ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أهمية التبديل مع الميزات متعددة الخطية أو المرتبطة#
في هذا المثال، نحسب
permutation_importance للميزات لـ
RandomForestClassifier مدربة باستخدام
Breast cancer wisconsin (diagnostic) dataset. يمكن للنموذج بسهولة الحصول على دقة تبلغ حوالي 97% على
مجموعة بيانات الاختبار. نظرًا لأن مجموعة البيانات هذه تحتوي على ميزات متعددة
الخطية، فإن أهمية التبديل تُظهر أنه لا توجد أي من الميزات مهمة، في
تناقض مع دقة الاختبار العالية.
نعرض نهجًا ممكنًا للتعامل مع التعدد الخطي، والذي يتكون من التجميع الهرمي على ارتباطات Spearman ذات الترتيب الرتبي للميزات، واختيار عتبة، والاحتفاظ بميزة واحدة من كل مجموعة.
ملاحظة
انظر أيضًا أهمية التبديل مقابل أهمية ميزة الغابة العشوائية (MDI)
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
أهمية ميزة الغابة العشوائية على بيانات سرطان الثدي#
أولاً، نحدد دالة لتسهيل الرسم:
import matplotlib
from sklearn.inspection import permutation_importance
from sklearn.utils.fixes import parse_version
def plot_permutation_importance(clf, X, y, ax):
result = permutation_importance(clf, X, y, n_repeats=10, random_state=42, n_jobs=2)
perm_sorted_idx = result.importances_mean.argsort()
# وسيطة `labels` في boxplot تم إهمالها في matplotlib 3.9 وتمت
# إعادة تسميتها إلى `tick_labels`. يتعامل الكود التالي مع هذا، ولكن بصفتك
# مستخدمًا لـ scikit-learn، فمن المحتمل أن تتمكن من كتابة كود أبسط باستخدام `labels = ...`
# (matplotlib <3.9) أو `tick_labels = ...` (matplotlib> = 3.9).
tick_labels_parameter_name = (
"tick_labels"
if parse_version(matplotlib.__version__) >= parse_version("3.9")
else "labels"
)
tick_labels_dict = {tick_labels_parameter_name: X.columns[perm_sorted_idx]}
ax.boxplot(result.importances[perm_sorted_idx].T, vert=False, **tick_labels_dict)
ax.axvline(x=0, color="k", linestyle="--")
return ax
ثم نقوم بتدريب RandomForestClassifier على
Breast cancer wisconsin (diagnostic) dataset وتقييم دقتها على مجموعة اختبار:
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
X, y = load_breast_cancer(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
