1.16. معايرة الاحتمال#
عند إجراء التصنيف، غالبًا ما ترغب ليس فقط في التنبؤ بتسمية الفئة، ولكن أيضًا الحصول على احتمال التسمية المعنية.
يمنحك هذا الاحتمال نوعًا من الثقة في التنبؤ. يمكن أن تمنحك بعض النماذج تقديرات ضعيفة لاحتمالات الفئة، وبعضها لا يدعم حتى التنبؤ بالاحتمال (على سبيل المثال، بعض مثيلات SGDClassifier).
تسمح لك وحدة المعايرة بمعايرة احتمالات نموذج معين بشكل أفضل، أو لإضافة دعم للتنبؤ بالاحتمال.
المصنفات المعايرة جيدًا هي مصنفات احتمالية يمكن تفسير ناتج طريقة predict_proba مباشرةً على أنه مستوى ثقة. على سبيل المثال، يجب على المصنف (الثنائي) المعاير جيدًا تصنيف العينات بحيث يكون من بين العينات التي أعطاها قيمة predict_proba قريبة من، على سبيل المثال، 0.8، حوالي 80٪ تنتمي فعليًا إلى الفئة الإيجابية.
قبل أن نوضح كيفية إعادة معايرة المصنف، نحتاج أولاً إلى طريقة لاكتشاف مدى جودة معايرة المصنف.
ملاحظة
تقيم قواعد التسجيل الصارمة للتنبؤات الاحتمالية مثل
sklearn.metrics.brier_score_loss و
sklearn.metrics.log_loss معايرة (الموثوقية) وقوة التمييز (الدقة) للنموذج، بالإضافة إلى عشوائية البيانات (عدم اليقين) في نفس الوقت.
يتبع هذا تحلل Brier score المعروف لـ Murphy [1].
نظرًا لأنه ليس من الواضح أي مصطلح هو السائد، فإن النتيجة محدودة الاستخدام لتقييم المعايرة وحدها (ما لم يحسب المرء كل مصطلح من التحلل).
لا تعني خسارة Brier المنخفضة، على سبيل المثال، بالضرورة نموذجًا معايرًا بشكل أفضل، بل يمكن أن تعني أيضًا نموذجًا معايرًا بشكل أسوأ مع قدرة تمييزية أكبر بكثير، على سبيل المثال باستخدام ميزات أكثر بكثير.
1.16.1. منحنيات المعايرة#
تقارن منحنيات المعايرة، والتي يشار إليها أيضًا باسم مخططات الموثوقية (Wilks 1995 [2] )، مدى جودة معايرة التنبؤات الاحتمالية لمصنف ثنائي. ترسم تردد التسمية الإيجابية (على وجه الدقة، تقدير احتمال الحدث الشرطي \(P(Y=1|\text{predict_proba})\)) على المحور ص مقابل الاحتمال المتوقع predict_proba للنموذج على المحور س. الجزء الصعب هو الحصول على قيم للمحور ص. في scikit-learn، يتم إنجاز ذلك عن طريق تجميع التنبؤات بحيث يمثل المحور س متوسط الاحتمال المتوقع في كل حاوية. المحور ص هو إذن جزء من الإيجابيات بالنظر إلى تنبؤات تلك الحاوية، أي نسبة العينات التي تكون فئتها هي الفئة الإيجابية (في كل حاوية).
يتم إنشاء مخطط منحنى المعايرة العلوي باستخدام
CalibrationDisplay.from_estimator، الذي يستخدم calibration_curve لحساب متوسط الاحتمالات المتوقعة لكل حاوية وجزء من الإيجابيات.
CalibrationDisplay.from_estimator يأخذ كمدخل مصنفًا مناسبًا، والذي يستخدم لحساب الاحتمالات المتوقعة.
وبالتالي يجب أن يكون لدى المصنف طريقة predict_proba.
بالنسبة للمصنفات القليلة التي ليس لديها طريقة predict_proba، من الممكن استخدام CalibratedClassifierCV لمعايرة مخرجات المصنف إلى احتمالات.
يوفر الرسم البياني السفلي بعض المعلومات حول سلوك كل مصنف من خلال إظهار عدد العينات في كل حاوية احتمالية متوقعة.
