ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تصنيف MNIST باستخدام اللوغاريتم متعدد الحدود + L1#
هنا نقوم بضبط الانحدار اللوغاريتمي متعدد الحدود مع عقوبة L1 على مجموعة فرعية من مهمة تصنيف أرقام MNIST. نستخدم خوارزمية SAGA لهذا الغرض: هذه أداة حل سريعة عندما يكون عدد العينات أكبر بشكل ملحوظ من عدد الميزات وقادرة على تحسين دقيق وظائف الهدف غير الملساء والتي هي الحالة مع عقوبة l1. تصل دقة الاختبار > 0.8، بينما تبقى متجهات الوزن متفرقة وبالتالي أكثر سهولة قابل للتفسير.
ملاحظة: أن دقة هذا النموذج الخطي المعاقب عليه l1 أقل بكثير ما يمكن الوصول إليه بواسطة نموذج خطي معاقب عليه l2 أو نموذج متعدد الطبقات شبكة الإدراك غير الخطية على هذه المجموعة من البيانات.
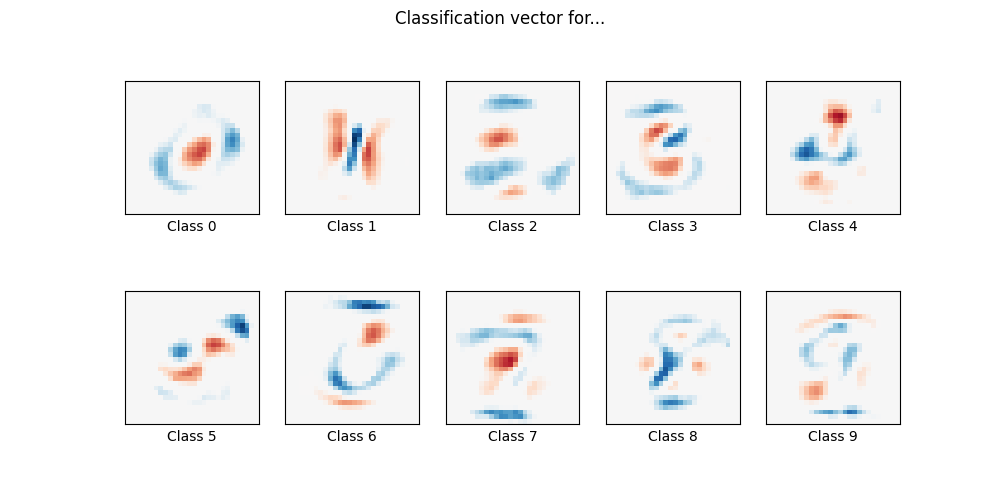
Sparsity with L1 penalty: 75.87%
Test score with L1 penalty: 0.8224
Example run in 7.375 s
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
import time
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.utils import check_random_state
# خفض للتقارب الأسرع
t0 = time.time()
train_samples = 5000
# تحميل البيانات من https://www.openml.org/d/554
X, y = fetch_openml("mnist_784", version=1, return_X_y=True, as_frame=False)
random_state = check_random_state(0)
permutation = random_state.permutation(X.shape[0])
X = X[permutation]
y = y[permutation]
X = X.reshape((X.shape[0], -1))
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=train_samples, test_size=10000
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# زيادة التسامح للتقارب الأسرع
clf = LogisticRegression(C=50.0 / train_samples, penalty="l1", solver="saga", tol=0.1)
clf.fit(X_train, y_train)
sparsity = np.mean(clf.coef_ == 0) * 100
score = clf.score(X_test, y_test)
# print('Best C % .4f' % clf.C_)
print("Sparsity with L1 penalty: %.2f%%" % sparsity)
print("Test score with L1 penalty: %.4f" % score)
coef = clf.coef_.copy()
plt.figure(figsize=(10, 5))
scale = np.abs(coef).max()
for i in range(10):
l1_plot = plt.subplot(2, 5, i + 1)
l1_plot.imshow(
coef[i].reshape(28, 28),
interpolation="nearest",
cmap=plt.cm.RdBu,
vmin=-scale,
vmax=scale,
)
l1_plot.set_xticks(())
l1_plot.set_yticks(())
l1_plot.set_xlabel("Class %i" % i)
plt.suptitle("Classification vector for...")
run_time = time.time() - t0
print("Example run in %.3f s" % run_time)
plt.show()
Total running time of the script: (0 minutes 7.462 seconds)
Related examples

الانحدار اللوجستي المتناثر متعدد الفئات على 20newgroups