ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
عمليات التقسيم المتتالية#
يوضح هذا المثال كيف تبحث عملية التقسيم المتتالية (HalvingGridSearchCV و HalvingRandomSearchCV) بشكل تكراري عن أفضل مجموعة من المعلمات من بين العديد من المرشحين.
# المؤلفون: مطوري سكايلرن # معرف الترخيص: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy.stats import randint
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
نحن نحدد أولاً مساحة المعلمات وندرب مثالاً على:
HalvingRandomSearchCV.
rng = np.random.RandomState(0)
X, y = datasets.make_classification(n_samples=400, n_features=12, random_state=rng)
clf = RandomForestClassifier(n_estimators=20, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 6),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
يمكننا الآن استخدام خاصية cv_results_ لمُقدر البحث لفحص وتصوير تطور البحث.
results = pd.DataFrame(rsh.cv_results_)
results["params_str"] = results.params.apply(str)
results.drop_duplicates(subset=("params_str", "iter"), inplace=True)
mean_scores = results.pivot(
index="iter", columns="params_str", values="mean_test_score"
)
ax = mean_scores.plot(legend=False, alpha=0.6)
labels = [
f"iter={i}\nn_samples={rsh.n_resources_[i]}\nn_candidates={rsh.n_candidates_[i]}"
for i in range(rsh.n_iterations_)
]
ax.set_xticks(range(rsh.n_iterations_))
ax.set_xticklabels(labels, rotation=45, multialignment="left")
ax.set_title("Scores of candidates over iterations")
ax.set_ylabel("mean test score", fontsize=15)
ax.set_xlabel("iterations", fontsize=15)
plt.tight_layout()
plt.show()
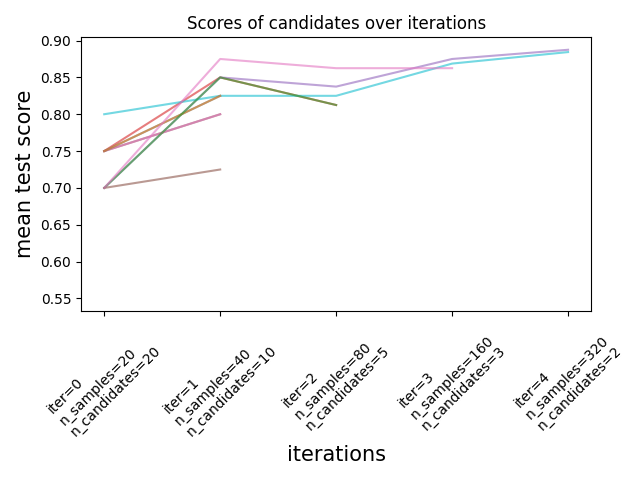
عدد المرشحين وكمية الموارد في كل تكرار#
في التكرار الأول، يتم استخدام كمية صغيرة من الموارد. المورد هنا هو عدد العينات التي يتم تدريب المُقدرات عليها. يتم تقييم جميع المرشحين.
في التكرار الثاني، يتم تقييم نصف أفضل المرشحين فقط. يتم مضاعفة عدد الموارد المخصصة: يتم تقييم المرشحين على ضعف عدد العينات.
تتكرر هذه العملية حتى التكرار الأخير، حيث يتبقى مرشحان فقط. المرشح الأفضل هو المرشح الذي يحصل على أفضل نتيجة في التكرار الأخير.
Total running time of the script: (0 minutes 6.385 seconds)
Related examples

مقارنة البحث العشوائي والبحث الشبكي لتقدير فرط المعلمات