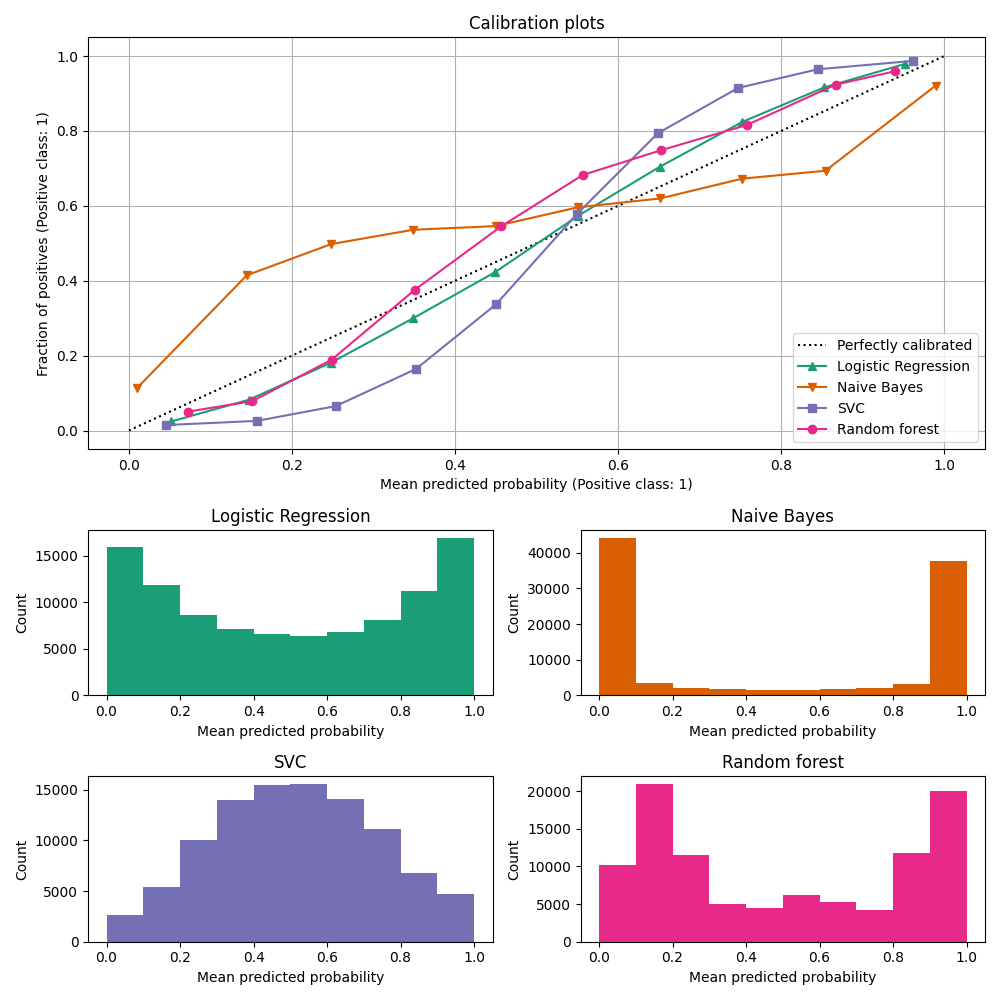
LogisticRegression هو أكثر عرضة لإرجاع تنبؤات معايرة جيدًا من تلقاء نفسه لأنه يحتوي على دالة ربط أساسية لخسارته، أي رابط logit لـ خسارة السجل.
في الحالة غير المعاقبة، يؤدي هذا إلى ما يسمى خاصية التوازن، انظر [8] و الانحدار اللوجستي.
في الرسم البياني أعلاه، يتم إنشاء البيانات وفقًا لآلية خطية، والتي تتوافق مع نموذج LogisticRegression (النموذج "محدد جيدًا")، ويتم ضبط قيمة معلمة التنظيم C لتكون مناسبة (لا قوية جدًا ولا منخفضة جدًا).
ونتيجة لذلك، يُرجع هذا النموذج تنبؤات دقيقة من طريقة predict_proba.
على عكس ذلك، تُرجع النماذج الأخرى المعروضة احتمالات متحيزة؛ مع تحيزات مختلفة لكل نموذج.
يميل GaussianNB (Naive Bayes) إلى دفع الاحتمالات إلى 0 أو 1 (لاحظ الأعداد في الرسوم البيانية).
