3.2. ضبط المعلمات الفائقة لمُقدِّر#
المعلمات الفائقة هي معلمات لا يتم تعلمها مباشرةً داخل المُقدِّرات.
في scikit-learn، يتم تمريرها كوسائط إلى مُنشئ
فئات المُقدِّر. تتضمن الأمثلة النموذجية C و kernel و gamma
لـ مُصنف متجه الدعم، alpha لـ Lasso، إلخ.
من الممكن والمُوصى به البحث في مساحة المعلمات الفائقة عن أفضل درجة تحقق متبادل.
يمكن تحسين أي معلمة مُقدمة عند إنشاء مُقدِّر بهذه الطريقة. على وجه التحديد، للعثور على الأسماء والقيم الحالية لجميع المعلمات لمُقدِّر مُعين، استخدم:
estimator.get_params()
يتكون البحث من:
مُقدِّر (مُنحدِر أو مُصنف مثل
sklearn.svm.SVC())؛مساحة معلمات؛
أسلوب للبحث أو أخذ عينات من المُرشحين؛
مخطط تحقق متبادل؛ و
دالة درجة.
يتم توفير نهجين عامين للبحث عن المعلمات في
scikit-learn: بالنسبة لقيم مُعطاة، GridSearchCV يأخذ في الاعتبار
جميع مجموعات المعلمات بشكل شامل، بينما RandomizedSearchCV يمكنه أخذ عينات
من عدد مُعين من المُرشحين من مساحة معلمات بتوزيع
مُحدد. كلتا هاتين الأداتين لهما نظائر مُتتالية للنصف
HalvingGridSearchCV و HalvingRandomSearchCV، والتي يمكن
أن تكون أسرع بكثير في إيجاد مجموعة معلمات جيدة.
بعد وصف هذه الأدوات، نُفصِّل أفضل الممارسات المطبقة على هذه الأساليب. تسمح بعض النماذج بـ استراتيجيات بحث مُتخصصة وفعالة للمعلمات، موضحة في بدائل للبحث الشامل عن المعلمات.
لاحظ أنه من الشائع أن يكون لمجموعة فرعية صغيرة من هذه المعلمات تأثير كبير على أداء التنبؤ أو الحساب للنموذج بينما يمكن ترك الآخرين إلى قيمهم الافتراضية. يُوصى بقراءة سلسلة docstring لـ فئة المُقدِّر للحصول على فهم أدق لسلوكها المُتوقع، ربما عن طريق قراءة المرجع المُرفق للأدبيات.
3.2.1. بحث الشبكة الشامل#
البحث الشبكي الذي يُوفره GridSearchCV يُولِّد
المُرشحين بشكل شامل من شبكة من قيم المعلمات المُحددة باستخدام معلمة param_grid.
على سبيل المثال، param_grid التالي:
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
]
يُحدد أنه يجب استكشاف شبكتين: واحدة بنواة خطية و قيم C في [1، 10، 100، 1000]، والثانية بنواة RBF، وحاصل ضرب قيم C التي تتراوح من [1، 10، 100، 1000] وقيم gamma في [0.001، 0.0001].
يُطبق مثيل GridSearchCV واجهة برمجة تطبيقات المُقدِّر المعتادة: عند
"ملاءمته" على مجموعة بيانات، يتم تقييم جميع مجموعات قيم المعلمات
المُمكنة ويتم الاحتفاظ بأفضل مجموعة.
أمثلة
انظر استراتيجية إعادة الضبط المخصصة للبحث الشبكي مع التحقق المتقاطع للحصول على مثال على حساب البحث الشبكي على مجموعة بيانات الأرقام.
انظر مثال على خط أنابيب لاستخراج ميزات النص وتقييمها للحصول على مثال على معلمات اقتران البحث الشبكي من مُستخرج ميزات مستندات نصية (متجه عدد n-gram ومُحوِّل TF-IDF) مع مُصنف (هنا SVM خطي مُدرَّب باستخدام SGD مع إما شبكة مرنة أو عقوبة L2) باستخدام مثيل
Pipeline.انظر التصنيف المتداخل مقابل غير المتداخل للحصول على مثال على البحث الشبكي داخل حلقة تحقق متبادل على مجموعة بيانات iris. هذه هي أفضل ممارسة لتقييم أداء نموذج باستخدام البحث الشبكي.
