ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
استنتاج القيم المفقودة مع متغيرات من IterativeImputer#
الفئة IterativeImputer مرنة للغاية - يمكن استخدامها مع مجموعة متنوعة من أدوات التقدير للقيام بانحدار دائري، معاملة كل متغير كمخرج بدوره.
في هذا المثال، نقارن بعض أدوات التقدير لغرض استنتاج الميزات المفقودة مع IterativeImputer:
BayesianRidge: انحدار خطي منتظمRandomForestRegressor: انحدار غابات الأشجار العشوائيةmake_pipeline(Nystroem,Ridge): خط أنابيب مع توسيع نواة متعددة الحدود من الدرجة 2 وانحدار خطي منتظمKNeighborsRegressor: مشابه لطرق استنتاج KNN الأخرى
من الأمور ذات الأهمية الخاصة قدرة IterativeImputer على محاكاة سلوك missForest، وهي حزمة استنتاج شائع لـ R.
لاحظ أن KNeighborsRegressor يختلف عن استنتاج KNN، الذي يتعلم من العينات ذات القيم المفقودة باستخدام مقياس مسافة يفسر في القيم المفقودة، بدلاً من استنتاجها.
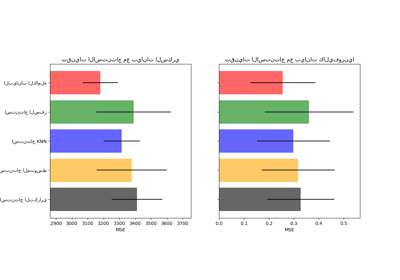
الهدف هو مقارنة أدوات التقدير المختلفة لمعرفة أيها الأفضل لـ IterativeImputer عند استخدام أداة تقدير BayesianRidge على مجموعة بيانات إسكان كاليفورنيا مع قيمة واحدة تم إزالها عشوائيًا من كل صف.
بالنسبة لهذا النمط المحدد من القيم المفقودة، نرى أن BayesianRidge و RandomForestRegressor يعطيان أفضل النتائج.
تجدر الإشارة إلى أن بعض أدوات التقدير مثل HistGradientBoostingRegressor يمكنها التعامل بشكل أصلي مع الميزات المفقودة وغالبًا ما يوصى بها بدلاً من إنشاء خطوط أنابيب مع استراتيجيات استنتاج قيم مفقودة معقدة ومكلفة.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
# لاستخدام هذه الميزة التجريبية، نحتاج إلى طلبها صراحةً:
from sklearn.experimental import enable_iterative_imputer # noqa
from sklearn.impute import IterativeImputer, SimpleImputer
from sklearn.kernel_approximation import Nystroem
from sklearn.linear_model import BayesianRidge, Ridge
from sklearn.model_selection import cross_val_score
from sklearn.neighbors import KNeighborsRegressor
from sklearn.pipeline import make_pipeline
N_SPLITS = 5
rng = np.random.RandomState(0)
X_full, y_full = fetch_california_housing(return_X_y=True)
# ~ 2k عينة كافية لغرض المثال.
# قم بإزالة السطرين التاليين لتشغيل أبطأ بأشرطة خطأ مختلفة.
X_full = X_full[::10]
y_full = y_full[::10]
n_samples, n_features = X_full.shape
# تقدير النتيجة على مجموعة البيانات بأكملها، بدون قيم مفقودة
br_estimator = BayesianRidge()
score_full_data = pd.DataFrame(
cross_val_score(
br_estimator, X_full, y_full, scoring="neg_mean_squared_error", cv=N_SPLITS
),
columns=["البيانات الكاملة"],
)
# إضافة قيمة مفقودة واحدة لكل صف
X_missing = X_full.copy()
y_missing = y_full
missing_samples = np.arange(n_samples)
missing_features = rng.choice(n_features, n_samples, replace=True)
X_missing[missing_samples, missing_features] = np.nan
# تقدير النتيجة بعد الاستنتاج (استراتيجيات المتوسط والوسيط)
score_simple_imputer = pd.DataFrame()
for strategy in ("mean", "median"):
estimator = make_pipeline(
SimpleImputer(missing_values=np.nan, strategy=strategy), br_estimator
)
score_simple_imputer[strategy] = cross_val_score(
estimator, X_missing, y_missing, scoring="neg_mean_squared_error", cv=N_SPLITS
)
# تقدير النتيجة بعد الاستنتاج التكراري للقيم المفقودة
# مع أدوات تقدير مختلفة
estimators = [
BayesianRidge(),
RandomForestRegressor(
# قمنا بضبط المعلمات الفائقة لـ RandomForestRegressor للحصول على أداء تنبؤي جيد بما فيه الكفاية لوقت تنفيذ محدود.
n_estimators=4,
max_depth=10,
bootstrap=True,
max_samples=0.5,
n_jobs=2,
random_state=0,
),
make_pipeline(
Nystroem(kernel="polynomial", degree=2, random_state=0), Ridge(alpha=1e3)
),
KNeighborsRegressor(n_neighbors=15),
]
score_iterative_imputer = pd.DataFrame()