ويرجع ذلك أساسًا إلى أنه يفترض أن الميزات مستقلة بشكل مشروط بالنظر إلى الفئة، وهو ما لا يحدث في مجموعة البيانات هذه التي تحتوي على ميزتين متكررتين.
يُظهر RandomForestClassifier السلوك المعاكس: تُظهر الرسوم البيانية قممًا عند الاحتمالات تقريبًا 0.2 و 0.9، بينما تكون الاحتمالات القريبة من 0 أو 1 نادرة جدًا.
تم تقديم تفسير لذلك من قبل Niculescu-Mizil و Caruana [3]: "
قد تواجه الطرق مثل التعبئة والغابات العشوائية التي تقوم بمتوسط التنبؤات من مجموعة أساسية من النماذج صعوبة في إجراء تنبؤات بالقرب من 0 و 1 لأن التباين في النماذج الأساسية الكامنة سيؤدي إلى تحيز التنبؤات التي يجب أن تكون قريبة من الصفر أو واحدًا بعيدًا عن هذه القيم.
نظرًا لأن التنبؤات مقصورة على الفاصل الزمني [0،1]، فإن الأخطاء الناتجة عن التباين تميل إلى أن تكون من جانب واحد بالقرب من الصفر والواحد.
على سبيل المثال، إذا كان يجب أن يتنبأ النموذج بـ p = 0 لحالة ما، فإن الطريقة الوحيدة التي يمكن أن تحقق بها الحقيبة ذلك هي إذا تنبأت جميع الأشجار المعبأة بالصفر.
إذا أضفنا ضوضاء إلى الأشجار التي تقوم الحقيبة بمتوسطها، فستتسبب هذه الضوضاء في توقع بعض الأشجار قيمًا أكبر من 0 لهذه الحالة، وبالتالي تحريك متوسط توقع المجموعة المعبأة بعيدًا عن 0.
نلاحظ هذا التأثير بقوة أكبر مع الغابات العشوائية لأن الأشجار ذات المستوى الأساسي المدربة باستخدام الغابات العشوائية لها تباين مرتفع نسبيًا بسبب تجميع الميزات الفرعية.
"
ونتيجة لذلك، يُظهر منحنى المعايرة شكلًا سينيًا مميزًا، مما يشير إلى أن المصنف يمكنه الوثوق بـ "حدسه" أكثر وإرجاع احتمالات أقرب إلى 0 أو 1 عادةً.
يُظهر LinearSVC (SVC) منحنى سيني أكثر من الغابة العشوائية، وهو أمر نموذجي لطرق الهامش الأقصى (قارن Niculescu-Mizil و Caruana [3] )، والتي تركز على العينات التي يصعب تصنيفها والتي تكون قريبة من حدود القرار (متجهات الدعم).
1.16.2. معايرة المصنف#
تتكون معايرة المصنف من ملاءمة عامل انحدار (يُسمى المعاير) يرسم ناتج المصنف (كما هو موضح بواسطة decision_function أو predict_proba) إلى احتمال معاير في [0، 1]. بالإشارة إلى ناتج المصنف لعينة معينة بواسطة \(f_i\)، يحاول المعاير التنبؤ باحتمال الحدث الشرطي \(P(y_i = 1 | f_i)\).
من الناحية المثالية، يتم ملاءمة المعاير على مجموعة بيانات مستقلة عن بيانات التدريب المستخدمة لملاءمة المصنف في المقام الأول. ويرجع ذلك إلى أن أداء المصنف على بيانات التدريب الخاصة به سيكون أفضل من البيانات الجديدة. وبالتالي، سيؤدي استخدام ناتج المصنف لبيانات التدريب لملاءمة المعاير إلى معاير متحيز يرسم إلى احتمالات أقرب إلى 0 و 1 مما ينبغي.
1.16.3. الاستخدام#
يتم استخدام فئة CalibratedClassifierCV لمعايرة المصنف.
يستخدم CalibratedClassifierCV نهج التحقق المتبادل لضمان استخدام البيانات غير المتحيزة دائمًا لملاءمة المعاير.
يتم تقسيم البيانات إلى أزواج k (train_set، test_set) (كما هو محدد بواسطة cv).
