي من نفس التوزيع؟) أم على العكس من ذلك، هل هي مشابهة جدًا للأخرى لدرجة أننا لا نستطيع تمييزها عن المشاهدات الأصلية؟ هذا هو السؤال الذي تُعالجه أدوات وأساليب كشف القيم الغريبة.
بشكل عام، يتعلق الأمر بتعلم حدود تقريبية تُحدّد محيط توزيع المشاهدات الأولية، المرسومة في فضاء تضمين \(p\) الأبعاد. بعد ذلك، إذا كانت المزيد من المشاهدات تقع داخل الفضاء الجزئي المُحدّد بالحدود، فإنها تُعتبر من نفس مجموعة المشاهدات الأولية. وإلا، إذا كانت تقع خارج الحدود، يمكننا القول إنها غير طبيعية مع ثقة مُعطاة في تقييمنا.
تم تقديم One-Class SVM بواسطة Schölkopf وآخرون لهذا الغرض وتم تنفيذه في وحدة آلات الدعم المتجهية (SVM) في الكائن svm.OneClassSVM. يتطلب اختيار نواة ومعلمة عددية لتعريف الحدود. يتم اختيار نواة RBF عادةً على الرغم من عدم وجود صيغة أو خوارزمية دقيقة لتعيين معلمة عرض النطاق الترددي الخاصة بها. هذا هو الافتراضي في تطبيق scikit-learn. تتوافق المعلمة nu، المعروفة أيضًا باسم هامش One-Class SVM، مع احتمال إيجاد مشاهدة جديدة، ولكن منتظمة، خارج الحدود.
المراجع
Estimating the support of a high-dimensional distribution Schölkopf, Bernhard, et al. Neural computation 13.7 (2001): 1443-1471.
أمثلة
انظر One-class SVM with non-linear kernel (RBF) لتصور الحدود التي تم تعلمها حول بعض البيانات بواسطة كائن
svm.OneClassSVM.
2.7.2.1. توسيع نطاق One-Class SVM#
يتم تطبيق إصدار خطي عبر الإنترنت من One-Class SVM في linear_model.SGDOneClassSVM. يتدرج هذا التطبيق خطيًا مع عدد العينات ويمكن استخدامه مع تقريب النواة لتقريب حل svm.OneClassSVM ذي النواة الذي يكون تعقيده تربيعيًا في أحسن الأحوال في عدد العينات. انظر قسم Online One-Class SVM لمزيد من التفاصيل.
أمثلة
انظر One-Class SVM مقابل One-Class SVM باستخدام Stochastic Gradient Descent لتوضيح تقريب One-Class SVM ذي النواة مع
linear_model.SGDOneClassSVMمُدمجًا مع تقريب النواة.
2.7.3. كشف القيم المتطرفة#
يُشبه كشف القيم المتطرفة كشف القيم الغريبة بمعنى أن الهدف هو فصل جوهر المشاهدات المنتظمة عن بعض المشاهدات الملوثة، التي تُسمى القيم المتطرفة. ومع ذلك، في حالة كشف القيم المتطرفة، ليس لدينا مجموعة بيانات نظيفة تُمثل مجموعة المشاهدات المنتظمة التي يمكن استخدامها لتدريب أي أداة.
2.7.3.1. ملاءمة غلاف بيضاوي#
إحدى الطرق الشائعة لإجراء كشف القيم المتطرفة هي افتراض أن البيانات المنتظمة تأتي من توزيع معروف (على سبيل المثال، البيانات موزعة غاوسيًا). من هذا الافتراض، نحاول عمومًا تحديد "شكل" البيانات، ويمكننا تعريف المشاهدات المتطرفة على أنها مشاهدات تبتعد بما فيه الكفاية عن الشكل المُناسب.