انظر توضيح التقييم متعدد المقاييس على cross_val_score و GridSearchCV للحصول على مثال على استخدام
GridSearchCVلتقييم عدة مقاييس في وقت واحد.انظر الموازنة بين تعقيد النموذج ودرجة الدقة عبر التحقق المتقاطع للحصول على مثال على استخدام واجهة
refit=callableفيGridSearchCV. يُظهر المثال كيف تُضيف هذه الواجهة قدرًا مُعينًا من المرونة في تحديد "أفضل" مُقدِّر. يمكن أيضًا استخدام هذه الواجهة في تقييم المقاييس المتعددة.انظر المقارنة الإحصائية للنماذج باستخدام البحث الشبكي للحصول على مثال عن كيفية إجراء مقارنة إحصائية على مخرجات
GridSearchCV.
3.2.2. تحسين المعلمات العشوائي#
بينما يُعد استخدام شبكة من إعدادات المعلمات حاليًا الأسلوب الأكثر استخدامًا
لتحسين المعلمات، فإن أساليب البحث الأخرى لها
خصائص أكثر ملاءمة.
RandomizedSearchCV يُطبق بحثًا عشوائيًا على المعلمات،
حيث يتم أخذ عينات من كل إعداد من توزيع على قيم المعلمات
المُمكنة.
هذا له ميزتان رئيسيتان على البحث الشامل:
يمكن اختيار ميزانية مستقلة عن عدد المعلمات والقيم المُمكنة.
لا يؤدي إضافة معلمات لا تؤثر على الأداء إلى تقليل الكفاءة.
يتم تحديد كيفية أخذ عينات من المعلمات باستخدام قاموس، مُشابه جدًا
لتحديد المعلمات لـ GridSearchCV. بالإضافة إلى ذلك،
يتم تحديد ميزانية الحساب، وهي عدد المُرشحين الذين تم أخذ عينات منهم أو تكرارات
أخذ العينات، باستخدام معلمة n_iter.
لكل معلمة، يمكن تحديد إما توزيع على القيم المُمكنة أو قائمة
باختيارات منفصلة (سيتم أخذ عينات منها بشكل مُوحد):
{'C': scipy.stats.expon(scale=100), 'gamma': scipy.stats.expon(scale=.1),
'kernel': ['rbf'], 'class_weight':['balanced', None]}
يستخدم هذا المثال وحدة scipy.stats، التي تحتوي على العديد من التوزيعات
المفيدة لأخذ عينات من المعلمات، مثل expon و gamma
و uniform و loguniform أو randint.
من حيث المبدأ، يمكن تمرير أي دالة تُوفر أسلوب rvs (عينة متغير
عشوائي) لأخذ عينة من قيمة. يجب أن يُوفر استدعاء دالة rvs
عينات عشوائية مستقلة من قيم المعلمات المُمكنة على
استدعاءات مُتتالية.
تحذير
لا تسمح التوزيعات في scipy.stats قبل الإصدار scipy 0.16
بتحديد حالة عشوائية. بدلاً من ذلك، يستخدمون حالة
numpy العشوائية العامة، والتي يمكن زرعها عبر np.random.seed أو تعيينها
باستخدام np.random.set_state. ومع ذلك، بدءًا من scikit-learn 0.18،
تُعيِّن وحدة sklearn.model_selection الحالة العشوائية التي يُوفرها
المستخدم إذا كان scipy >= 0.16 مُتاحًا أيضًا.
بالنسبة للمعلمات المُستمرة، مثل C أعلاه، من المهم تحديد
توزيع مُستمر للاستفادة الكاملة من العشوائية. بهذه الطريقة،
ستؤدي زيادة n_iter دائمًا إلى بحث أدق.
متغير عشوائي لوغاريتمي مُستمر مُوحد هو الإصدار المُستمر لـ
معلمة مُتباعدة لوغاريتميًا. على سبيل المثال، لتحديد ما يُعادل C من أعلى،
يمكن استخدام loguniform(1, 100) بدلاً من [1, 10, 100].
بمُحاكاة المثال أعلاه في البحث الشبكي، يمكننا تحديد متغير عشوائي مُستمر
موزع بشكل لوغاريتمي مُوحد بين 1e0 و 1e3:
from sklearn.utils.fixes import loguniform
{'C': loguniform(1e0, 1e3),
'gamma': loguniform(1e-4, 1e-3),
'kernel': ['rbf'],
'class_weight':['balanced', None]}
أمثلة
مقارنة البحث العشوائي والبحث الشبكي لتقدير فرط المعلمات تُقارن استخدام وكفاءة البحث العشوائي والبحث الشبكي.
