ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
استراتيجية إعادة الضبط المخصصة للبحث الشبكي مع التحقق المتقاطع#
يُظهر هذا المثال كيفية تحسين التصنيف من خلال التحقق المتقاطع،
والذي يتم باستخدام كائن GridSearchCV
على مجموعة تطوير تتكون من نصف بيانات التصنيف المتاحة فقط.
يتم بعد ذلك قياس أداء المعلمات فائقة التحديد والنموذج المدرب على مجموعة تقييم مخصصة لم يتم استخدامها أثناء خطوة اختيار النموذج.
يمكن العثور على مزيد من التفاصيل حول الأدوات المتاحة لاختيار النموذج في الأقسام الخاصة بـ التحقق المتبادل: تقييم أداء المقدر و ضبط المعلمات الفائقة لمُقدِّر.
# المؤلفون: مطوري scikit-learn
# معرف SPDX-License: BSD-3-Clause
مجموعة البيانات#
سنعمل مع مجموعة بيانات digits. الهدف هو تصنيف صور الأرقام المكتوبة بخط اليد.
نحن نحول المشكلة إلى تصنيف ثنائي من أجل الفهم الأسهل: الهدف هو تحديد ما إذا كان الرقم هو 8 أم لا.
from sklearn import datasets
digits = datasets.load_digits()
من أجل تدريب مصنف على الصور، نحتاج إلى تسطيحها إلى متجهات.
تحتاج كل صورة من 8 بكسل في 8 بكسل إلى تحويلها إلى متجه من 64 بكسل.
وبالتالي، سنحصل على مصفوفة بيانات نهائية ذات شكل (n_images, n_pixels).
n_samples = len(digits.images)
X = digits.images.reshape((n_samples, -1))
y = digits.target == 8
print(
f"عدد الصور هو {X.shape[0]} وتحتوي كل صورة على {X.shape[1]} بكسل"
)
عدد الصور هو 1797 وتحتوي كل صورة على 64 بكسل
كما هو موضح في المقدمة، سيتم تقسيم البيانات إلى مجموعة تدريب ومجموعة اختبار بنفس الحجم.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
تحديد استراتيجية البحث الشبكي#
سنختار مصنفًا من خلال البحث عن أفضل المعلمات فائقة التحديد على طيات مجموعة التدريب. للقيام بذلك، نحتاج إلى تحديد الدرجات لاختيار أفضل مرشح.
scores = ["precision", "recall"]
يمكننا أيضًا تحديد دالة لتمريرها إلى معلمة refit الخاصة بـ
GridSearchCV. ستقوم بتنفيذ
الاستراتيجية المخصصة لاختيار أفضل مرشح من سمة cv_results_
الخاصة بـ GridSearchCV. بمجرد اختيار المرشح،
يتم إعادة ضبطه تلقائيًا بواسطة
GridSearchCV.
هنا، الاستراتيجية هي وضع قائمة مختصرة للنماذج التي تكون الأفضل من حيث الدقة والاستدعاء. من النماذج المختارة، نختار أخيرًا النموذج الأسرع في التنبؤ. لاحظ أن هذه الخيارات المخصصة تعسفية تمامًا.
import pandas as pd
def print_dataframe(filtered_cv_results):
"""طباعة جميلة لمصفوفة البيانات المفلترة"""
for mean_precision, std_precision, mean_recall, std_recall, params in zip(
filtered_cv_results["mean_test_precision"],
filtered_cv_results["std_test_precision"],
filtered_cv_results["mean_test_recall"],
filtered_cv_results["std_test_recall"],
filtered_cv_results["params"],
):
print(
f"الدقة: {mean_precision:0.3f} (±{std_precision:0.03f}),"
f" الاستدعاء: {mean_recall:0.3f} (±{std_recall:0.03f}),"
f" للـ {params}"
)
print()
def refit_strategy(cv_results):
"""تحديد الاستراتيجية لاختيار أفضل مقدر.
