ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أهمية الميزات باستخدام غابة من الأشجار#
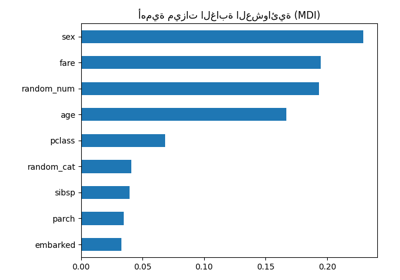
هذا المثال يوضح استخدام غابة من الأشجار لتقييم أهمية الميزات في مهمة تصنيف اصطناعية. تمثل الأعمدة الزرقاء أهمية الميزات للغابة، إلى جانب تباينها بين الأشجار الذي يمثله خطأ الأعمدة.
كما هو متوقع، يوضح الرسم البياني أن 3 ميزات مفيدة، في حين أن الميزات المتبقية ليست كذلك.
# المؤلفون: مطوري سكايت-ليرن
# معرف الترخيص: BSD-3-Clause
import matplotlib.pyplot as plt
توليد البيانات وتناسب النموذج#
نقوم بتوليد مجموعة بيانات اصطناعية تحتوي على 3 ميزات مفيدة فقط. لن نقوم بخلط المجموعة بشكل صريح لضمان أن الميزات المفيدة ستتوافق مع الأعمدة الثلاثة الأولى من X. بالإضافة إلى ذلك، سنقوم بتقسيم مجموعة البيانات الخاصة بنا إلى مجموعات فرعية للتدريب والاختبار.
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=10,
n_informative=3,
n_redundant=0,
n_repeated=0,
n_classes=2,
random_state=0,
shuffle=False,
)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
سيتم تناسب مصنف غابة عشوائية لحساب أهمية الميزات.
from sklearn.ensemble import RandomForestClassifier
feature_names = [f"feature {i}" for i in range(X.shape[1])]
forest = RandomForestClassifier(random_state=0)
forest.fit(X_train, y_train)
أهمية الميزة بناءً على الانخفاض المتوسط في عدم النقاء#
يتم توفير أهمية الميزات بواسطة الخاصية المناسبة
feature_importances_ ويتم حسابها كمتوسط وانحراف معياري
تراكم انخفاض عدم النقاء داخل كل شجرة.
تحذير
يمكن أن تكون أهمية الميزات القائمة على عدم النقاء مضللة للميزات ذات الارتفاع cardinality (العديد من القيم الفريدة). راجع أهمية التبديل كبديل أدناه.
Elapsed time to compute the importances: 0.009 seconds
دعنا نرسم أهمية الانخفاض في عدم النقاء.
import pandas as pd
forest_importances = pd.Series(importances, index=feature_names)
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=std, ax=ax)
ax.set_title("Feature importances using MDI")
ax.set_ylabel("Mean decrease in impurity")
fig.tight_layout()
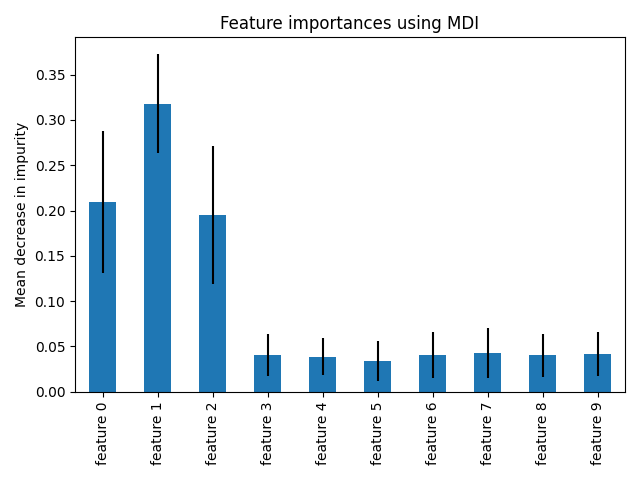
نلاحظ أنه، كما هو متوقع، يتم العثور على الميزات الثلاثة الأولى كأهمية.
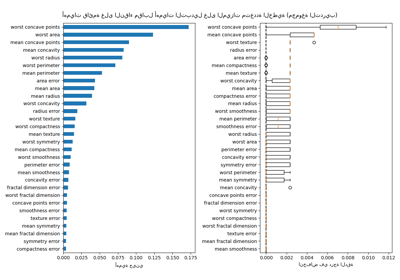
أهمية الميزة بناءً على تبديل الميزة#
تتجاوز أهمية الميزة بالتبديل قيود أهمية الميزة القائمة على عدم النقاء: فهي لا تحتوي على تحيز نحو الميزات ذات cardinality العالي ويمكن حسابها على مجموعة اختبار مستبعدة.
from sklearn.inspection import permutation_importance
start_time = time.time()
result = permutation_importance(
forest, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
elapsed_time = time.time() - start_time
print(f"Elapsed time to compute the importances: {elapsed_time:.3f} seconds")
forest_importances = pd.Series(result.importances_mean, index=feature_names)
Elapsed time to compute the importances: 0.799 seconds
الحساب لأهمية التبديل الكامل أكثر تكلفة. يتم خلط الميزات n مرات ويتم إعادة تناسب النموذج لتقدير أهمية ذلك. يرجى الاطلاع على أهمية التبديل لمزيد من التفاصيل. يمكننا الآن رسم ترتيب الأهمية.
fig, ax = plt.subplots()
forest_importances.plot.bar(yerr=result.importances_std, ax=ax)
ax.set_title("Feature importances using permutation on full model")
ax.set_ylabel("Mean accuracy decrease")
fig.tight_layout()
plt.show()
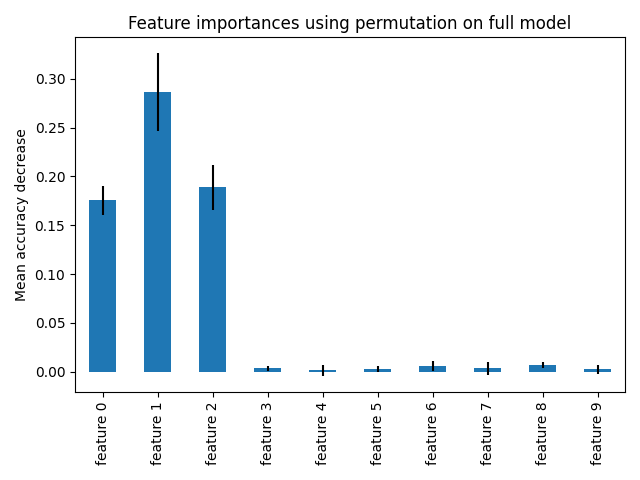
يتم اكتشاف نفس الميزات كأهمية باستخدام كلتا الطريقتين. على الرغم من تختلف الأهمية النسبية. كما هو موضح في الرسوم البيانية، MDI أقل احتمالا من أهمية التبديل لإغفال ميزة تمامًا.
Total running time of the script: (0 minutes 1.326 seconds)
Related examples
أهمية التبديل مقابل أهمية ميزة الغابة العشوائية (MDI)
أهمية التبديل مع الميزات متعددة الخطية أو المرتبطة