المراجع
Bergstra, J. and Bengio, Y., البحث العشوائي لتحسين المعلمات الفائقة, The Journal of Machine Learning Research (2012)
3.2.3. البحث عن المعلمات المثلى مع النصف المُتتالي#
يُوفر Scikit-learn أيضًا مُقدِّري HalvingGridSearchCV و
HalvingRandomSearchCV اللذين يمكن استخدامهما لـ
البحث في مساحة المعلمات باستخدام النصف المُتتالي [1] [2]. النصف
المُتتالي (SH) يشبه دورة بين مجموعات المعلمات المُرشحة.
SH هو عملية اختيار متكررة حيث يتم تقييم جميع المُرشحين (مجموعات
المعلمات) بكمية صغيرة من الموارد في
التكرار الأول. يتم تحديد بعض هؤلاء المُرشحين فقط للتكرار التالي،
والذي سيتم تخصيص المزيد من الموارد له. بالنسبة لضبط المعلمات،
يكون المورد عادةً هو عدد عينات التدريب، ولكن يمكن أيضًا أن يكون
معلمة عددية عشوائية مثل n_estimators في غابة عشوائية.
ملاحظة
يجب أن تكون زيادة الموارد المختارة كبيرة بما يكفي بحيث يتم الحصول على تحسين كبير في الدرجات عند الأخذ في الاعتبار الأهمية الإحصائية.
كما هو موضح في الشكل أدناه، فإن مجموعة فرعية فقط من المُرشحين "تبقى" حتى التكرار الأخير. هؤلاء هم المُرشحون الذين احتلت مرتبة ثابتة بين المُرشحين ذوي الدرجات العالية عبر جميع التكرارات. يتم تخصيص قدر متزايد من الموارد لكل مُرشح لكل تكرار، هنا عدد العينات.
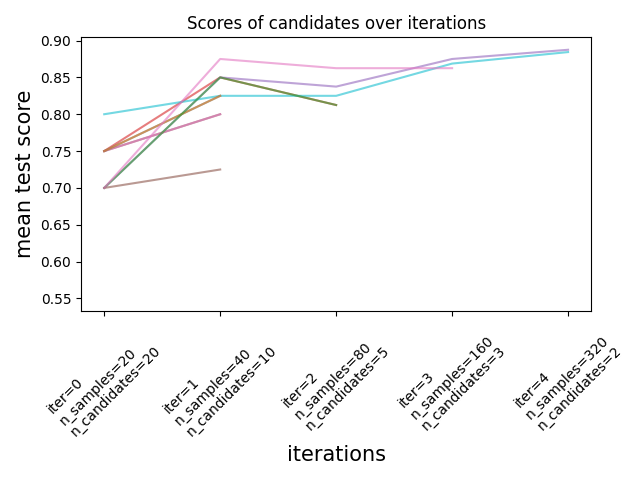
نصف هنا بإيجاز المعلمات الرئيسية، ولكن يتم وصف كل معلمة
وتفاعلاتها بمزيد من التفصيل في الأقسام أدناه.
تتحكم معلمة factor (> 1) في المعدل الذي تنمو به الموارد، و
المعدل الذي يتناقص به عدد المرشحين. في كل تكرار،
يتم ضرب عدد الموارد لكل مرشح في factor ويتم قسمة عدد
المرشحين على نفس العامل. جنبًا إلى جنب مع resource و
min_resources، factor هي أهم معلمة للتحكم في
البحث في تطبيقنا، على الرغم من أن القيمة 3 تعمل عادةً بشكل جيد.
factor تتحكم بشكل فعال في عدد التكرارات في
HalvingGridSearchCV وعدد المرشحين (افتراضيًا) و
التكرارات في HalvingRandomSearchCV. يمكن أيضًا استخدام
aggressive_elimination=True إذا كان عدد الموارد المتاحة صغيرًا. يتوفر المزيد من التحكم
من خلال ضبط معلمة min_resources.
لا يزال هذان المُقدِّران تجريبيين: تنبؤاتهما
وواجهة برمجة التطبيقات الخاصة بهما قد تتغير دون أي دورة إهمال. لاستخدامهما، تحتاج
إلى استيراد enable_halving_search_cv صراحة:
>>> # طلب هذه الميزة التجريبية صراحة
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> # الآن يمكنك الاستيراد بشكل طبيعي من model_selection
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> from sklearn.model_selection import HalvingRandomSearchCV
أمثلة
3.2.3.1. اختيار min_resources وعدد المرشحين#
بجانب factor، المعلمتان الرئيسيتان اللتان تؤثران على سلوك
بحث النصف المتتالي هما معلمة min_resources، و
عدد المرشحين (أو مجموعات المعلمات) التي يتم تقييمها.
min_resources هو مقدار الموارد المخصصة في التكرار الأول
لكل مرشح. يتم تحديد عدد المرشحين مباشرةً
في HalvingRandomSearchCV، ويتم تحديده من معلمة param_grid
لـ HalvingGridSearchCV.
