ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
مثال على التعرف على الوجوه باستخدام الوجوه المميزة وآلات المتجهات الداعمة#
مجموعة البيانات المستخدمة في هذا المثال هي مقتطف مُعالج مسبقًا من "الوجوه المسماة في البرية"، المعروف باسم LFW: http://vis-www.cs.umass.edu/lfw/lfw-funneled.tgz (233MB)
# المؤلفون: مطوري سكايت-ليرن
# معرف الترخيص-SPDX: BSD-3-Clause
from time import time
import matplotlib.pyplot as plt
from scipy.stats import loguniform
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.metrics import ConfusionMatrixDisplay, classification_report
from sklearn.model_selection import RandomizedSearchCV, train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
تنزيل البيانات، إذا لم تكن موجودة بالفعل على القرص وتحميلها كمصفوفات نومبي
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# فحص مصفوفات الصور لمعرفة الأشكال (للرسم)
n_samples, h, w = lfw_people.images.shape
# للتعلم الآلي، نستخدم البيانات مباشرةً (حيث يتم تجاهل معلومات مواضع البكسل النسبية
# بواسطة هذا النموذج)
X = lfw_people.data
n_features = X.shape[1]
# التسمية التي يجب التنبؤ بها هي معرف الشخص
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("حجم مجموعة البيانات الإجمالي:")
print("n_samples: %d" % n_samples)
print("n_features: %d" % n_features)
print("n_classes: %d" % n_classes)
حجم مجموعة البيانات الإجمالي:
n_samples: 1288
n_features: 1850
n_classes: 7
التقسيم إلى مجموعة تدريب ومجموعة اختبار والاحتفاظ بـ 25% من البيانات للاختبار.
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
حساب التحليل المكون الرئيسي (الوجوه المميزة) على مجموعة بيانات الوجه (المعالجة كمجموعة بيانات غير مصنفة): استخراج الميزات غير الخاضعة للإشراف / تقليل الأبعاد
n_components = 150
print(
"استخراج أفضل %d وجوه مميزة من %d وجوه" % (n_components, X_train.shape[0])
)
t0 = time()
pca = PCA(n_components=n_components, svd_solver="randomized", whiten=True).fit(X_train)
print("تم الانتهاء في %0.3fs" % (time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w))
print("رسم بيانات الإدخال على أساس الوجوه المميزة المتعامدة")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("تم الانتهاء في %0.3fs" % (time() - t0))
استخراج أفضل 150 وجوه مميزة من 966 وجوه
تم الانتهاء في 0.303s
رسم بيانات الإدخال على أساس الوجوه المميزة المتعامدة
تم الانتهاء في 0.023s
تدريب نموذج تصنيف آلة المتجهات الداعمة
print("ضبط المصنف على مجموعة التدريب")
t0 = time()
param_grid = {
"C": loguniform(1e3, 1e5),
"gamma": loguniform(1e-4, 1e-1),
}
clf = RandomizedSearchCV(
SVC(kernel="rbf", class_weight="balanced"), param_grid, n_iter=10
)
clf = clf.fit(X_train_pca, y_train)
print("تم الانتهاء في %0.3fs" % (time() - t0))
print("أفضل مقدر تم العثور عليه بواسطة البحث الشبكي:")
print(clf.best_estimator_)
ضبط المصنف على مجموعة التدريب
تم الانتهاء في 5.084s
أفضل مقدر تم العثور عليه بواسطة البحث الشبكي:
SVC(C=7977.580335831192, class_weight='balanced', gamma=0.00369819428936649)
التقييم الكمي لجودة النموذج على مجموعة الاختبار
print("التنبؤ بأسماء الأشخاص على مجموعة الاختبار")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("تم الانتهاء في %0.3fs" % (time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
ConfusionMatrixDisplay.from_estimator(
clf, X_test_pca, y_test, display_labels=target_names, xticks_rotation="vertical"
)
plt.tight_layout()
plt.show()
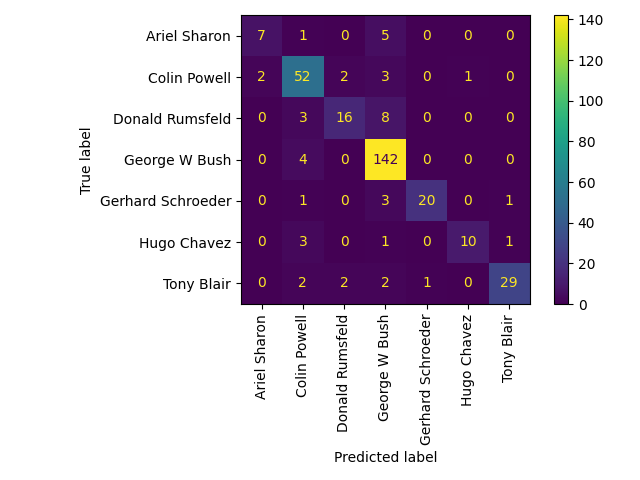
التنبؤ بأسماء الأشخاص على مجموعة الاختبار
تم الانتهاء في 0.058s
precision recall f1-score support
Ariel Sharon 0.78 0.54 0.64 13
Colin Powell 0.79 0.87 0.83 60
Donald Rumsfeld 0.80 0.59 0.68 27
George W Bush 0.87 0.97 0.92 146
Gerhard Schroeder 0.95 0.80 0.87 25
Hugo Chavez 0.91 0.67 0.77 15
Tony Blair 0.94 0.81 0.87 36
accuracy 0.86 322
macro avg 0.86 0.75 0.79 322
weighted avg 0.86 0.86 0.85 322
التقييم النوعي للتنبؤات باستخدام ماتبلوتليب
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""دالة مساعدة لرسم معرض للصور الشخصية"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=0.01, right=0.99, top=0.90, hspace=0.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
رسم نتيجة التنبؤ على جزء من مجموعة الاختبار %% رسم نتيجة التنبؤ على جزء من مجموعة الاختبار
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(" ", 1)[-1]
true_name = target_names[y_test[i]].rsplit(" ", 1)[-1]
return "المتنبأ به: %s\nالحقيقي: %s" % (pred_name, true_name)
prediction_titles = [
title(y_pred, y_test, target_names, i) for i in range(y_pred.shape[0])
]
plot_gallery(X_test, prediction_titles, h, w)

رسم معرض الوجوه المميزة الأكثر دلالة
eigenface_titles = ["الوجه المميز %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()

يمكن حل مشكلة التعرف على الوجه بشكل أكثر فعالية من خلال تدريب الشبكات العصبية التلافيفية، ولكن هذه العائلة من النماذج خارج نطاق مكتبة سكايت-ليرن. يجب على القراء المهتمين تجربة استخدام باي تورتش أو تنسور فلو لتنفيذ مثل هذه النماذج.
Total running time of the script: (0 minutes 27.894 seconds)
Related examples
sphx_glr_auto_examples_applications_plot_topics_extraction_with_nmf_lda.py

