ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز الميزات الجديدة في الإصدار 1.5 من scikit-learn#
يسعدنا الإعلان عن إصدار scikit-learn 1.5! تم إصلاح العديد من الأخطاء وإضافة العديد من التحسينات، بالإضافة إلى بعض الميزات الجديدة الرئيسية. فيما يلي نقدم أبرز ميزات هذا الإصدار. للحصول على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
FixedThresholdClassifier: ضبط عتبة القرار لمصنّف ثنائي#
تستخدم جميع المصنفات الثنائية في scikit-learn عتبة قرار ثابتة تبلغ 0.5
لتحويل تقديرات الاحتمال (أي ناتج predict_proba) إلى تنبؤات
الفئة. ومع ذلك، فإن 0.5 نادراً ما يكون العتبة المرغوبة لمشكلة معينة. FixedThresholdClassifier يسمح بتغليف أي
مصنف ثنائي وضبط عتبة قرار مخصصة.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import ConfusionMatrixDisplay
X, y = make_classification(n_samples=10_000, weights=[0.9, 0.1], random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
classifier_05 = LogisticRegression(C=1e6, random_state=0).fit(X_train, y_train)
_ = ConfusionMatrixDisplay.from_estimator(classifier_05, X_test, y_test)
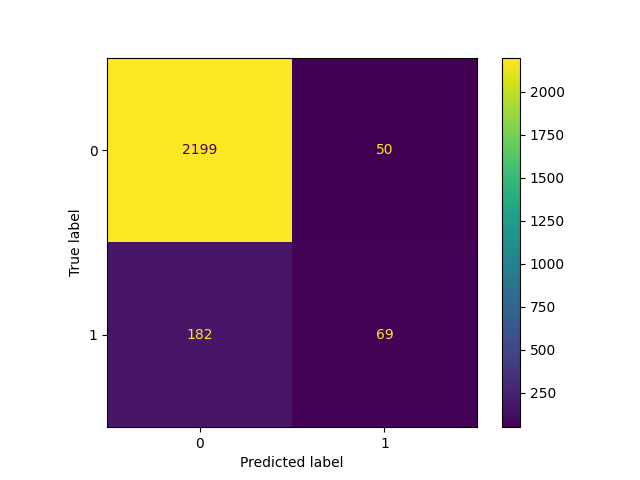
يؤدي خفض العتبة، أي السماح للمزيد من العينات بالتصنيف على أنها الفئة الإيجابية، إلى زيادة عدد الإيجابيات الحقيقية على حساب المزيد من الإيجابيات الخاطئة (كما هو معروف جيداً من تقعر منحنى ROC).
from sklearn.model_selection import FixedThresholdClassifier
classifier_01 = FixedThresholdClassifier(classifier_05, threshold=0.1)
classifier_01.fit(X_train, y_train)
_ = ConfusionMatrixDisplay.from_estimator(classifier_01, X_test, y_test)
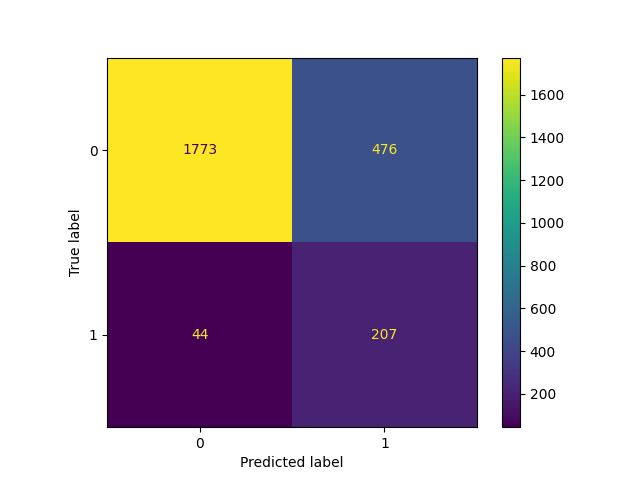
TunedThresholdClassifierCV: ضبط عتبة القرار لمصنّف ثنائي#
يمكن ضبط عتبة القرار لمصنّف ثنائي لتحسين مقياس معين، باستخدام TunedThresholdClassifierCV.
إنه مفيد بشكل خاص للعثور على أفضل عتبة قرار عندما يكون النموذج مخصصاً للعمل في سياق تطبيق محدد حيث يمكننا تعيين مكاسب أو تكاليف مختلفة للإيجابيات الحقيقية، والإيجابيات الخاطئة، والسلبيات الخاطئة، والسلبيات الحقيقية.
دعنا نوضح ذلك من خلال النظر في حالة تعسفية حيث:
كل إيجابية حقيقية تحقق مكسباً قدره 1 وحدة، على سبيل المثال، يورو، سنة من الحياة في صحة جيدة، إلخ؛
لا تحقق الإيجابيات الحقيقية أي مكاسب أو تكاليف؛
كل سلبية خاطئة تكلف 2؛
كل إيجابية خاطئة تكلف 0.1.
يحدد مقياسنا متوسط الربح لكل عينة، والذي يتم تعريفه بواسطة دالة Python التالية:
from sklearn.metrics import confusion_matrix
def custom_score(y_observed, y_pred):
tn, fp, fn, tp = confusion_matrix(y_observed, y_pred, normalize="all").ravel()
return tp - 2 * fn - 0.1 * fp
print("Untuned decision threshold: 0.5")
print(f"Custom score: {custom_score(y_test, classifier_05.predict(X_test)):.2f}")
Untuned decision threshold: 0.5
Custom score: -0.12
من المثير للاهتمام ملاحظة أن متوسط الربح لكل تنبؤ سلبي، مما يعني أن هذا النظام القرار يسبب خسارة في المتوسط.