ضع في اعتبارك حالة يكون فيها المورد هو عدد العينات، وحيث
لدينا 1000 عينة. من الناحية النظرية، مع min_resources=10 و factor=2،
نحن قادرون على تشغيل 7 تكرارات على الأكثر بالعدد التالي من
العينات: [10, 20, 40, 80, 160, 320, 640].
ولكن اعتمادًا على عدد المرشحين، قد نُجري أقل من 7
تكرارات: إذا بدأنا بعدد صغير من المرشحين، فإن التكرار
الأخير قد يستخدم أقل من 640 عينة، مما يعني عدم استخدام جميع الموارد
المتاحة (العينات). على سبيل المثال، إذا بدأنا بـ 5 مرشحين، فإننا نحتاج
إلى تكرارين فقط: 5 مرشحين للتكرار الأول، ثم
5 // 2 = 2 مرشحين في التكرار الثاني، وبعد ذلك نعرف أي
مرشح يؤدي بشكل أفضل (لذا لا نحتاج إلى مرشح ثالث). سنستخدم فقط
20 عينة على الأكثر وهو إهدار لأن لدينا 1000 عينة تحت تصرفنا.
من ناحية أخرى، إذا بدأنا بعدد كبير من
المرشحين، فقد ينتهي بنا الأمر بالكثير من المرشحين في التكرار الأخير،
وهو ما قد لا يكون مثاليًا دائمًا: فهذا يعني أن العديد من المرشحين سيعملون
بالموارد الكاملة، مما يُقلل بشكل أساسي الإجراء إلى بحث قياسي.
في حالة HalvingRandomSearchCV، يتم تعيين عدد المرشحين
افتراضيًا بحيث يستخدم التكرار الأخير أكبر قدر ممكن من الموارد
المتاحة. بالنسبة لـ HalvingGridSearchCV، يتم تحديد عدد
المرشحين بواسطة معلمة param_grid. سيؤثر تغيير قيمة
min_resources على عدد التكرارات الممكنة، ونتيجة لذلك
سيكون له أيضًا تأثير على العدد المثالي للمرشحين.
اعتبار آخر عند اختيار min_resources هو ما إذا كان
من السهل التمييز بين المرشحين الجيدين والسيئين بكمية صغيرة من
الموارد. على سبيل المثال، إذا كنت بحاجة إلى الكثير من العينات للتمييز
بين المعلمات الجيدة والسيئة، فيُوصى باستخدام min_resources عالية. من
ناحية أخرى، إذا كان التمييز واضحًا حتى مع كمية صغيرة من
العينات، فقد يكون min_resources صغيرًا مُفضلًا لأنه
سيُسرِّع الحساب.
لاحظ في المثال أعلاه أن التكرار الأخير لا يستخدم الحد الأقصى
لمقدار الموارد المتاحة: 1000 عينة متاحة، ومع ذلك يتم استخدام 640 فقط،
على الأكثر. افتراضيًا، يحاول كل من HalvingRandomSearchCV و
HalvingGridSearchCV استخدام أكبر قدر ممكن من الموارد في
التكرار الأخير، بشرط أن يكون مقدار الموارد هذا
مُضاعفًا لكل من min_resources و factor (سيكون هذا القيد واضحًا
في القسم التالي). HalvingRandomSearchCV يُحقق ذلك عن طريق
أخذ عينات من الكمية المناسبة من المرشحين، بينما HalvingGridSearchCV
يُحقق ذلك عن طريق تعيين min_resources بشكل صحيح. يرجى مراجعة
استنفاد الموارد المتاحة للتفاصيل.
3.2.3.2. مقدار الموارد وعدد المرشحين في كل تكرار#
في أي تكرار i، يتم تخصيص مقدار مُعين من الموارد لكل مرشح
والذي نُشير إليه بـ n_resources_i. يتم التحكم في هذه الكمية بواسطة
المعلمات factor و min_resources على النحو التالي (factor أكبر
تمامًا من 1):
n_resources_i = factor**i * min_resources,
أو بشكل مُكافئ:
n_resources_{i+1} = n_resources_i * factor
حيث min_resources == n_resources_0 هو مقدار الموارد المُستخدمة في
التكرار الأول. تُحدد factor أيضًا نسب المرشحين
الذين سيتم اختيارهم للتكرار التالي:
n_candidates_i = n_candidates // (factor ** i)
أو بشكل مُكافئ:
n_candidates_0 = n_candidates
n_candidates_{i+1} = n_candidates_i // factor
لذا في التكرار الأول، نستخدم موارد min_resources
n_candidates مرة. في التكرار الثاني، نستخدم موارد min_resources *
factor n_candidates // factor مرة. يضاعف الثالث مرة أخرى
الموارد لكل مرشح ويقسم عدد المرشحين.
