ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
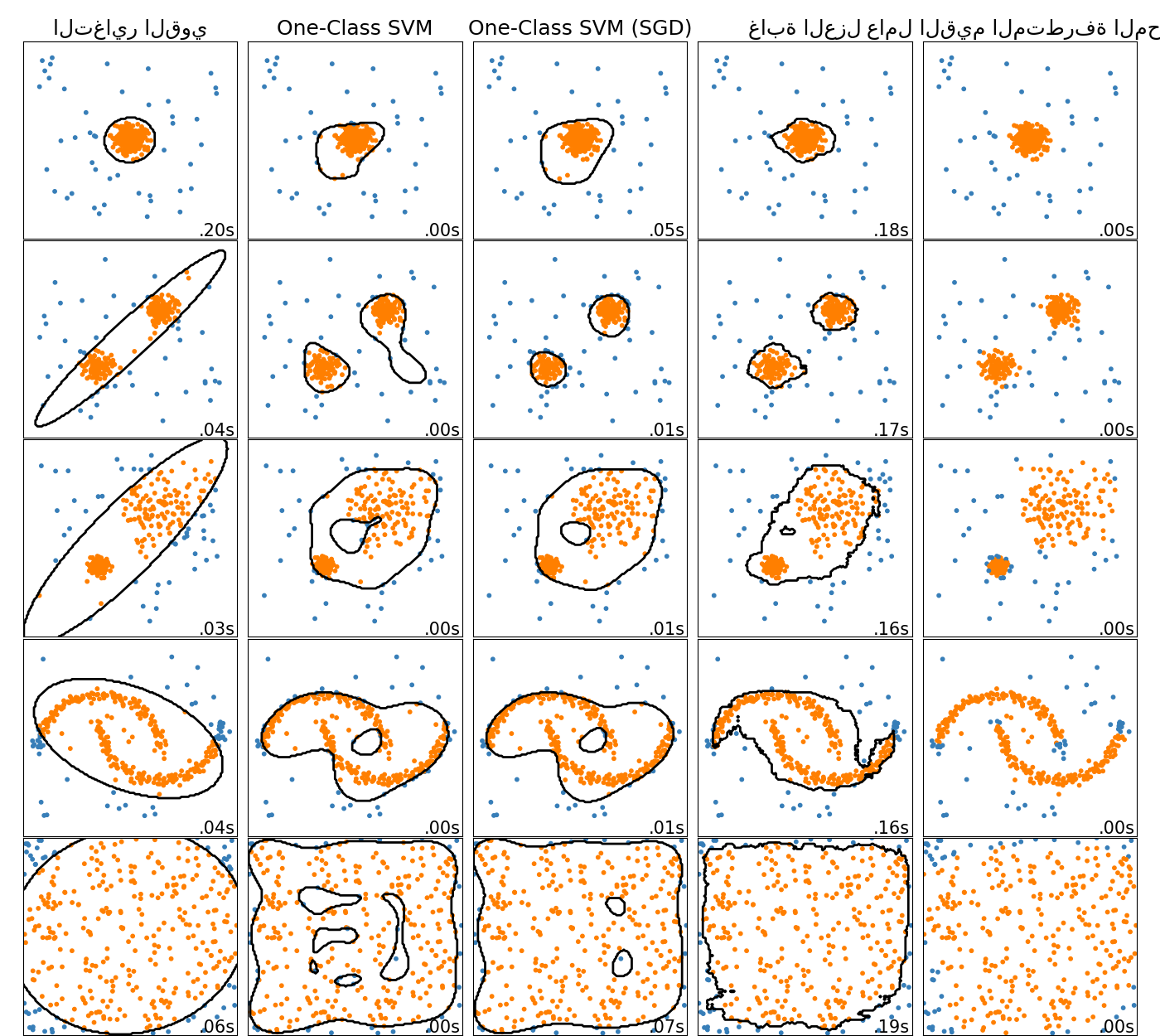
مقارنة خوارزميات الكشف عن الشذوذ لكشف القيم المتطرفة في مجموعات بيانات تجريبية#
يوضح هذا المثال خصائص خوارزميات مختلفة للكشف عن الشذوذ على مجموعات بيانات ثنائية الأبعاد. تحتوي مجموعات البيانات على نمط واحد أو نمطين (مناطق ذات كثافة عالية) لتوضيح قدرة الخوارزميات على التعامل مع البيانات متعددة الأنماط.
