ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
توضيح التقييم متعدد المقاييس على cross_val_score و GridSearchCV#
يمكن إجراء البحث عن معلمات المقاييس المتعددة عن طريق ضبط معلمة "scoring" إلى قائمة من أسماء المقاييس أو قاموس يقوم بربط أسماء المقاييس بـ callable المقاييس.
تتوفر درجات جميع المقاييس في قاموس "cv_results_" عند المفاتيح التي تنتهي بـ "'<اسم_المقياس>'" ('mean_test_precision'، 'rank_test_precision'، إلخ...)
تتوافق "best_estimator_"، "best_index_"، "best_score_" و "best_params_" مع المقياس (المفتاح) الذي يتم ضبطه على خاصية "refit".
# المؤلفون: مطوري scikit-learn
# معرف الرخصة: BSD-3-Clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_hastie_10_2
from sklearn.metrics import accuracy_score, make_scorer
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
تشغيل GridSearchCV باستخدام مقاييس تقييم متعددة#
X, y = make_hastie_10_2(n_samples=8000, random_state=42)
# يمكن أن تكون المقاييس إما واحدة من سلاسل المقاييس المحددة مسبقًا أو callable مقياس،
# مثل تلك التي يتم إرجاعها بواسطة make_scorer
scoring = {"AUC": "roc_auc", "Accuracy": make_scorer(accuracy_score)}
# ضبط refit='AUC'، يعيد ضبط المقياس على مجموعة البيانات الكاملة باستخدام
# إعداد المعلمات الذي يحتوي على أفضل درجة AUC عبر التحقق من الصحة.
# يتم توفير المقياس مع "gs.best_estimator_" إلى جانب
# المعلمات مثل "gs.best_score_"، "gs.best_params_" و
# "gs.best_index_"
gs = GridSearchCV(
DecisionTreeClassifier(random_state=42),
param_grid={"min_samples_split": range(2, 403, 20)},
scoring=scoring,
refit="AUC",
n_jobs=2,
return_train_score=True,
)
gs.fit(X, y)
results = gs.cv_results_