تتوقف هذه العملية عندما يتم الوصول إلى الحد الأقصى لمقدار الموارد لكل مرشح،
أو عندما نُحدد أفضل مرشح. يتم تحديد أفضل مرشح
في التكرار الذي يُقيِّم factor أو أقل من المرشحين
(انظر أدناه مباشرةً للحصول على تفسير).
فيما يلي مثال مع min_resources=3 و factor=2، بدءًا من
70 مرشحًا:
|
|
|---|---|
3 (=min_resources) |
70 (=n_candidates) |
3 * 2 = 6 |
70 // 2 = 35 |
6 * 2 = 12 |
35 // 2 = 17 |
12 * 2 = 24 |
17 // 2 = 8 |
24 * 2 = 48 |
8 // 2 = 4 |
48 * 2 = 96 |
4 // 2 = 2 |
يمكننا ملاحظة ما يلي:
تتوقف العملية عند التكرار الأول الذي يُقيِّم
factor=2مرشحًا: أفضل مرشح هو الأفضل من بين هذين المرشحين. ليس من الضروري إجراء تكرار إضافي، لأنه سيُقيِّم مرشحًا واحدًا فقط (وهو الأفضل، الذي حددناه بالفعل). لهذا السبب، بشكل عام، نُريد أن يُجري التكرار الأخيرfactorمرشحًا على الأكثر. إذا كان التكرار الأخير يُقيِّم أكثر منfactorمرشحين، فإن هذا التكرار الأخير يُختصر إلى بحث منتظم (كما فيRandomizedSearchCVأوGridSearchCV).كل
n_resources_iهو مُضاعف لكل منfactorوmin_resources(وهو ما تؤكده تعريفه أعلاه).
يمكن العثور على مقدار الموارد المُستخدمة في كل تكرار في
السمة n_resources_.
3.2.3.3. اختيار مورد#
افتراضيًا، يتم تعريف المورد من حيث عدد العينات. أي،
سيستخدم كل تكرار عددًا متزايدًا من العينات للتدريب عليها. يمكنك
مع ذلك تحديد معلمة يدويًا لاستخدامها كمورد باستخدام
معلمة resource. فيما يلي مثال حيث يتم تعريف المورد من حيث عدد مُقدِّرات
غابة عشوائية:
>>> from sklearn.datasets import make_classification
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>>
>>> param_grid = {'max_depth': [3, 5, 10],
... 'min_samples_split': [2, 5, 10]}
>>> base_estimator = RandomForestClassifier(random_state=0)
>>> X, y = make_classification(n_samples=1000, random_state=0)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, resource='n_estimators',
... max_resources=30).fit(X, y)
>>> sh.best_estimator_
RandomForestClassifier(max_depth=5, n_estimators=24, random_state=0)
لاحظ أنه ليس من الممكن وضع ميزانية على معلمة هي جزء من شبكة المعلمات.
3.2.3.4. استنفاد الموارد المتاحة#
كما ذُكر أعلاه، يعتمد عدد الموارد المُستخدمة في كل تكرار
على معلمة min_resources.
إذا كان لديك الكثير من الموارد المتاحة ولكنك تبدأ بعدد قليل من
الموارد، فقد يتم إهدار بعضها (أي عدم استخدامه):
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>> param_grid= {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources=20).fit(X, y)
>>> sh.n_resources_
[20, 40, 80]
ستستخدم عملية البحث 80 موردًا فقط على الأكثر، بينما الحد الأقصى
لمقدار الموارد المتاحة لدينا هو n_samples=1000. هنا، لدينا
min_resources = r_0 = 20.
بالنسبة لـ HalvingGridSearchCV، افتراضيًا، يتم تعيين معلمة min_resources
إلى "exhaust". هذا يعني أنه يتم تعيين min_resources تلقائيًا
بحيث يمكن للتكرار الأخير استخدام أكبر قدر ممكن من الموارد، ضمن
حد max_resources:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, min_resources='exhaust').fit(X, y)
>>> sh.n_resources_
[250, 500, 1000]
تم تعيين min_resources هنا تلقائيًا إلى 250، مما يؤدي إلى استخدام التكرار
الأخير لجميع الموارد. تعتمد القيمة الدقيقة المُستخدمة على
عدد معلمات المرشح، و max_resources و factor.