يؤدي ضبط العتبة لتحسين هذا المقياس المخصص إلى عتبة أصغر تسمح للمزيد من العينات بالتصنيف على أنها الفئة الإيجابية. ونتيجة لذلك، يتحسن متوسط الربح لكل تنبؤ.
from sklearn.model_selection import TunedThresholdClassifierCV
from sklearn.metrics import make_scorer
custom_scorer = make_scorer(
custom_score, response_method="predict", greater_is_better=True
)
tuned_classifier = TunedThresholdClassifierCV(
classifier_05, cv=5, scoring=custom_scorer
).fit(X, y)
print(f"Tuned decision threshold: {tuned_classifier.best_threshold_:.3f}")
print(f"Custom score: {custom_score(y_test, tuned_classifier.predict(X_test)):.2f}")
Tuned decision threshold: 0.071
Custom score: 0.04
نلاحظ أن ضبط عتبة القرار يمكن أن يحول نظام التعلم الآلي الذي يسبب خسارة في المتوسط إلى نظام مفيد.
في الممارسة العملية، قد يتضمن تعريف مقياس محدد للتطبيق جعل تلك التكاليف للتنبؤات الخاطئة والمكاسب للتنبؤات الصحيحة تعتمد على البيانات الوصفية المساعدة المحددة لكل نقطة بيانات فردية مثل المبلغ من المعاملة في نظام كشف الاحتيال.
لتحقيق ذلك، TunedThresholdClassifierCV
يستفيد من دعم توجيه البيانات الوصفية (Metadata Routing User
Guide) مما يسمح بتحسين مقاييس الأعمال المعقدة كما
هو مفصل في Post-tuning the decision threshold for cost-sensitive
learning.
تحسينات الأداء في PCA#
PCA لديه محدد جديد، "covariance_eigh"، والذي هو
أسرع وأكثر كفاءة في الذاكرة من المحددات الأخرى بمقدار يصل إلى 10 مرات للمجموعات ذات البيانات الكثيرة والميزات القليلة.
from sklearn.datasets import make_low_rank_matrix
from sklearn.decomposition import PCA
X = make_low_rank_matrix(
n_samples=10_000, n_features=100, tail_strength=0.1, random_state=0
)
pca = PCA(n_components=10, svd_solver="covariance_eigh").fit(X)
print(f"Explained variance: {pca.explained_variance_ratio_.sum():.2f}")
Explained variance: 0.88
يقبل المحدد الجديد أيضاً بيانات الإدخال الناقصة:
Explained variance: 0.13
تم تحسين محدد "full" أيضاً لاستخدام ذاكرة أقل ويسمح
بالتحويل الأسرع. خيار svd_solver="auto"` الافتراضي يستفيد
من المحدد الجديد ويمكنه الآن اختيار محدد مناسب
للمجموعات الناقصة.
وعلى غرار معظم محددات PCA الأخرى، يمكن للمحدد الجديد "covariance_eigh" أن يستفيد
من حسابات GPU إذا تم تمرير بيانات الإدخال كصفيف PyTorch أو CuPy من خلال
تمكين الدعم التجريبي لـ Array API.
إمكانية الوصول إلى المحولات في ColumnTransformer#
يمكن الآن الوصول إلى المحولات في ColumnTransformer مباشرة
باستخدام الفهرسة حسب الاسم.
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
X = np.array([[0, 1, 2], [3, 4, 5]])
column_transformer = ColumnTransformer(
[("std_scaler", StandardScaler(), [0]), ("one_hot", OneHotEncoder(), [1, 2])]
)
column_transformer.fit(X)
print(column_transformer["std_scaler"])
print(column_transformer["one_hot"])
StandardScaler()
OneHotEncoder()
استراتيجيات الإكمال المخصصة لـ SimpleImputer#
SimpleImputer يدعم الآن استراتيجيات مخصصة للإكمال،
باستخدام دالة قابلة للاستدعاء تحسب قيمة قياسية من القيم غير المفقودة في
متجه عمودي.
from sklearn.impute import SimpleImputer
X = np.array(
[
[-1.1, 1.1, 1.1],
[3.9, -1.2, np.nan],
[np.nan, 1.3, np.nan],
[-0.1, -1.4, -1.4],
[-4.9, 1.5, -1.5],
[np.nan, 1.6, 1.6],
]
)
def smallest_abs(arr):
"""Return the smallest absolute value of a 1D array."""
return np.min(np.abs(arr))
imputer = SimpleImputer(strategy=smallest_abs)
imputer.fit_transform(X)
array([[-1.1, 1.1, 1.1],
[ 3.9, -1.2, 1.1],
[ 0.1, 1.3, 1.1],
[-0.1, -1.4, -1.4],
[-4.9, 1.5, -1.5],
[ 0.1, 1.6, 1.6]])
المسافات الزوجية مع المصفوفات غير الرقمية#
pairwise_distances يمكنه الآن حساب المسافات بين
المصفوفات غير الرقمية باستخدام دالة قياس قابلة للاستدعاء.
from sklearn.metrics import pairwise_distances
X = ["cat", "dog"]
Y = ["cat", "fox"]
def levenshtein_distance(x, y):
"""Return the Levenshtein distance between two strings."""
if x == "" or y == "":
return max(len(x), len(y))
if x[0] == y[0]:
return levenshtein_distance(x[1:], y[1:])
return 1 + min(
levenshtein_distance(x[1:], y),
levenshtein_distance(x, y[1:]),
levenshtein_distance(x[1:], y[1:]),
)
pairwise_distances(X, Y, metric=levenshtein_distance)
array([[0., 3.],
[3., 2.]])
Total running time of the script: (0 minutes 0.827 seconds)
Related examples