3.5. منحنيات التحقق من الصحة: رسم الدرجات لتقييم النماذج#
لكل مُقدِّر مزايا وعيوب. يمكن تحليل خطأ تعميمه من حيث التحيز والتباين والضوضاء. التحيز للمُقدِّر هو متوسط خطأه لمجموعات التدريب المُختلفة. يُشير التباين للمُقدِّر إلى مدى حساسيته لمجموعات التدريب المُتغيرة. الضوضاء هي خاصية للبيانات.
في الرسم التالي، نرى دالة \(f(x) = \cos (\frac{3}{2} \pi x)\) وبعض العينات الصاخبة من تلك الدالة. نستخدم ثلاثة مُقدِّرات مُختلفة لملاءمة الدالة: الانحدار الخطي مع ميزات متعددة الحدود من الدرجة 1 و 4 و 15. نرى أن المُقدِّر الأول يمكنه في أفضل الأحوال توفير ملاءمة ضعيفة فقط للعينات والدالة الحقيقية لأنه بسيط جدًا (تحيز عالي)، يقوم المُقدِّر الثاني بتقريبه بشكل مثالي تقريبًا ويقوم المُقدِّر الأخير بتقريب بيانات التدريب بشكل مثالي ولكنه لا يُناسب الدالة الحقيقية بشكل جيد للغاية، أي أنه حساس جدًا لتغيير بيانات التدريب (تباين عالي).
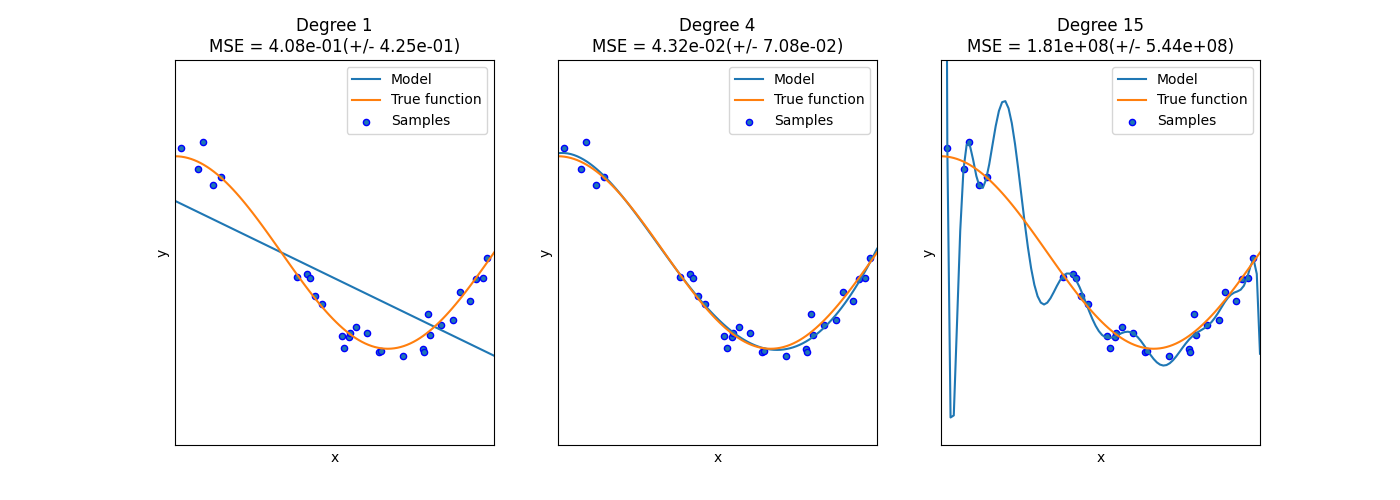
التحيز والتباين هما خصائص متأصلة في المُقدِّرات وعادةً ما يتعين علينا اختيار خوارزميات التعلم والمعلمات الفائقة بحيث يكون كل من التحيز والتباين منخفضين قدر الإمكان (انظر معضلة التحيز والتباين). طريقة أخرى لتقليل تباين النموذج هي استخدام المزيد من بيانات التدريب. ومع ذلك، يجب عليك فقط جمع المزيد من بيانات التدريب إذا كانت الدالة الحقيقية مُعقدة للغاية بحيث لا يمكن تقريبها بواسطة مُقدِّر ذي تباين أقل.
في مشكلة أحادية البعد البسيطة التي رأيناها في المثال، من السهل معرفة ما إذا كان المُقدِّر يُعاني من التحيز أو التباين. ومع ذلك، في المساحات عالية الأبعاد، يمكن أن يصبح تصور النماذج صعبًا للغاية. لـ هذا السبب، غالبًا ما يكون من المفيد استخدام الأدوات الموضحة أدناه.