بالنسبة لـ HalvingRandomSearchCV، يمكن استنفاد الموارد بطريقتين:
عن طريق تعيين
min_resources='exhaust'، تمامًا كما هو الحال بالنسبة لـHalvingGridSearchCV؛عن طريق تعيين
n_candidates='exhaust'.
كلا الخيارين مُتبادلان للاستبعاد: استخدام min_resources='exhaust' يتطلب
معرفة عدد المرشحين، وبشكل متماثل n_candidates='exhaust'
يتطلب معرفة min_resources.
بشكل عام، يؤدي استنفاد العدد الإجمالي للموارد إلى معلمة مرشح نهائية أفضل، ويكون أكثر كثافة زمنية قليلاً.
3.2.3.5. الإزالة العدوانية للمرشحين#
من الناحية المثالية، نُريد أن يُقيِّم التكرار الأخير factor مرشحين (انظر
مقدار الموارد وعدد المرشحين في كل تكرار). علينا بعد ذلك فقط
اختيار الأفضل. عندما يكون عدد الموارد المتاحة صغيرًا بالنسبة
لعدد المرشحين، قد يضطر التكرار الأخير إلى تقييم
أكثر من factor مرشحين:
>>> from sklearn.datasets import make_classification
>>> from sklearn.svm import SVC
>>> from sklearn.experimental import enable_halving_search_cv # noqa
>>> from sklearn.model_selection import HalvingGridSearchCV
>>> import pandas as pd
>>>
>>>
>>> param_grid = {'kernel': ('linear', 'rbf'),
... 'C': [1, 10, 100]}
>>> base_estimator = SVC(gamma='scale')
>>> X, y = make_classification(n_samples=1000)
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2, max_resources=40,
... aggressive_elimination=False).fit(X, y)
>>> sh.n_resources_
[20, 40]
>>> sh.n_candidates_
[6, 3]
نظرًا لأنه لا يمكننا استخدام أكثر من max_resources=40 موردًا، فإن العملية
يجب أن تتوقف عند التكرار الثاني الذي يُقيِّم أكثر من factor=2
مرشحين.
باستخدام معلمة aggressive_elimination، يمكنك إجبار عملية البحث
على الانتهاء بأقل من factor مرشحين في التكرار
الأخير. للقيام بذلك، ستُزيل العملية أكبر عدد ممكن من المرشحين
باستخدام موارد min_resources:
>>> sh = HalvingGridSearchCV(base_estimator, param_grid, cv=5,
... factor=2,
... max_resources=40,
... aggressive_elimination=True,
... ).fit(X, y)
>>> sh.n_resources_
[20, 20, 40]
>>> sh.n_candidates_
[6, 3, 2]
لاحظ أننا انتهينا بمرشحين في التكرار الأخير لأننا
أزلنا عددًا كافيًا من المرشحين خلال التكرارات الأولى، باستخدام n_resources =
min_resources = 20.
3.2.3.6. تحليل النتائج باستخدام سمة cv_results_#
تحتوي سمة cv_results_ على معلومات مفيدة لتحليل
نتائج البحث. يمكن تحويلها إلى إطار بيانات pandas باستخدام df =
pd.DataFrame(est.cv_results_). تشبه سمة cv_results_ لـ
HalvingGridSearchCV و HalvingRandomSearchCV
سمة GridSearchCV و RandomizedSearchCV، مع
معلومات إضافية متعلقة بعملية النصف المتتالي.
فيما يلي مثال على بعض أعمدة إطار بيانات (مُقتطع):
iter |
n_resources |
mean_test_score |
params |
|
|---|---|---|---|---|
0 |
0 |
125 |
0.983667 |
{'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 5} |
1 |
0 |
125 |
0.983667 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 8, 'min_samples_split': 7} |
2 |
0 |
125 |
0.983667 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10} |
3 |
0 |
125 |
0.983667 |
{'criterion': 'log_loss', 'max_depth': None, 'max_features': 6, 'min_samples_split': 6} |
... |
... |
... |
... |
... |
15 |
2 |
500 |
0.951958 |
{'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10} |
16 |
2 |
500 |
0.947958 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10} |
17 |
2 |
500 |
0.951958 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 4} |
18 |
3 |
1000 |
0.961009 |
{'criterion': 'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10} |
19 |
3 |
1000 |
0.955989 |
{'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 4} |
يتوافق كل صف مع مجموعة معلمات مُعينة (مرشح) وتكرار مُعين.