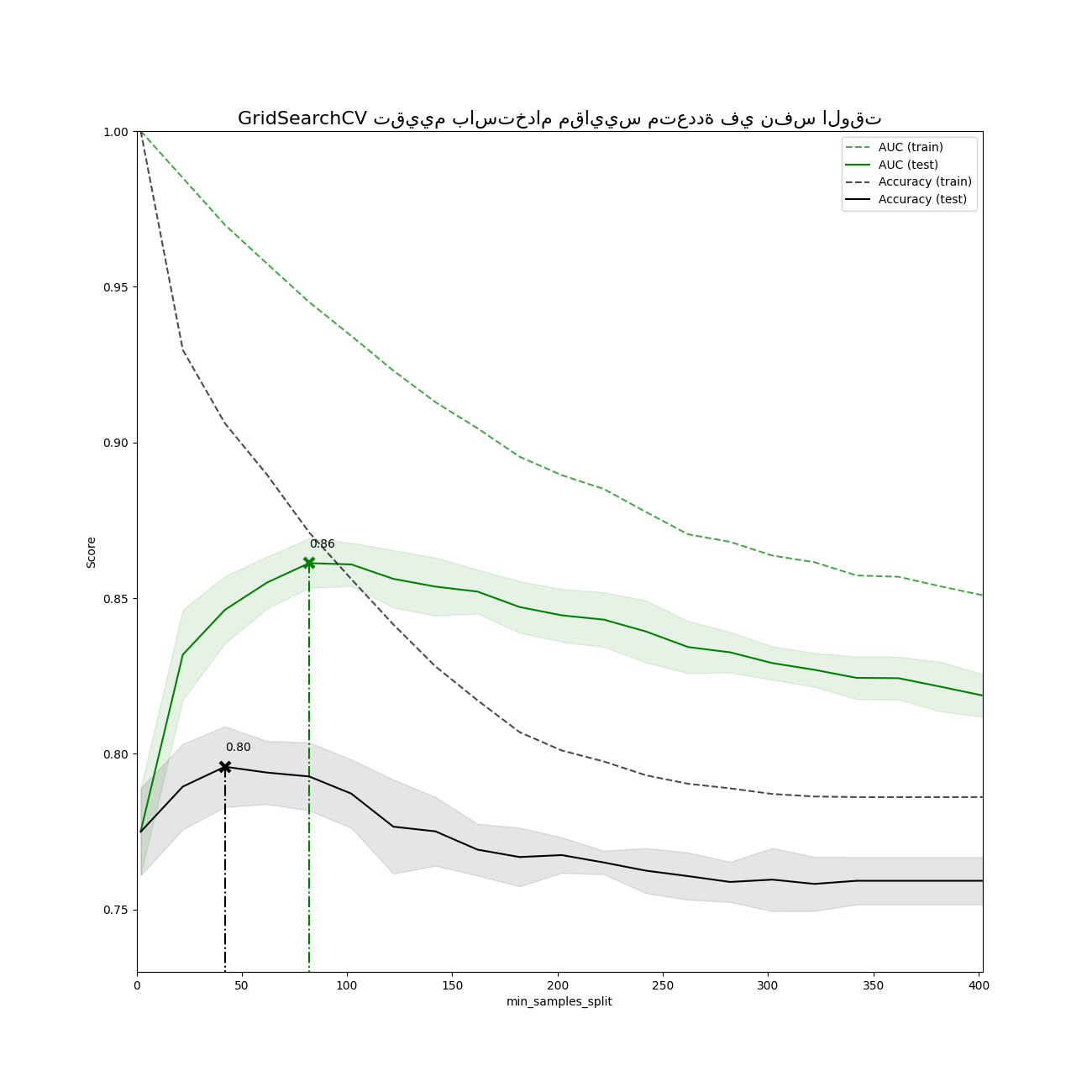
رسم النتائج#
plt.figure(figsize=(13, 13))
plt.title("GridSearchCV تقييم باستخدام مقاييس متعددة في نفس الوقت", fontsize=16)
plt.xlabel("min_samples_split")
plt.ylabel("Score")
ax = plt.gca()
ax.set_xlim(0, 402)
ax.set_ylim(0.73, 1)
# الحصول على مصفوفة numpy العادية من MaskedArray
X_axis = np.array(results["param_min_samples_split"].data, dtype=float)
for scorer, color in zip(sorted(scoring), ["g", "k"]):
for sample, style in (("train", "--"), ("test", "-")):
sample_score_mean = results["mean_%s_%s" % (sample, scorer)]
sample_score_std = results["std_%s_%s" % (sample, scorer)]
ax.fill_between(
X_axis,
sample_score_mean - sample_score_std,
sample_score_mean + sample_score_std,
alpha=0.1 if sample == "test" else 0,
color=color,
)
ax.plot(
X_axis,
sample_score_mean,
style,
color=color,
alpha=1 if sample == "test" else 0.7,
label="%s (%s)" % (scorer, sample),
)
best_index = np.nonzero(results["rank_test_%s" % scorer] == 1)[0][0]
best_score = results["mean_test_%s" % scorer][best_index]
# رسم خط عمودي منقط عند أفضل درجة لذلك المقياس مع علامة x
ax.plot(
[
X_axis[best_index],
]
* 2,
[0, best_score],
linestyle="-.",
color=color,
marker="x",
markeredgewidth=3,
ms=8,
)
# إضافة ملاحظة لأفضل درجة لذلك المقياس
ax.annotate("%0.2f" % best_score, (X_axis[best_index], best_score + 0.005))
plt.legend(loc="best")
plt.grid(False)
plt.show()
Total running time of the script: (0 minutes 9.787 seconds)
Related examples

مقارنة البحث العشوائي والبحث الشبكي لتقدير فرط المعلمات
مقارنة البحث العشوائي والبحث الشبكي لتقدير فرط المعلمات