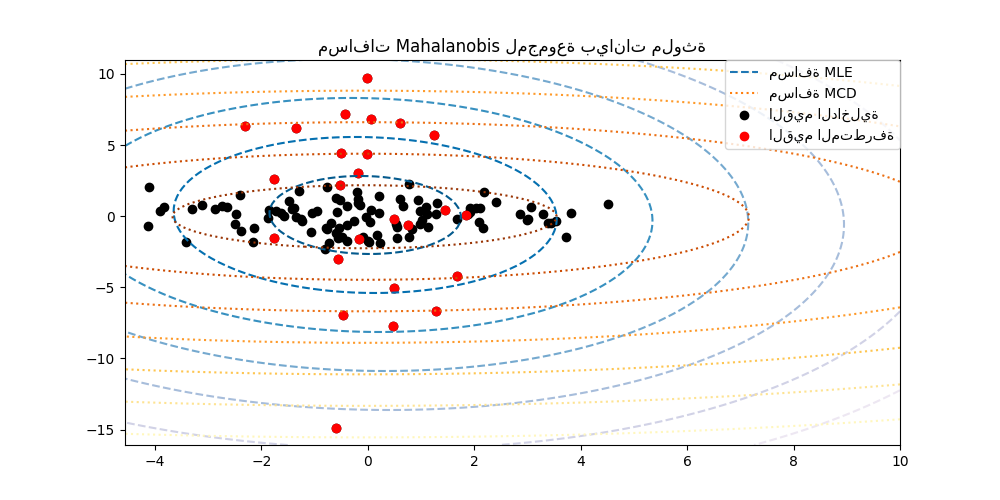
تُوفر scikit-learn كائن covariance.EllipticEnvelope الذي يُناسب تقدير التغاير القوي للبيانات، وبالتالي يُناسب شكل بيضاوي لنقاط البيانات المركزية، متجاهلاً النقاط خارج الوضع المركزي.
على سبيل المثال، بافتراض أن البيانات الداخلية موزعة غاوسيًا، فسيُقدّر الموقع والتغاير الداخلي بطريقة قوية (أي دون التأثر بالقيم المتطرفة). تُستخدم مسافات ماهالانوبيس التي تم الحصول عليها من هذا التقدير لاشتقاق مقياس للبعد. تم توضيح هذه الاستراتيجية أدناه.
أمثلة
انظر تقدير التغاير القوي وأهمية مسافات Mahalanobis لتوضيح الفرق بين استخدام تقدير قياسي (
covariance.EmpiricalCovariance) أو تقدير قوي (covariance.MinCovDet) للموقع والتغاير لتقييم درجة بعد مشاهدة ما.انظر الكشف عن القيم الشاذة في مجموعة بيانات حقيقية للحصول على مثال لتقدير التغاير القوي على مجموعة بيانات حقيقية.
المراجع
Rousseeuw, P.J., Van Driessen, K. "A fast algorithm for the minimum covariance determinant estimator" Technometrics 41(3), 212 (1999)
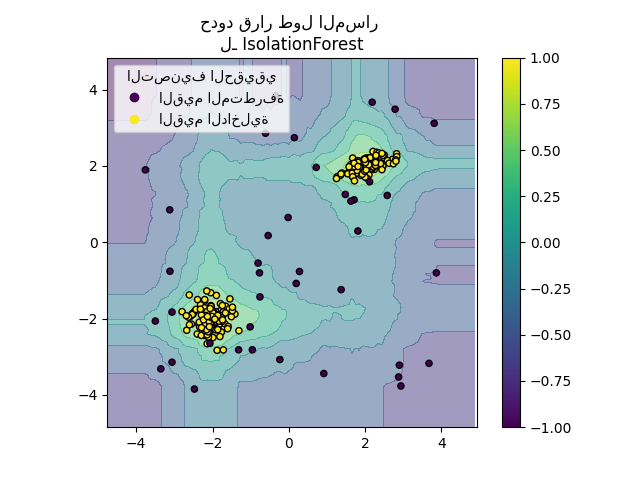
2.7.3.2. غابة العزل#
إحدى الطرق الفعالة لإجراء كشف القيم المتطرفة في مجموعات البيانات عالية الأبعاد هي استخدام الغابات العشوائية. ensemble.IsolationForest "تعزل" المشاهدات عن طريق اختيار ميزة عشوائيًا ثم اختيار قيمة تقسيم عشوائية بين القيم القصوى والدنيا للميزة المختارة.
نظرًا لأنه يمكن تمثيل التقسيم التكراري بهيكل شجرة، فإن عدد عمليات التقسيم المطلوبة لعزل عينة ما يُكافئ طول المسار من العقدة الجذرية إلى العقدة النهائية.