لكل مجموعة بيانات، يتم إنشاء 15٪ من العينات كضوضاء موحدة عشوائية. هذه النسبة هي القيمة المعطاة لمعامل nu لـ OneClassSVM ومعامل التلوث لخوارزميات الكشف عن القيم المتطرفة الأخرى. يتم عرض حدود القرار بين القيم الداخلية والخارجية باللون الأسود باستثناء عامل القيم المتطرفة المحلي (LOF) لأنه لا يحتوي على طريقة تنبؤ لتطبيقها على بيانات جديدة عند استخدامه للكشف عن القيم المتطرفة.
من المعروف أن OneClassSVM حساس للقيم المتطرفة
وبالتالي لا يؤدي أداءً جيدًا جدًا للكشف عن القيم المتطرفة. هذا المقدّر
هو الأنسب للكشف عن الجدة عندما لا تكون مجموعة التدريب ملوثة
بالقيم المتطرفة. ومع ذلك، فإن الكشف عن القيم المتطرفة في الأبعاد العالية، أو
بدون أي افتراضات حول توزيع البيانات الداخلية، يمثل تحديًا كبيرًا، وقد
يعطي One-class SVM نتائج مفيدة في هذه المواقف اعتمادًا على
قيمة المعلمات الفائقة الخاصة به.
sklearn.linear_model.SGDOneClassSVM هو تطبيق لـ One-Class SVM
يعتمد على هبوط التدرج العشوائي (SGD). بالاقتران مع تقريب النواة، يمكن
استخدام هذا المقدّر لتقريب الحل
لـ sklearn.svm.OneClassSVM مع نواة. نلاحظ أنه على الرغم من
عدم تطابقها، فإن حدود القرار لـ
sklearn.linear_model.SGDOneClassSVM وحدود
sklearn.svm.OneClassSVM متشابهة جدًا. الميزة الرئيسية لاستخدام
sklearn.linear_model.SGDOneClassSVM هي أنه يتناسب خطيًا مع
عدد العينات.
يفترض sklearn.covariance.EllipticEnvelope أن البيانات غاوسية
ويتعلم قطعًا ناقصًا. وبالتالي يتدهور عندما لا تكون البيانات أحادية النمط.
لاحظ مع ذلك أن هذا المقدّر قوي ضد القيم المتطرفة.
يبدو أن IsolationForest و
LocalOutlierFactor يؤديان أداءً جيدًا بشكل معقول
لمجموعات البيانات متعددة الأنماط. يتم عرض ميزة
LocalOutlierFactor على المقدّرات الأخرى
لمجموعة البيانات الثالثة، حيث يكون للنمطين كثافات مختلفة.
يفسر هذا الميزة الجانب المحلي لـ LOF، مما يعني أنه يقارن فقط
درجة شذوذ عينة واحدة بدرجات جيرانها.
أخيرًا، بالنسبة لمجموعة البيانات الأخيرة، من الصعب القول أن عينة واحدة
أكثر شذوذًا من عينة أخرى لأنها موزعة بشكل موحد في
مكعب فائق الأبعاد. باستثناء OneClassSVM الذي يلائم
قليلاً، فإن جميع المقدّرات تقدم حلولاً لائقة لهذا الموقف. في مثل هذه
الحالة، سيكون من الحكمة إلقاء نظرة فاحصة على درجات شذوذ
العينات حيث يجب أن يقوم مقدّر جيد بتعيين درجات مماثلة لجميع
العينات.
على الرغم من أن هذه الأمثلة تعطي بعض الحدس حول الخوارزميات، إلا أن هذا الحدس قد لا ينطبق على البيانات عالية الأبعاد.
