ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
الكشف عن القيم الشاذة في مجموعة بيانات حقيقية#
يوضح هذا المثال الحاجة إلى تقدير متانة التغاير على مجموعة بيانات حقيقية. وهو مفيد لكل من الكشف عن القيم الشاذة وفهم أفضل لهيكل البيانات.
لقد اخترنا مجموعتين من متغيرين من مجموعة بيانات النبيذ كمثال على نوع التحليل الذي يمكن إجراؤه باستخدام العديد من أدوات الكشف عن القيم الشاذة. ولأغراض التوضيح، نعمل مع أمثلة ثنائية الأبعاد، ولكن يجب أن ندرك أن الأمور ليست بهذه البساطة في الأبعاد العالية، كما سيتم الإشارة إليه.
في كلا المثالين أدناه، النتيجة الرئيسية هي أن تقدير التغاير التجريبي، كتقدير غير متين، يتأثر بشدة بالهيكل غير المتجانس للملاحظات. على الرغم من أن تقدير التغاير المتين قادر على التركيز على الوضع الرئيسي لتوزيع البيانات، إلا أنه يلتزم بافتراض أن البيانات يجب أن تكون موزعة بشكل غاوسي، مما يؤدي إلى بعض التقديرات المتحيزة لهيكل البيانات، ولكنها دقيقة إلى حد ما. لا يفترض One-Class SVM أي شكل معلمي لتوزيع البيانات ويمكنه بالتالي نمذجة الشكل المعقد للبيانات بشكل أفضل.
# المؤلفون: مطوري scikit-learn
# معرف رخصة SPDX: BSD-3-Clause
المثال الأول#
يوضح المثال الأول كيف يمكن لمقدر التغاير الأدنى للمحدد أن يساعد في التركيز على مجموعة فرعية ذات صلة عند وجود نقاط شاذة. هنا، يتم تحريف تقدير التغاير التجريبي بواسطة نقاط خارج المجموعة الرئيسية. بالطبع، كان من الممكن لبعض أدوات الفحص أن تشير إلى وجود مجموعتين (آلات المتجهات الداعمة، نماذج المزيج الغاوسي، الكشف عن القيم الشاذة أحادية المتغير، ...). ولكن لو كان مثالاً عالي الأبعاد، لم يكن من الممكن تطبيق أي من هذه الأدوات بسهولة.
from sklearn.covariance import EllipticEnvelope
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.svm import OneClassSVM
estimators = {
"Empirical Covariance": EllipticEnvelope(support_fraction=1.0, contamination=0.25),
"Robust Covariance (Minimum Covariance Determinant)": EllipticEnvelope(
contamination=0.25
),
"OCSVM": OneClassSVM(nu=0.25, gamma=0.35),
}
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
X = load_wine()["data"][:, [1, 2]] # مجموعتان
fig, ax = plt.subplots()
colors = ["tab:blue", "tab:orange", "tab:red"]
# تعلم حدود للكشف عن القيم الشاذة باستخدام عدة مصنفات
legend_lines = []
for color, (name, estimator) in zip(colors, estimators.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
bbox_args = dict(boxstyle="round", fc="0.8")
arrow_args = dict(arrowstyle="->")
ax.annotate(
"outlying points",
xy=(4, 2),
xycoords="data",
textcoords="data",
xytext=(3, 1.25),
bbox=bbox_args,
arrowprops=arrow_args,
)
ax.legend(handles=legend_lines, loc="upper center")
_ = ax.set(
xlabel="ash",
ylabel="malic_acid",
title="Outlier detection on a real data set (wine recognition)",
)
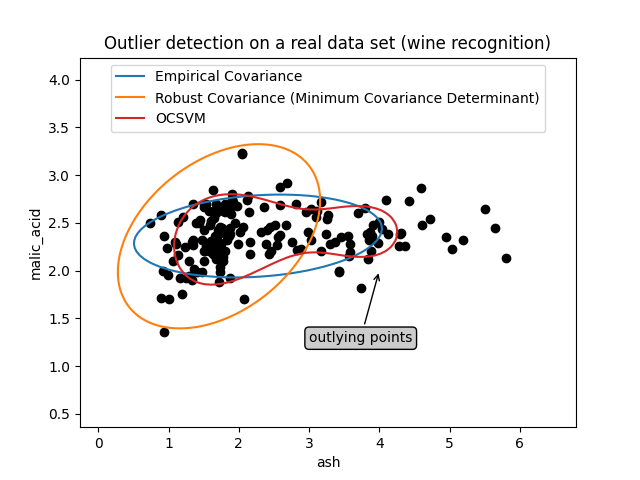
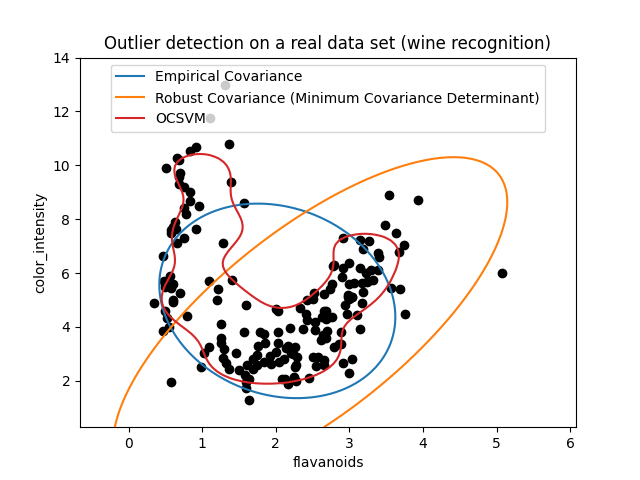
المثال الثاني#
يظهر المثال الثاني قدرة مقدر التغاير الأدنى للمحدد على التركيز على الوضع الرئيسي لتوزيع البيانات التوزيع: يبدو أن الموقع يتم تقديره بشكل جيد، على الرغم من أن التغاير يصعب تقديره بسبب التوزيع على شكل الموز. على أي حال، يمكننا التخلص من بعض الملاحظات الشاذة. يمكن لـ One-Class SVM التقاط هيكل البيانات الحقيقي، ولكن الصعوبة تكمن في ضبط معلمة نطاق نواة بحيث نحصل على حل وسط جيد بين شكل مصفوفة تشتت البيانات ومخاطر الإفراط في ملاءمة البيانات.
X = load_wine()["data"][:, [6, 9]] # على شكل "موز"
fig, ax = plt.subplots()
colors = ["tab:blue", "tab:orange", "tab:red"]
# تعلم حدود للكشف عن القيم الشاذة باستخدام عدة مصنفات
legend_lines = []
for color, (name, estimator) in zip(colors, estimators.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Outlier detection on a real data set (wine recognition)",
)
plt.show()
Total running time of the script: (0 minutes 0.792 seconds)
Related examples

One-Class SVM مقابل One-Class SVM باستخدام Stochastic Gradient Descent
الكشف عن القيم الشاذة باستخدام عامل الانحراف المحلي (LOF)