الاستراتيجية المحددة هنا هي استبعاد جميع النتائج التي تقل عن عتبة دقة
تبلغ 0.98، وترتيب النتائج المتبقية حسب الاستدعاء والاحتفاظ بجميع النماذج
مع انحراف معياري واحد من الأفضل من حيث الاستدعاء. بمجرد اختيار هذه النماذج،
يمكننا اختيار النموذج الأسرع في التنبؤ.
المعلمات
----------
cv_results : dict of numpy (masked) ndarrays
نتائج CV كما أعادتها `GridSearchCV`.
الإرجاع
-------
best_index : int
فهرس أفضل مقدر كما يظهر في `cv_results`.
"""
# طباعة المعلومات حول البحث الشبكي للدرجات المختلفة
precision_threshold = 0.98
cv_results_ = pd.DataFrame(cv_results)
print("جميع نتائج البحث الشبكي:")
print_dataframe(cv_results_)
# استبعاد جميع النتائج التي تقل عن العتبة
high_precision_cv_results = cv_results_[
cv_results_["mean_test_precision"] > precision_threshold
]
print(f"النماذج ذات الدقة الأعلى من {precision_threshold}:")
print_dataframe(high_precision_cv_results)
high_precision_cv_results = high_precision_cv_results[
[
"mean_score_time",
"mean_test_recall",
"std_test_recall",
"mean_test_precision",
"std_test_precision",
"rank_test_recall",
"rank_test_precision",
"params",
]
]
# اختيار النماذج الأكثر أداءً من حيث الاستدعاء
# (ضمن انحراف معياري واحد من الأفضل)
best_recall_std = high_precision_cv_results["mean_test_recall"].std()
best_recall = high_precision_cv_results["mean_test_recall"].max()
best_recall_threshold = best_recall - best_recall_std
high_recall_cv_results = high_precision_cv_results[
high_precision_cv_results["mean_test_recall"] > best_recall_threshold
]
print(
"من النماذج المختارة ذات الدقة العالية، نحتفظ بجميع\n"
"النماذج ضمن انحراف معياري واحد من النموذج الأعلى استدعاءً:"
)
print_dataframe(high_recall_cv_results)
# من بين أفضل المرشحين، اختيار النموذج الأسرع في التنبؤ
fastest_top_recall_high_precision_index = high_recall_cv_results[
"mean_score_time"
].idxmin()
print(
"\nالنموذج المختار النهائي هو الأسرع في التنبؤ من بين\n"
"المجموعة الفرعية المختارة مسبقًا من أفضل النماذج بناءً على الدقة والاستدعاء.\n"
"وقت تسجيله هو:\n\n"
f"{high_recall_cv_results.loc[fastest_top_recall_high_precision_index]}"
)
return fastest_top_recall_high_precision_index
ضبط المعلمات فائقة التحديد#
بمجرد تحديد استراتيجيتنا لاختيار أفضل نموذج، نقوم بتحديد قيم المعلمات فائقة التحديد وإنشاء مثيل البحث الشبكي:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
tuned_parameters = [
{"kernel": ["rbf"], "gamma": [1e-3, 1e-4], "C": [1, 10, 100, 1000]},
{"kernel": ["linear"], "C": [1, 10, 100, 1000]},
]
grid_search = GridSearchCV(
SVC(), tuned_parameters, scoring=scores, refit=refit_strategy
)
grid_search.fit(X_train, y_train)
جميع نتائج البحث الشبكي:
الدقة: 1.000 (±0.000), الاستدعاء: 0.854 (±0.063), للـ {'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.257 (±0.061), للـ {'C': 1, 'gamma': 0.0001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 0.968 (±0.039), الاستدعاء: 0.780 (±0.083), للـ {'C': 10, 'gamma': 0.0001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 100, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 0.905 (±0.058), الاستدعاء: 0.889 (±0.074), للـ {'C': 100, 'gamma': 0.0001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 1000, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 0.904 (±0.058), الاستدعاء: 0.890 (±0.073), للـ {'C': 1000, 'gamma': 0.0001, 'kernel': 'rbf'}
الدقة: 0.695 (±0.073), الاستدعاء: 0.743 (±0.065), للـ {'C': 1, 'kernel': 'linear'}
الدقة: 0.643 (±0.066), الاستدعاء: 0.757 (±0.066), للـ {'C': 10, 'kernel': 'linear'}
الدقة: 0.611 (±0.028), الاستدعاء: 0.744 (±0.044), للـ {'C': 100, 'kernel': 'linear'}
الدقة: 0.618 (±0.039), الاستدعاء: 0.744 (±0.044), للـ {'C': 1000, 'kernel': 'linear'}
النماذج ذات الدقة الأعلى من 0.98:
الدقة: 1.000 (±0.000), الاستدعاء: 0.854 (±0.063), للـ {'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.257 (±0.061), للـ {'C': 1, 'gamma': 0.0001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 100, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 1000, 'gamma': 0.001, 'kernel': 'rbf'}
من النماذج المختارة ذات الدقة العالية، نحتفظ بجميع
النماذج ضمن انحراف معياري واحد من النموذج الأعلى استدعاءً:
الدقة: 1.000 (±0.000), الاستدعاء: 0.854 (±0.063), للـ {'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 10, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 100, 'gamma': 0.001, 'kernel': 'rbf'}
الدقة: 1.000 (±0.000), الاستدعاء: 0.877 (±0.069), للـ {'C': 1000, 'gamma': 0.001, 'kernel': 'rbf'}
النموذج المختار النهائي هو الأسرع في التنبؤ من بين
المجموعة الفرعية المختارة مسبقًا من أفضل النماذج بناءً على الدقة والاستدعاء.
وقت تسجيله هو:
mean_score_time 0.005914
mean_test_recall 0.853676
std_test_recall 0.063184
mean_test_precision 1.0
std_test_precision 0.0
rank_test_recall 6
rank_test_precision 1
params {'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}
Name: 0, dtype: object
المعلمات التي اختارها البحث الشبكي باستراتيجيتنا المخصصة هي:
grid_search.best_params_
{'C': 1, 'gamma': 0.001, 'kernel': 'rbf'}
أخيرًا، نقوم بتقييم النموذج المضبوط بدقة على مجموعة التقييم المتبقية:
تم إعادة ضبط كائن grid_search تلقائيًا على مجموعة التدريب
الكاملة بالمعلمات التي اختارتها استراتيجية إعادة الضبط المخصصة لدينا.
يمكننا استخدام تقرير التصنيف لحساب مقاييس التصنيف القياسية على المجموعة المتبقية:
from sklearn.metrics import classification_report
y_pred = grid_search.predict(X_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
False 0.98 1.00 0.99 807
True 1.00 0.85 0.92 92
accuracy 0.98 899
macro avg 0.99 0.92 0.95 899
weighted avg 0.98 0.98 0.98 899
ملاحظة
المشكلة سهلة للغاية: هضبة المعلمات فائقة التحديد مسطحة للغاية والنموذج الناتج هو نفسه بالنسبة للدقة والاستدعاء مع تعادلات في الجودة.
Total running time of the script: (0 minutes 9.405 seconds)
Related examples

مقارنة البحث العشوائي والبحث الشبكي لتقدير فرط المعلمات
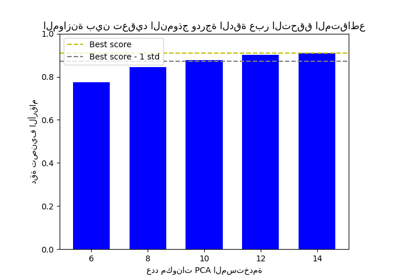
الموازنة بين تعقيد النموذج ودرجة الدقة عبر التحقق المتقاطع