# أداة الاستنتاج التكراري حساسة للتسامح و
# تعتمد على أداة التقدير المستخدمة داخليًا.
# قمنا بضبط التسامح للحفاظ على تشغيل هذا المثال بموارد حسابية محدودة مع عدم تغيير النتائج كثيرًا مقارنةً بالحفاظ على
# قيمة افتراضية أكثر صرامة لمعامل التسامح.
tolerances = (1e-3, 1e-1, 1e-1, 1e-2)
for impute_estimator, tol in zip(estimators, tolerances):
estimator = make_pipeline(
IterativeImputer(
random_state=0, estimator=impute_estimator, max_iter=25, tol=tol
),
br_estimator,
)
score_iterative_imputer[impute_estimator.__class__.__name__] = cross_val_score(
estimator, X_missing, y_missing, scoring="neg_mean_squared_error", cv=N_SPLITS
)
scores = pd.concat(
[score_full_data, score_simple_imputer, score_iterative_imputer],
keys=["الأصلية", "SimpleImputer", "IterativeImputer"],
axis=1,
)
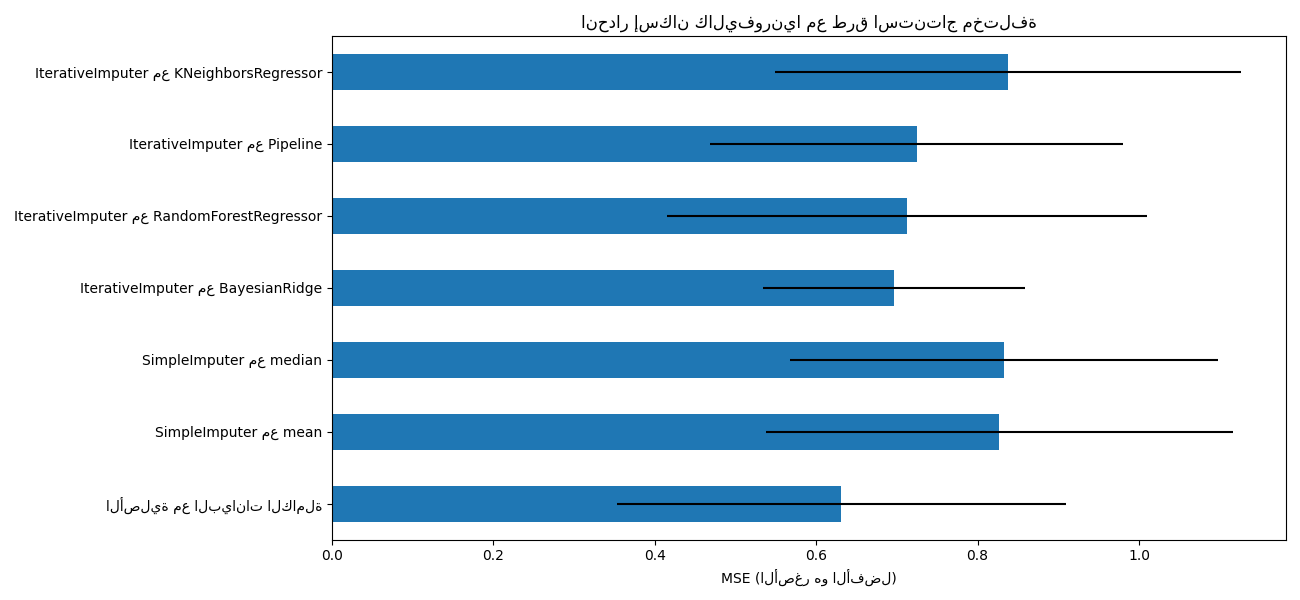
# plot california housing results
fig, ax = plt.subplots(figsize=(13, 6))
means = -scores.mean()
errors = scores.std()
means.plot.barh(xerr=errors, ax=ax)
ax.set_title("انحدار إسكان كاليفورنيا مع طرق استنتاج مختلفة")
ax.set_xlabel("MSE (الأصغر هو الأفضل)")
ax.set_yticks(np.arange(means.shape[0]))
ax.set_yticklabels([" مع ".join(label) for label in means.index.tolist()])
plt.tight_layout(pad=1)
plt.show()
Total running time of the script: (0 minutes 7.172 seconds)
Related examples