يتم إعطاء التكرار بواسطة عمود iter. يُخبرك عمود n_resources
بعدد الموارد التي تم استخدامها.
في المثال أعلاه، أفضل مجموعة معلمات هي {'criterion':
'log_loss', 'max_depth': None, 'max_features': 9, 'min_samples_split': 10}
لأنها وصلت إلى التكرار الأخير (3) بأعلى درجة:
0.96.
المراجع
3.2.4. نصائح للبحث عن المعلمات#
3.2.4.1. تحديد مقياس هدف#
افتراضيًا، يستخدم بحث المعلمات دالة score للمُقدِّر
لتقييم إعداد معلمة. هذه هي
sklearn.metrics.accuracy_score للتصنيف و
sklearn.metrics.r2_score للانحدار. بالنسبة لبعض التطبيقات،
تكون دوال التسجيل الأخرى أكثر ملاءمة (على سبيل المثال، في التصنيف غير
المتوازن، غالبًا ما تكون درجة الدقة غير مفيدة). يمكن تحديد
دالة تسجيل بديلة عبر معلمة scoring لمعظم
أدوات بحث المعلمات. انظر معلمة scoring: تعريف قواعد تقييم النموذج لمزيد من التفاصيل.
3.2.4.2. تحديد مقاييس متعددة للتقييم#
يسمح GridSearchCV و RandomizedSearchCV بتحديد
مقاييس متعددة لمعلمة scoring.
يمكن تحديد تسجيل المقاييس المتعددة إما كقائمة من سلاسل أسماء الدرجات المُعرفة مسبقًا أو قاموس يُعيِّن اسم المُسجل إلى دالة المُسجل و / أو اسم (أسماء) المُسجل المُعرف مسبقًا. انظر استخدام تقييم متعدد المقاييس لمزيد من التفاصيل.
عند تحديد مقاييس متعددة، يجب تعيين معلمة refit إلى
المقياس (سلسلة) الذي سيتم العثور على best_params_ له واستخدامه لبناء
best_estimator_ على مجموعة البيانات بأكملها. إذا لم يكن البحث
يجب إعادة ملاءمته، فعيِّن refit=False. سيؤدي ترك refit إلى القيمة الافتراضية None
إلى حدوث خطأ عند استخدام مقاييس متعددة.
انظر توضيح التقييم متعدد المقاييس على cross_val_score و GridSearchCV للحصول على مثال على الاستخدام.
HalvingRandomSearchCV و HalvingGridSearchCV لا يدعمان
تسجيل المقاييس المتعددة.
3.2.4.3. مقدرات التركيب ومساحات المعلمات#
يسمح GridSearchCV و RandomizedSearchCV بالبحث على
معلمات مقدرات التركيب أو المتداخلة مثل
Pipeline،
ColumnTransformer،
VotingClassifier أو
CalibratedClassifierCV باستخدام
بناء جملة مُخصص <estimator>__<parameter>:
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.calibration import CalibratedClassifierCV
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_moons
>>> X, y = make_moons()
>>> calibrated_forest = CalibratedClassifierCV(
... estimator=RandomForestClassifier(n_estimators=10))
>>> param_grid = {
... 'estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(calibrated_forest, param_grid, cv=5)
>>> search.fit(X, y)
GridSearchCV(cv=5,
estimator=CalibratedClassifierCV(...),
param_grid={'estimator__max_depth': [2, 4, 6, 8]})
هنا، <estimator> هو اسم معلمة المُقدِّر المتداخل،
في هذه الحالة estimator.
إذا تم إنشاء المُقدِّر التعريفي كمجموعة من المُقدِّرات كما في
pipeline.Pipeline، فإن <estimator> يُشير إلى اسم المُقدِّر،
انظر الوصول إلى المعلمات المتداخلة. في الممارسة العملية، يمكن أن يكون هناك العديد
من مستويات التداخل:
>>> from sklearn.pipeline import Pipeline
>>> from sklearn.feature_selection import SelectKBest
>>> pipe = Pipeline([
... ('select', SelectKBest()),
... ('model', calibrated_forest)])
>>> param_grid = {
... 'select__k': [1, 2],
... 'model__estimator__max_depth': [2, 4, 6, 8]}
>>> search = GridSearchCV(pipe, param_grid, cv=5).fit(X, y)
يرجى الرجوع إلى Pipeline: سلسلة المقدرات لإجراء عمليات بحث عن المعلمات على خطوط الأنابيب.
3.2.4.4. اختيار النموذج: التطوير والتقييم#
يمكن اعتبار اختيار النموذج عن طريق تقييم إعدادات المعلمات المختلفة طريقة لاستخدام البيانات المُصنَّفة لـ "تدريب" معلمات الشبكة.