أمثلة
3.5.1. منحنى التحقق من الصحة#
للتحقق من صحة نموذج، نحتاج إلى دالة تسجيل (انظر المقاييس والتهديف: تحديد جودة التنبؤات)، على سبيل المثال الدقة للمُصنِّفات. الطريقة الصحيحة لاختيار مُتعددة المعلمات الفائقة لمُقدِّر هي بالطبع بحث الشبكة أو أساليب مُشابهة (انظر ضبط المعلمات الفائقة لمُقدِّر) التي تحدد المعلمة الفائقة ذات أعلى درجة على مجموعة تحقق من الصحة أو مجموعات تحقق من الصحة مُتعددة. لاحظ أنه إذا قمنا بتحسين المعلمات الفائقة بناءً على درجة التحقق من الصحة، فإن درجة التحقق من الصحة تكون مُتحيزة وليست تقديرًا جيدًا للتعميم بعد الآن. للحصول على تقدير صحيح للتعميم، يتعين علينا حساب الدرجة على مجموعة اختبار أخرى.
ومع ذلك، من المفيد أحيانًا رسم تأثير معلمة فائقة واحدة على درجة التدريب ودرجة التحقق من الصحة لمعرفة ما إذا كان المُقدِّر يُفرط في الملاءمة أو يُفرط في التعميم لبعض قيم المعلمات الفائقة.
يمكن أن تُساعد دالة validation_curve في هذه الحالة:
>>> import numpy as np
>>> from sklearn.model_selection import validation_curve
>>> from sklearn.datasets import load_iris
>>> from sklearn.svm import SVC
>>> np.random.seed(0)
>>> X, y = load_iris(return_X_y=True)
>>> indices = np.arange(y.shape[0])
>>> np.random.shuffle(indices)
>>> X, y = X[indices], y[indices]
>>> train_scores, valid_scores = validation_curve(
... SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 3),
... )
>>> train_scores
array([[0.90..., 0.94..., 0.91..., 0.89..., 0.92...],
[0.9... , 0.92..., 0.93..., 0.92..., 0.93...],
[0.97..., 1... , 0.98..., 0.97..., 0.99...]])
>>> valid_scores
array([[0.9..., 0.9... , 0.9... , 0.96..., 0.9... ],
[0.9..., 0.83..., 0.96..., 0.96..., 0.93...],
[1.... , 0.93..., 1.... , 1.... , 0.9... ]])
إذا كنت تنوي رسم منحنيات التحقق من الصحة فقط، فإن الفئة
ValidationCurveDisplay تكون أكثر مباشرة من
استخدام matplotlib يدويًا على نتائج استدعاء validation_curve.
يمكنك استخدام الأسلوب
from_estimator بشكل مُماثل
لـ validation_curve لتوليد ورسم منحنى التحقق من الصحة:
from sklearn.datasets import load_iris
from sklearn.model_selection import ValidationCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
ValidationCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, param_name="C", param_range=np.logspace(-7, 3, 10)
)
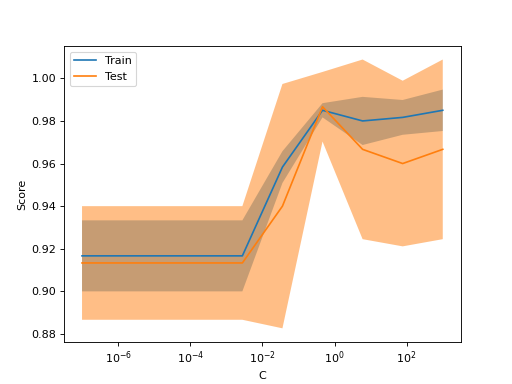
إذا كانت درجة التدريب ودرجة التحقق من الصحة منخفضتين، فسيكون المُقدِّر مُفرطًا في التعميم. إذا كانت درجة التدريب عالية ودرجة التحقق من الصحة منخفضة، فسيكون المُقدِّر مُفرطًا في الملاءمة، وإلا فسيكون يعمل بشكل جيد للغاية. درجة تدريب منخفضة ودرجة تحقق من الصحة عالية عادةً ما تكون غير مُمكنة.