print(f"دقة خط الأساس على بيانات الاختبار: {clf.score(X_test, y_test):.2}")
دقة خط الأساس على بيانات الاختبار: 0.97
بعد ذلك، نرسم أهمية الميزة القائمة على الشجرة وأهمية التبديل. يتم حساب أهمية التبديل على مجموعة التدريب لإظهار مدى اعتماد النموذج على كل ميزة أثناء التدريب.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
mdi_importances = pd.Series(clf.feature_importances_, index=X_train.columns)
tree_importance_sorted_idx = np.argsort(clf.feature_importances_)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
mdi_importances.sort_values().plot.barh(ax=ax1)
ax1.set_xlabel("أهمية جيني")
plot_permutation_importance(clf, X_train, y_train, ax2)
ax2.set_xlabel("انخفاض في درجة الدقة")
fig.suptitle(
"أهميات قائمة على النقاء مقابل أهميات التبديل على الميزات متعددة الخطية (مجموعة التدريب)"
)
_ = fig.tight_layout()
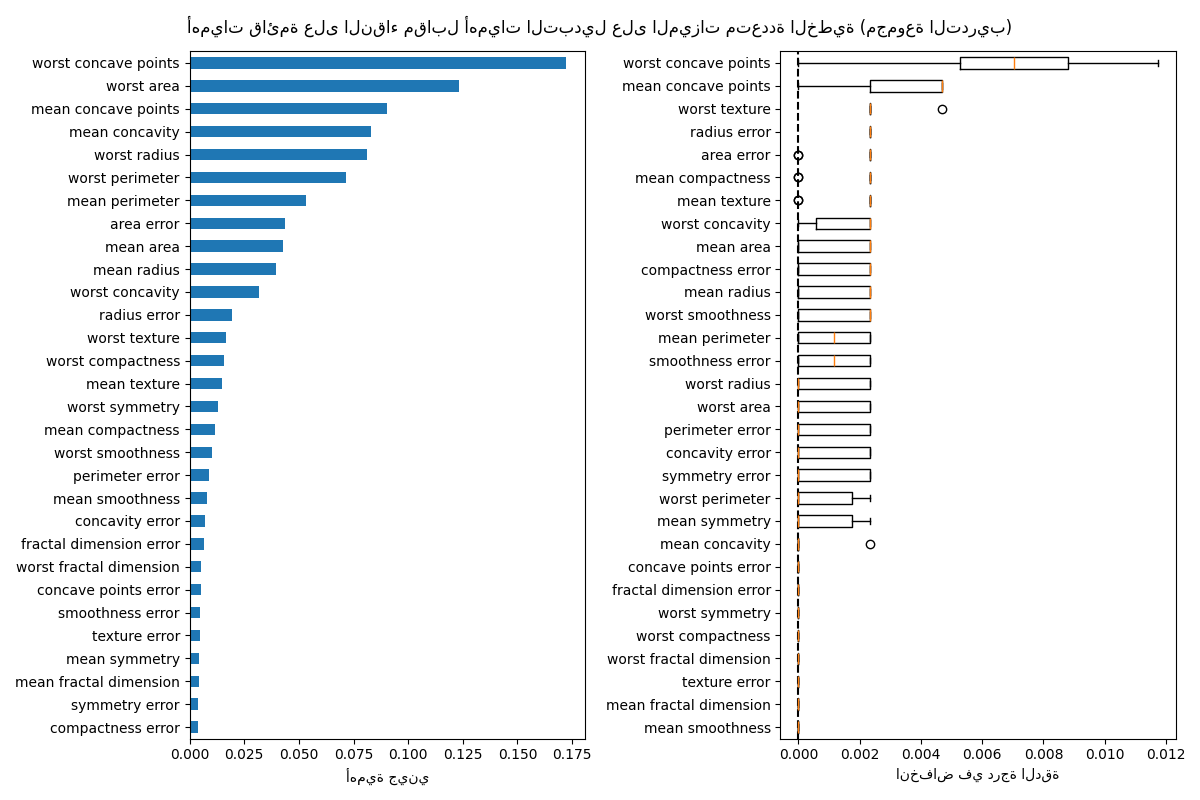
يُظهر الرسم البياني على اليسار أهمية جيني للنموذج. باعتبار تطبيق scikit-learn لـ
RandomForestClassifier يستخدم مجموعات فرعية عشوائية من
\(\sqrt{n_\text{features}}\) ميزات عند كل تقسيم، فإنه قادر على تخفيف
هيمنة أي ميزة مرتبطة واحدة. نتيجة لذلك، قد يتم توزيع أهمية الميزة
الفردية بشكل متساوٍ بين الميزات المرتبطة. نظرًا لأن الميزات لها عدد كبير
والنموذج غير مُفرط التخصيص، يمكننا الوثوق بهذه القيم نسبيًا.
تُظهر أهمية التبديل على الرسم البياني الأيمن أن تبديل ميزة
يؤدي إلى انخفاض الدقة بمقدار 0.012 على الأكثر، مما يشير إلى أنه لا توجد أي من
الميزات مهمة. هذا يتعارض مع دقة الاختبار العالية
المحسوبة كخط أساس: يجب أن تكون بعض الميزات مهمة.
وبالمثل، يبدو أن التغيير في درجة الدقة المحسوبة على مجموعة الاختبار مدفوع بالصدفة:
fig, ax = plt.subplots(figsize=(7, 6))
plot_permutation_importance(clf, X_test, y_test, ax)
ax.set_title("أهميات التبديل على الميزات متعددة الخطية\n(مجموعة الاختبار)")
ax.set_xlabel("انخفاض في درجة الدقة")
_ = ax.figure.tight_layout()
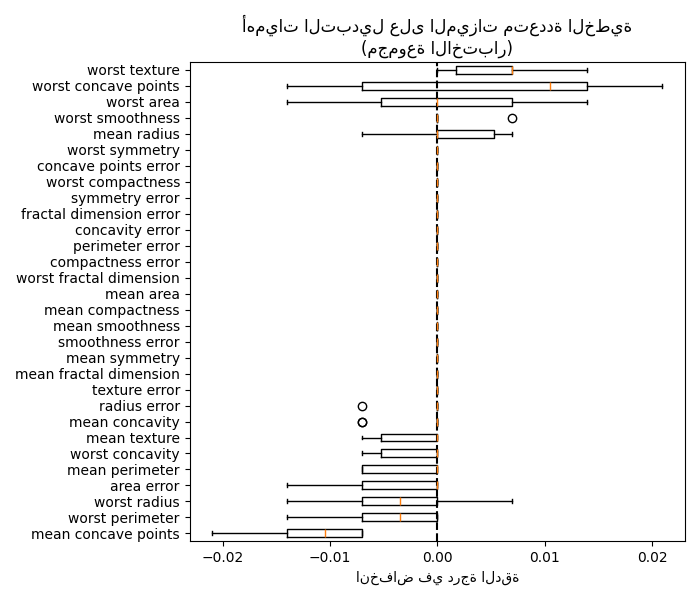
ومع ذلك، لا يزال بإمكان المرء حساب أهمية تبديل ذات مغزى في وجود ميزات مرتبطة، كما هو موضح في القسم التالي.
