ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
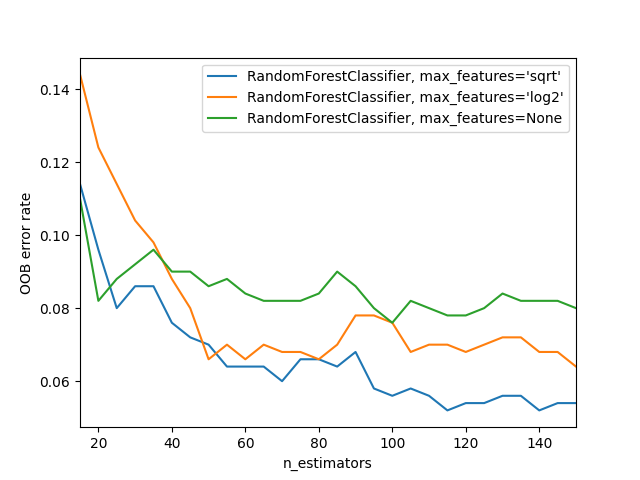
أخطاء OOB لخوارزمية Random Forests#
تم تدريب خوارزمية RandomForestClassifier باستخدام bootstrap aggregation، حيث يتم ملاءمة كل شجرة جديدة من عينة bootstrap من الملاحظات التدريبية \(z_i = (x_i, y_i)\). خطأ out-of-bag (OOB) هو متوسط الخطأ لكل \(z_i\) محسوبة باستخدام تنبؤات من الأشجار التي لا تحتوي على \(z_i\) في عينة bootstrap الخاصة بها. يسمح هذا لخوارزمية RandomForestClassifier بالتدريب والتحقق أثناء التدريب [1].
يوضح المثال أدناه كيفية قياس خطأ OOB عند إضافة كل شجرة جديدة أثناء التدريب. يسمح المخطط الناتج لممارس تقريب قيمة مناسبة لـ n_estimators والتي يستقر عندها الخطأ.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
from collections import OrderedDict
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
RANDOM_STATE = 123
# إنشاء مجموعة بيانات للتصنيف الثنائي.
X, y = make_classification(
n_samples=500,
n_features=25,
n_clusters_per_class=1,
n_informative=15,
random_state=RANDOM_STATE,
)
# ملاحظة: تعيين معلمة البناء `warm_start` إلى `True` تعطل
# دعم المجموعات الموازية ولكنها ضرورية لتتبع مسار خطأ OOB
# أثناء التدريب.
ensemble_clfs = [
(
"RandomForestClassifier, max_features='sqrt'",
RandomForestClassifier(
warm_start=True,
oob_score=True,
max_features="sqrt",
random_state=RANDOM_STATE,
),
),
(
"RandomForestClassifier, max_features='log2'",
RandomForestClassifier(
warm_start=True,
max_features="log2",
oob_score=True,
random_state=RANDOM_STATE,
),
),
(
"RandomForestClassifier, max_features=None",
RandomForestClassifier(
warm_start=True,
max_features=None,
oob_score=True,
random_state=RANDOM_STATE,
),
),
]
# ربط اسم المصنف بقائمة من أزواج (<n_estimators>, <error rate>).
error_rate = OrderedDict((label, []) for label, _ in ensemble_clfs)
# نطاق قيم `n_estimators` لاستكشافها.
min_estimators = 15
max_estimators = 150
for label, clf in ensemble_clfs:
for i in range(min_estimators, max_estimators + 1, 5):
clf.set_params(n_estimators=i)
clf.fit(X, y)
# تسجيل خطأ OOB لكل إعداد `n_estimators=i`.
oob_error = 1 - clf.oob_score_
error_rate[label].append((i, oob_error))
# إنشاء مخطط "معدل خطأ OOB" مقابل "n_estimators".
for label, clf_err in error_rate.items():
xs, ys = zip(*clf_err)
plt.plot(xs, ys, label=label)
plt.xlim(min_estimators, max_estimators)
plt.xlabel("n_estimators")
plt.ylabel("OOB error rate")
plt.legend(loc="upper right")
plt.show()
Total running time of the script: (0 minutes 4.223 seconds)
Related examples

رسم أسطح القرار لمجموعات الأشجار على مجموعة بيانات إيريس