عندما يكون ensemble=True (افتراضيًا)، يتم تكرار الإجراء التالي بشكل مستقل لكل تقسيم للتحقق المتبادل:
يتم تدريب نسخة من
base_estimatorعلى مجموعة التدريب الفرعيةيقوم
base_estimatorالمدرب بإجراء تنبؤات على مجموعة الاختبار الفرعيةيتم استخدام التنبؤات لملاءمة معاير (إما عامل انحدار سيني أو متساوي التوتر) (عندما تكون البيانات متعددة الفئات، يتم ملاءمة معاير لكل فئة)
ينتج عن هذا مجموعة من أزواج k (classifier، calibrator) حيث يرسم كل معاير ناتج المصنف المقابل له إلى [0، 1].
يتم عرض كل زوج في سمة calibrated_classifiers_، حيث يكون كل إدخال عبارة عن مصنف معاير باستخدام طريقة predict_proba التي تُخرج احتمالات معايرة.
يتوافق ناتج predict_proba لمثيل CalibratedClassifierCV الرئيسي مع متوسط الاحتمالات المتوقعة لـ k مقدرات في قائمة calibrated_classifiers_.
ناتج predict هو الفئة التي لها أعلى احتمال.
من المهم اختيار cv بعناية عند استخدام ensemble=True.
يجب أن تكون جميع الفئات موجودة في كل من مجموعات التدريب والاختبار الفرعية لكل تقسيم.
عندما تكون الفئة غائبة في مجموعة التدريب الفرعية، فسيتم تعيين الاحتمال المتوقع لتلك الفئة افتراضيًا على 0 لزوج (classifier، calibrator) لهذا التقسيم.
هذا يشوه predict_proba لأنه متوسط عبر جميع الأزواج.
عندما تكون الفئة غائبة في مجموعة الاختبار الفرعية، يتم ملاءمة المعاير لتلك الفئة (ضمن زوج (classifier، calibrator) لهذا التقسيم) على البيانات التي لا تحتوي على فئة إيجابية. هذا يؤدي إلى معايرة غير فعالة.
عندما يكون ensemble=False، يتم استخدام التحقق المتبادل للحصول على تنبؤات "غير متحيزة" لجميع البيانات، عبر cross_val_predict.
ثم يتم استخدام هذه التنبؤات غير المتحيزة لتدريب المعاير.
تتكون سمة calibrated_classifiers_ من زوج واحد فقط (classifier، calibrator) حيث يكون المصنف هو base_estimator المدرب على جميع البيانات.
في هذه الحالة، يكون ناتج predict_proba لـ CalibratedClassifierCV هو الاحتمالات المتوقعة التي تم الحصول عليها من زوج (classifier، calibrator) الفردي.
الميزة الرئيسية لـ ensemble=True هي الاستفادة من تأثير التجميع التقليدي (على غرار مُقدِّر التعريف التجميعي).
يجب أن تكون المجموعة الناتجة معايرة جيدًا وأكثر دقة قليلاً من ensemble=False.
الميزة الرئيسية لاستخدام ensemble=False هي الحسابية: فهي تقلل من وقت الملاءمة الإجمالي عن طريق تدريب مصنف أساسي واحد فقط وزوج معاير، وتقليل حجم النموذج النهائي وزيادة سرعة التنبؤ.
بدلاً من ذلك، يمكن معايرة مصنف مناسب بالفعل عن طريق تعيين cv="prefit".
في هذه الحالة، لا يتم تقسيم البيانات ويتم استخدامها جميعًا لملاءمة عامل الانحدار.
الأمر متروك للمستخدم للتأكد من أن البيانات المستخدمة لملاءمة المصنف منفصلة عن البيانات المستخدمة لملاءمة عامل الانحدار.
يدعم CalibratedClassifierCV استخدام تقنيتين للانحدار للمعايرة عبر معلمة method: "sigmoid" و "isotonic".
1.16.3.1. سيجمويد#
يعتمد عامل الانحدار السيني، method="sigmoid" على نموذج Platt اللوجستي [4]:
حيث \(y_i\) هي التسمية الحقيقية للعينة \(i\) و \(f_i\) هو ناتج المصنف غير المعاير للعينة \(i\). \(A\) و \(B\) هما عددان حقيقيان يتم تحديدهما عند ملاءمة عامل الانحدار عبر أقصى احتمال.