طول المسار هذا، بمتوسط على غابة من هذه الأشجار العشوائية، هو مقياس للطبيعية ودالة القرار لدينا.
يُنتج التقسيم العشوائي مسارات أقصر بشكل ملحوظ للشذوذ. ومن ثم، عندما تُنتج غابة من الأشجار العشوائية بشكل جماعي أطوال مسار أقصر لعينات مُحدّدة، فمن المُرجّح جدًا أن تكون شذوذًا.
يعتمد تطبيق ensemble.IsolationForest على مجموعة من tree.ExtraTreeRegressor. باتباع الورقة الأصلية لغابة العزل، يتم تعيين أقصى عمق لكل شجرة إلى \(\lceil \log_2(n) \rceil\) حيث \(n\) هو عدد العينات المستخدمة لبناء الشجرة (انظر (Liu et al.، 2008) لمزيد من التفاصيل).
تم توضيح هذه الخوارزمية أدناه.
يدعم ensemble.IsolationForest warm_start=True مما يسمح لك بإضافة المزيد من الأشجار إلى نموذج مُناسب بالفعل:
>>> from sklearn.ensemble import IsolationForest
>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [0, 0], [-20, 50], [3, 5]])
>>> clf = IsolationForest(n_estimators=10, warm_start=True)
>>> clf.fit(X) # تناسب 10 أشجار
>>> clf.set_params(n_estimators=20) # أضف 10 أشجار أخرى
>>> clf.fit(X) # تناسب الأشجار المُضافة
أمثلة
انظر مثال IsolationForest لتوضيح استخدام IsolationForest.
انظر مقارنة خوارزميات الكشف عن الشذوذ لكشف القيم المتطرفة في مجموعات بيانات تجريبية لمقارنة
ensemble.IsolationForestمعneighbors.LocalOutlierFactorوsvm.OneClassSVM(مُضبوطة لأداء مثل طريقة كشف القيم المتطرفة) وlinear_model.SGDOneClassSVMوكشف القيم المتطرفة القائم على التغاير معcovariance.EllipticEnvelope.
المراجع
Liu, Fei Tony, Ting, Kai Ming and Zhou, Zhi-Hua. "Isolation forest." Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on.
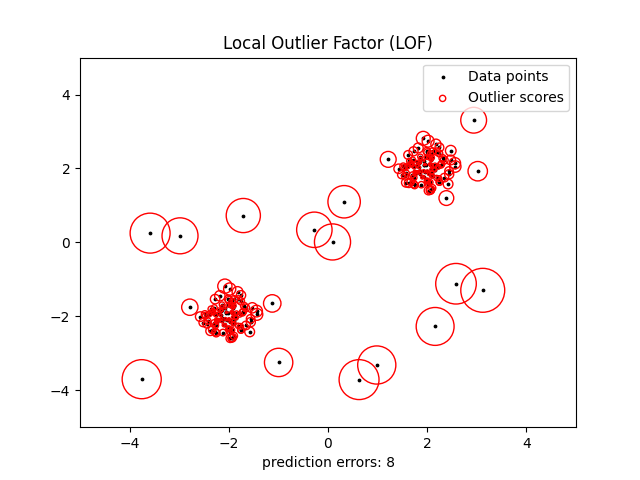
2.7.3.3. مُعامل القيم المتطرفة المحلي#
هناك طريقة أخرى فعالة لإجراء كشف القيم المتطرفة على مجموعات البيانات ذات الأبعاد المعتدلة هي استخدام خوارزمية مُعامل القيم المتطرفة المحلي (LOF).
تحسب خوارزمية neighbors.LocalOutlierFactor (LOF) درجة (تُسمى مُعامل القيم المتطرفة المحلي) تعكس درجة شذوذ المشاهدات. يقيس انحراف الكثافة المحلية لنقطة بيانات مُعطاة فيما يتعلق بجيرانها. الفكرة هي اكتشاف العينات ذات كثافة أقل بكثير من جيرانها.