معالجة الميزات متعددة الخطية#
عندما تكون الميزات متعددة الخطية، فإن تبديل ميزة واحدة له تأثير ضئيل على أداء النماذج لأنه يمكنه الحصول على نفس المعلومات من ميزة مرتبطة. لاحظ أن هذا ليس هو الحال بالنسبة لجميع النماذج التنبؤية ويعتمد على تطبيقها الأساسي.
تتمثل إحدى طرق معالجة الميزات متعددة الخطية في إجراء تجميع هرمي على ارتباطات Spearman ذات الترتيب الرتبي، واختيار عتبة، والاحتفاظ بميزة واحدة من كل مجموعة. أولاً، نرسم خريطة حرارية للميزات المرتبطة:
from scipy.cluster import hierarchy
from scipy.spatial.distance import squareform
from scipy.stats import spearmanr
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
corr = spearmanr(X).correlation
# تأكد من أن مصفوفة الارتباط متماثلة
corr = (corr + corr.T) / 2
np.fill_diagonal(corr, 1)
# نقوم بتحويل مصفوفة الارتباط إلى مصفوفة مسافة قبل إجراء
# التجميع الهرمي باستخدام ارتباط Ward.
distance_matrix = 1 - np.abs(corr)
dist_linkage = hierarchy.ward(squareform(distance_matrix))
dendro = hierarchy.dendrogram(
dist_linkage, labels=X.columns.to_list(), ax=ax1, leaf_rotation=90
)
dendro_idx = np.arange(0, len(dendro["ivl"]))
ax2.imshow(corr[dendro["leaves"], :][:, dendro["leaves"]])
ax2.set_xticks(dendro_idx)
ax2.set_yticks(dendro_idx)
ax2.set_xticklabels(dendro["ivl"], rotation="vertical")
ax2.set_yticklabels(dendro["ivl"])
_ = fig.tight_layout()
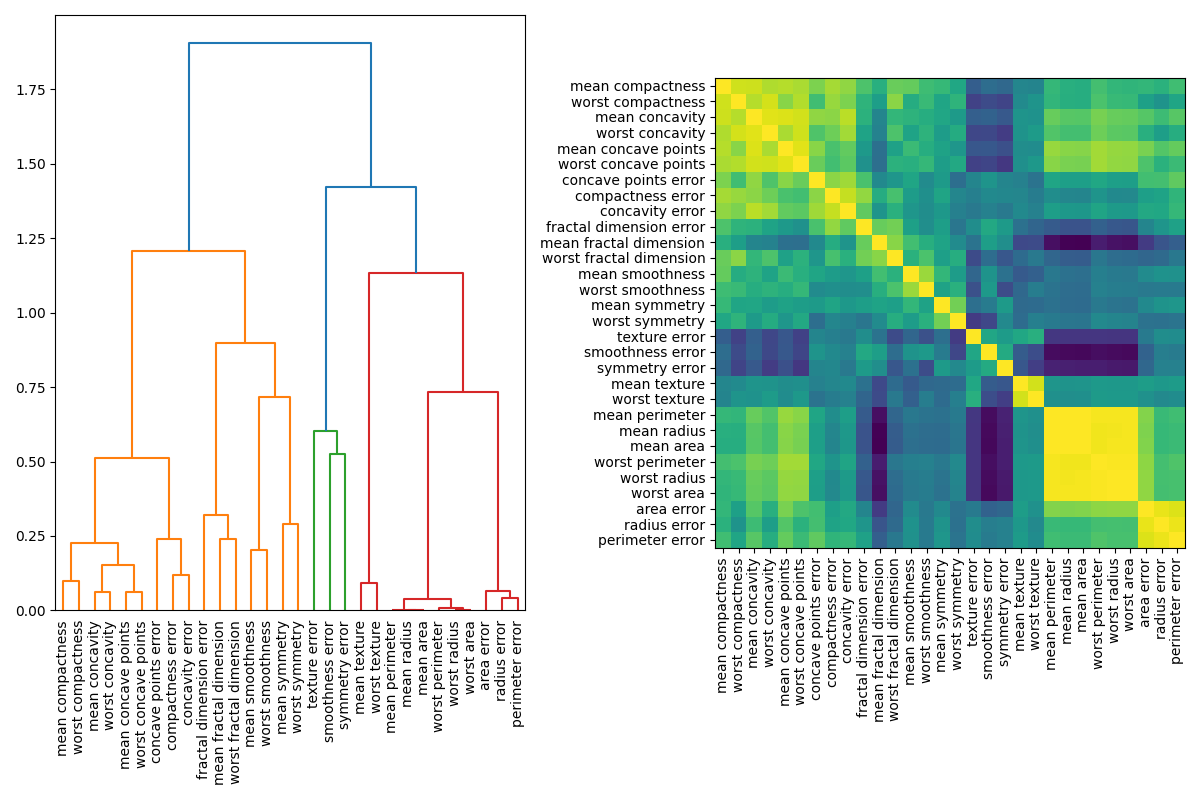
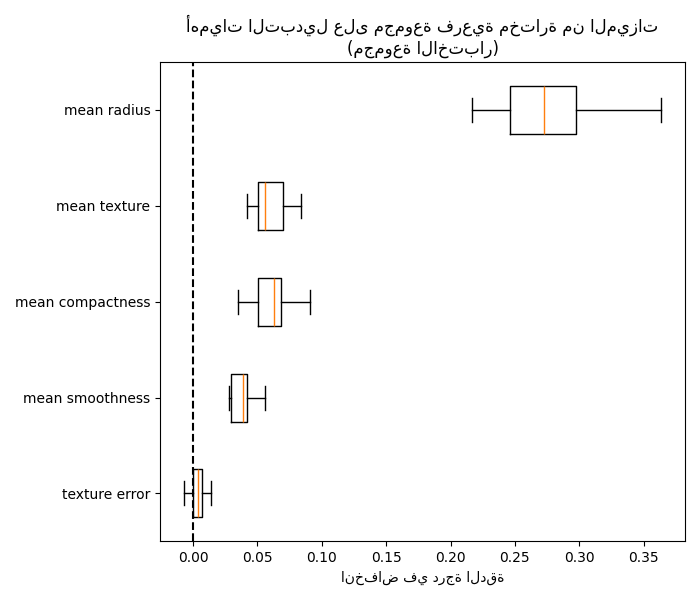