أخيرًا، لاحظ أنه تم هنا اختيار معلمات النماذج يدويًا ولكن في الممارسة العملية، يجب ضبطها. في حالة عدم وجود بيانات معنونة، تكون المشكلة غير خاضعة للإشراف تمامًا، لذلك قد يكون اختيار النموذج تحديًا.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import time
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn import svm
from sklearn.covariance import EllipticEnvelope
from sklearn.datasets import make_blobs, make_moons
from sklearn.ensemble import IsolationForest
from sklearn.kernel_approximation import Nystroem
from sklearn.linear_model import SGDOneClassSVM
from sklearn.neighbors import LocalOutlierFactor
from sklearn.pipeline import make_pipeline
matplotlib.rcParams["contour.negative_linestyle"] = "solid"
# إعدادات المثال
n_samples = 300
outliers_fraction = 0.15
n_outliers = int(outliers_fraction * n_samples)
n_inliers = n_samples - n_outliers
# تعريف طرق الكشف عن القيم المتطرفة / الشذوذ التي سيتم مقارنتها.
# يجب استخدام SGDOneClassSVM في خط أنابيب مع تقريب النواة
# لإعطاء نتائج مماثلة لـ OneClassSVM
anomaly_algorithms = [
(
"التغاير القوي",
EllipticEnvelope(contamination=outliers_fraction, random_state=42),
),
("One-Class SVM", svm.OneClassSVM(nu=outliers_fraction, kernel="rbf", gamma=0.1)),
(
"One-Class SVM (SGD)",
make_pipeline(
Nystroem(gamma=0.1, random_state=42, n_components=150),
SGDOneClassSVM(
nu=outliers_fraction,
shuffle=True,
fit_intercept=True,
random_state=42,
tol=1e-6,
),
),
),
(
"غابة العزل",
IsolationForest(contamination=outliers_fraction, random_state=42),
),
(
"عامل القيم المتطرفة المحلي",
LocalOutlierFactor(n_neighbors=35, contamination=outliers_fraction),
),
]
# تعريف مجموعات البيانات
blobs_params = dict(random_state=0, n_samples=n_inliers, n_features=2)
datasets = [
make_blobs(centers=[[0, 0], [0, 0]], cluster_std=0.5, **blobs_params)[0],
make_blobs(centers=[[2, 2], [-2, -2]], cluster_std=[0.5, 0.5], **blobs_params)[0],
make_blobs(centers=[[2, 2], [-2, -2]], cluster_std=[1.5, 0.3], **blobs_params)[0],
4.0
* (
make_moons(n_samples=n_samples, noise=0.05, random_state=0)[0]
- np.array([0.5, 0.25])
),
14.0 * (np.random.RandomState(42).rand(n_samples, 2) - 0.5),
]
# مقارنة المصنفات المعطاة في ظل الإعدادات المعطاة
xx, yy = np.meshgrid(np.linspace(-7, 7, 150), np.linspace(-7, 7, 150))
plt.figure(figsize=(len(anomaly_algorithms) * 2 + 4, 12.5))
plt.subplots_adjust(
left=0.02, right=0.98, bottom=0.001, top=0.96, wspace=0.05, hspace=0.01
)
plot_num = 1
rng = np.random.RandomState(42)
for i_dataset, X in enumerate(datasets):
# إضافة القيم المتطرفة
X = np.concatenate([X, rng.uniform(low=-6, high=6, size=(n_outliers, 2))], axis=0)
for name, algorithm in anomaly_algorithms:
t0 = time.time()
algorithm.fit(X)
t1 = time.time()
plt.subplot(len(datasets), len(anomaly_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
# ملاءمة البيانات ووضع علامات على القيم المتطرفة
if name == "عامل القيم المتطرفة المحلي":
y_pred = algorithm.fit_predict(X)
else:
y_pred = algorithm.fit(X).predict(X)
# رسم خطوط المستويات والنقاط
if name != "عامل القيم المتطرفة المحلي": # LOF لا ينفذ التنبؤ
Z = algorithm.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors="black")
colors = np.array(["#377eb8", "#ff7f00"])
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[(y_pred + 1) // 2])
plt.xlim(-7, 7)
plt.ylim(-7, 7)
plt.xticks(())
plt.yticks(())
plt.text(
0.99,
0.01,
("%.2fs" % (t1 - t0)).lstrip("0"),
transform=plt.gca().transAxes,
size=15,
horizontalalignment="right",
)
plot_num += 1
plt.show()
Total running time of the script: (0 minutes 4.533 seconds)
Related examples

One-Class SVM مقابل One-Class SVM باستخدام Stochastic Gradient Descent
الكشف عن القيم الشاذة باستخدام عامل الانحراف المحلي (LOF)
الكشف عن البيانات الشاذة باستخدام عامل الانحراف المحلي (LOF)