في الممارسة العملية، يتم الحصول على الكثافة المحلية من أقرب k جيران. درجة LOF للمشاهدة تساوي نسبة متوسط الكثافة المحلية لأقرب k جيران لها، وكثافتها المحلية الخاصة: من المتوقع أن يكون للمثيل العادي كثافة محلية تُشبه كثافة جيرانها، بينما من المتوقع أن يكون للبيانات الشاذة كثافة محلية أصغر بكثير.
عادةً ما يتم اختيار عدد k من الجيران الذين تم أخذهم في الاعتبار (المعلمة البديلة n_neighbors) 1) أكبر من الحد الأدنى لعدد الكائنات التي يجب أن تحتويها المجموعة، بحيث يمكن أن تكون الكائنات الأخرى قيمًا متطرفة محلية بالنسبة لهذه المجموعة، و 2) أصغر من الحد الأقصى لعدد الكائنات القريبة التي يمكن أن تكون قيمًا متطرفة محلية. في الممارسة العملية، هذه المعلومات غير متوفرة بشكل عام، ويبدو أن أخذ n_neighbors=20 يعمل بشكل جيد بشكل عام. عندما تكون نسبة القيم المتطرفة عالية (أي أكبر من 10٪، كما في المثال أدناه)، يجب أن تكون n_neighbors أكبر (n_neighbors=35 في المثال أدناه).
تكمن قوة خوارزمية LOF في أنها تأخذ في الاعتبار كل من الخصائص المحلية والعالمية لمجموعات البيانات: يمكنها الأداء الجيد حتى في مجموعات البيانات حيث تحتوي العينات الشاذة على كثافات أساسية مختلفة. السؤال ليس، ما مدى عزلة العينة، ولكن ما مدى عزلتها بالنسبة للحي المحيط.
عند تطبيق LOF لكشف القيم المتطرفة، لا توجد طرق predict و decision_function و score_samples، ولكن فقط طريقة fit_predict. يمكن الوصول إلى درجات شذوذ عينات التدريب من خلال السمة negative_outlier_factor_. لاحظ أنه يمكن استخدام predict و decision_function و score_samples على بيانات جديدة غير مرئية عند تطبيق LOF لكشف القيم الغريبة، أي عندما يتم تعيين المعلمة novelty إلى True، ولكن قد تختلف نتيجة predict عن نتيجة fit_predict. انظر كشف القيم الغريبة باستخدام مُعامل القيم المتطرفة المحلي.
تم توضيح هذه الاستراتيجية أدناه.
أمثلة
انظر الكشف عن القيم الشاذة باستخدام عامل الانحراف المحلي (LOF) لتوضيح استخدام
neighbors.LocalOutlierFactor.انظر مقارنة خوارزميات الكشف عن الشذوذ لكشف القيم المتطرفة في مجموعات بيانات تجريبية لمقارنة مع طرق كشف الشذوذ الأخرى.
المراجع
Breunig, Kriegel, Ng, and Sander (2000) LOF: identifying density-based local outliers. Proc. ACM SIGMOD
2.7.4. كشف القيم الغريبة باستخدام مُعامل القيم المتطرفة المحلي#
لاستخدام neighbors.LocalOutlierFactor لكشف القيم الغريبة، أي التنبؤ بالتسميات أو حساب درجة شذوذ البيانات الجديدة غير المرئية، تحتاج إلى إنشاء مثيل للمقدر باستخدام المعلمة novelty المُعيّنة إلى True قبل ملاءمة المقدّر:
lof = LocalOutlierFactor(novelty=True)
lof.fit(X_train)
لاحظ أن fit_predict غير متوفرة في هذه الحالة لتجنب التناقضات.
تحذير
كشف القيم الغريبة باستخدام مُعامل القيم المتطرفة المحلي
عندما يتم تعيين novelty إلى True، انتبه إلى أنه يجب عليك فقط استخدام predict و decision_function و score_samples على البيانات الجديدة غير المرئية وليس على عينات التدريب، لأن هذا سيؤدي إلى نتائج خاطئة. بمعنى آخر، لن تكون نتيجة predict هي نفس نتيجة fit_predict. يمكن دائمًا الوصول إلى درجات شذوذ عينات التدريب من خلال السمة negative_outlier_factor_.
يتم توضيح كشف القيم الغريبة باستخدام مُعامل القيم المتطرفة المحلي أدناه.