3.5.2. منحنى التعلم#
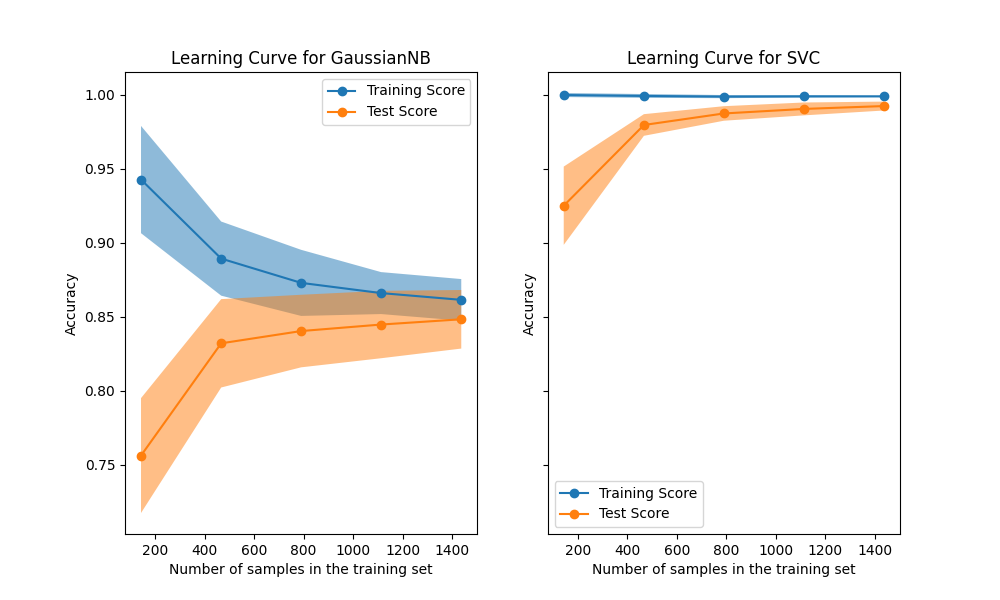
يُظهر منحنى التعلم درجة التحقق من الصحة والتدريب لمُقدِّر لأعداد مُتغيرة من عينات التدريب. إنها أداة لمعرفة مقدار استفادتنا من إضافة المزيد من بيانات التدريب وما إذا كان المُقدِّر يُعاني أكثر من خطأ التباين أو خطأ التحيز. ضع في اعتبارك المثال التالي حيث نرسم منحنى التعلم لمُصنف ساذج بايز و SVM.
بالنسبة لساذج بايز، تتقارب كل من درجة التحقق من الصحة ودرجة التدريب إلى قيمة منخفضة تمامًا مع زيادة حجم مجموعة التدريب. وبالتالي، ربما لن نستفيد كثيرًا من المزيد من بيانات التدريب.
على النقيض من ذلك، بالنسبة للكميات الصغيرة من البيانات، تكون درجة تدريب SVM أكبر بكثير من درجة التحقق من الصحة. من المُرجح أن تؤدي إضافة المزيد من عينات التدريب إلى زيادة التعميم.
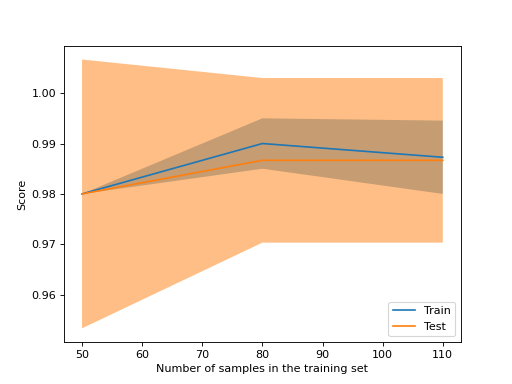
يمكننا استخدام دالة learning_curve لتوليد القيم
المطلوبة لرسم منحنى تعلم كهذا (عدد العينات
التي تم استخدامها، ومتوسط الدرجات على مجموعات التدريب، و
متوسط الدرجات على مجموعات التحقق من الصحة):
>>> from sklearn.model_selection import learning_curve
>>> from sklearn.svm import SVC
>>> train_sizes, train_scores, valid_scores = learning_curve(
... SVC(kernel='linear'), X, y, train_sizes=[50, 80, 110], cv=5)
>>> train_sizes
array([ 50, 80, 110])
>>> train_scores
array([[0.98..., 0.98 , 0.98..., 0.98..., 0.98...],
[0.98..., 1. , 0.98..., 0.98..., 0.98...],
[0.98..., 1. , 0.98..., 0.98..., 0.99...]])
>>> valid_scores
array([[1. , 0.93..., 1. , 1. , 0.96...],
[1. , 0.96..., 1. , 1. , 0.96...],
[1. , 0.96..., 1. , 1. , 0.96...]])
إذا كنت تنوي رسم منحنيات التعلم فقط، فإن الفئة
LearningCurveDisplay ستكون أسهل في الاستخدام.
يمكنك استخدام الأسلوب
from_estimator بشكل مُماثل
لـ learning_curve لتوليد ورسم منحنى التعلم:
from sklearn.datasets import load_iris
from sklearn.model_selection import LearningCurveDisplay
from sklearn.svm import SVC
from sklearn.utils import shuffle
X, y = load_iris(return_X_y=True)
X, y = shuffle(X, y, random_state=0)
LearningCurveDisplay.from_estimator(
SVC(kernel="linear"), X, y, train_sizes=[50, 80, 110], cv=5)
أمثلة
انظر رسم منحنيات التعلم وفحص قابلية التوسع للنماذج لـ مثال على استخدام منحنيات التعلم للتحقق من قابلية توسيع نطاق نموذج تنبؤي.