بعد ذلك، نقوم يدويًا باختيار عتبة عن طريق الفحص البصري للشجرة التجميعية لتجميع ميزاتنا في مجموعات واختيار ميزة من كل مجموعة للاحتفاظ بها، وتحديد هذه الميزات من مجموعة البيانات الخاصة بنا، وتدريب غابة عشوائية جديدة. لم تتغير دقة الاختبار للغابة العشوائية الجديدة كثيرًا مقارنة بالغابة العشوائية المدربة على مجموعة البيانات الكاملة.
from collections import defaultdict
cluster_ids = hierarchy.fcluster(dist_linkage, 1, criterion="distance")
cluster_id_to_feature_ids = defaultdict(list)
for idx, cluster_id in enumerate(cluster_ids):
cluster_id_to_feature_ids[cluster_id].append(idx)
selected_features = [v[0] for v in cluster_id_to_feature_ids.values()]
selected_features_names = X.columns[selected_features]
X_train_sel = X_train[selected_features_names]
X_test_sel = X_test[selected_features_names]
clf_sel = RandomForestClassifier(n_estimators=100, random_state=42)
clf_sel.fit(X_train_sel, y_train)
print(
"دقة خط الأساس على بيانات الاختبار مع إزالة الميزات:"
f" {clf_sel.score(X_test_sel, y_test):.2}"
)
دقة خط الأساس على بيانات الاختبار مع إزالة الميزات: 0.97
يمكننا أخيرًا استكشاف أهمية تبديل المجموعة الفرعية المحددة من الميزات:
fig, ax = plt.subplots(figsize=(7, 6))
plot_permutation_importance(clf_sel, X_test_sel, y_test, ax)
ax.set_title("أهميات التبديل على مجموعة فرعية مختارة من الميزات\n(مجموعة الاختبار)")
ax.set_xlabel("انخفاض في درجة الدقة")
ax.figure.tight_layout()
plt.show()
Total running time of the script: (0 minutes 7.188 seconds)
Related examples
أهمية التبديل مقابل أهمية ميزة الغابة العشوائية (MDI)