عند تقييم النموذج الناتج، من المهم القيام بذلك على
عينات مُخصصة للاختبار لم تتم رؤيتها أثناء عملية البحث الشبكي:
يُوصى بتقسيم البيانات إلى مجموعة تطوير (لـ
تغذية مثيل GridSearchCV) و مجموعة تقييم
لحساب مقاييس الأداء.
يمكن القيام بذلك باستخدام دالة الأداة المساعدة train_test_split.
3.2.4.5. التوازي#
تُقيِّم أدوات بحث المعلمات كل مجموعة معلمات على كل طية بيانات
بشكل مستقل. يمكن تشغيل الحسابات بالتوازي باستخدام الكلمة
الرئيسية n_jobs=-1. راجع توقيع الدالة لمزيد من التفاصيل، وكذلك
إدخال المُصطلحات لـ n_jobs.
3.2.4.6. المتانة للفشل#
قد تؤدي بعض إعدادات المعلمات إلى فشل fit طية بيانات واحدة
أو أكثر. افتراضيًا، سيؤدي هذا إلى فشل البحث بأكمله، حتى لو
كان من الممكن تقييم بعض إعدادات المعلمات بالكامل. تعيين error_score=0
(أو =np.nan) سيجعل الإجراء متينًا لمثل هذا الفشل، مع إصدار
تحذير وتعيين درجة تلك الطية إلى 0 (أو nan)، ولكن إكمال
البحث.
3.2.5. بدائل للبحث الشامل عن المعلمات#
3.2.5.1. التحقق المتبادل المُخصص للنموذج#
يمكن لبعض النماذج ملاءمة البيانات لنطاق من قيم بعض المعلمات تقريبًا بنفس كفاءة ملاءمة المُقدِّر لقيمة واحدة من المعلمة. يمكن الاستفادة من هذه الميزة لإجراء تحقق متبادل أكثر كفاءة يُستخدم لاختيار نموذج هذه المعلمة.
المعلمة الأكثر شيوعًا المُوافقة لهذه الإستراتيجية هي المعلمة التي تُرمِّز قوة المُنظِّم. في هذه الحالة، نقول إننا نحسب مسار التنظيم للمُقدِّر.
فيما يلي قائمة بهذه النماذج:
|
Elastic Net model with iterative fitting along a regularization path. |
|
Cross-validated Least Angle Regression model. |
|
Lasso linear model with iterative fitting along a regularization path. |
|
Cross-validated Lasso, using the LARS algorithm. |
|
Logistic Regression CV (aka logit, MaxEnt) classifier. |
|
Multi-task L1/L2 ElasticNet with built-in cross-validation. |
|
Multi-task Lasso model trained with L1/L2 mixed-norm as regularizer. |
Cross-validated Orthogonal Matching Pursuit model (OMP). |
|
|
Ridge regression with built-in cross-validation. |
|
Ridge classifier with built-in cross-validation. |
3.2.5.2. معيار المعلومات#
يمكن لبعض النماذج تقديم صيغة شكل مغلق للمعلومات النظرية لـ التقدير الأمثل لمعلمة التنظيم عن طريق حساب مسار تنظيم واحد (بدلاً من عدة مسارات عند استخدام التحقق المتبادل).
فيما يلي قائمة بالنماذج التي تستفيد من معيار معلومات Akaike (AIC) أو معيار معلومات Bayesian (BIC) لاختيار النموذج التلقائي:
|
Lasso model fit with Lars using BIC or AIC for model selection. |
3.2.5.3. تقديرات خارج الحقيبة#
عند استخدام أساليب المجموعات القائمة على التجميع، أي إنشاء مجموعات تدريب جديدة باستخدام أخذ العينات مع الاستبدال، يظل جزء من مجموعة التدريب غير مُستخدم. لكل مُصنف في المجموعة، يتم ترك جزء مختلف من مجموعة التدريب.
يمكن استخدام هذا الجزء المتروك لتقدير خطأ التعميم دون الحاجة إلى الاعتماد على مجموعة تحقق مُنفصلة. يأتي هذا التقدير "مجانًا" حيث لا توجد حاجة إلى بيانات إضافية ويمكن استخدامه لـ اختيار النموذج.
يتم تطبيق هذا حاليًا في الفئات التالية:
A random forest classifier. |
|
A random forest regressor. |
|
An extra-trees classifier. |
|
|
An extra-trees regressor. |
|
Gradient Boosting for classification. |
|
Gradient Boosting for regression. |