تفترض الطريقة السينية أن منحنى المعايرة يمكن تصحيحه عن طريق تطبيق دالة سينية على التنبؤات الأولية. تم تبرير هذا الافتراض تجريبيًا في حالة آلات الدعم المتجهية (SVM) مع وظائف النواة الشائعة على مجموعات بيانات مرجعية مختلفة في القسم 2.1 من Platt 999 [4] ولكنه لا يصمد بالضرورة بشكل عام. بالإضافة إلى ذلك، يعمل النموذج اللوجستي بشكل أفضل إذا كان خطأ المعايرة متماثلًا، مما يعني أن ناتج المصنف لكل فئة ثنائية يتم توزيعه بشكل طبيعي بنفس التباين [7]. يمكن أن تكون هذه مشكلة لمشاكل التصنيف غير المتوازنة للغاية، حيث لا يكون للمخرجات تباين متساوٍ.
بشكل عام، تكون هذه الطريقة أكثر فاعلية لأحجام العينات الصغيرة أو عندما يكون النموذج غير المعاير غير واثق من نفسه ولديه أخطاء معايرة مماثلة لكل من المخرجات العالية والمنخفضة.
1.16.3.2. متساوي التوتر#
تناسب method="isotonic" عامل انحدار متساوي التوتر غير حدودي، والذي يُخرج دالة غير متناقصة خطوة بخطوة، انظر sklearn.isotonic. يقلل من:
رهنا بـ \(\hat{f}_i \geq \hat{f}_j\) كلما \(f_i \geq f_j\). \(y_i\) هو الحقيقة تسمية العينة \(i\) و \(\hat{f}_i\) هو ناتج المصنف المعاير للعينة \(i\) (أي الاحتمال المعاير). تعتبر هذه الطريقة أكثر عمومية عند مقارنتها بـ "sigmoid" حيث أن القيد الوحيد هو أن دالة التعيين تتزايد بشكل رتيب. وبالتالي فهي أكثر قوة لأنها يمكن أن تصحح أي تشويه رتيب للنموذج غير المعاير. ومع ذلك، فهي أكثر عرضة للإفراط في التجهيز، خاصة في مجموعات البيانات الصغيرة [6].
بشكل عام، سيؤدي "isotonic" أداءً جيدًا مثل أو أفضل من "sigmoid" عندما تكون هناك بيانات كافية (أكبر من ~ 1000 عينة) لتجنب الإفراط في التجهيز [3].
ملاحظة
التأثير على مقاييس الترتيب مثل AUC
من المتوقع عمومًا أن المعايرة لا تؤثر على مقاييس الترتيب مثل ROC-AUC.
ومع ذلك، قد تختلف هذه المقاييس بعد المعايرة عند استخدام method="isotonic" نظرًا لأن الانحدار المتساوي التوتر يقدم روابط في الاحتمالات المتوقعة.
يمكن اعتبار هذا ضمن عدم اليقين في تنبؤات النموذج.
في حالة رغبتك في الحفاظ على الترتيب وبالتالي درجات AUC، استخدم method="sigmoid" وهو تحويل رتيب تمامًا وبالتالي يحافظ على الترتيب.
1.16.3.3. دعم متعدد الفئات#
يدعم كل من عوامل الانحدار المتساوية التوتر والسينية البيانات أحادية البعد فقط (على سبيل المثال، إخراج التصنيف الثنائي) ولكن يتم تمديدها لتصنيف متعدد الفئات إذا كان base_estimator يدعم التنبؤات متعددة الفئات.
بالنسبة للتنبؤات متعددة الفئات، يقوم CalibratedClassifierCV بالمعايرة لكل فئة على حدة بطريقة OneVsRestClassifier [5].
عند التنبؤ بالاحتمالات، يتم توقع الاحتمالات المعايرة لكل فئة بشكل منفصل.
نظرًا لأن هذه الاحتمالات لا تصل بالضرورة إلى واحد، يتم إجراء معالجة لاحقة لتطبيعها.
أمثلة
sphx_glr_auto_examples_calibration/plot_calibration_curve.py
sphx_glr_auto_examples_calibration/plot_calibration_multiclass.py
sphx_glr_auto_examples_calibration/plot_calibration.py
sphx_glr_auto_examples_calibration/plot_compare_calibration.py
المراجع