ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أقرب النقاط المجاورة التقريبية في TSNE#
يقدم هذا المثال كيفية ربط KNeighborsTransformer و TSNE في خط أنابيب.
كما يُظهر كيفية تغليف الحزم nmslib و pynndescent لاستبدال
KNeighborsTransformer وأداء أقرب النقاط المجاورة التقريبية. يمكن تثبيت هذه الحزم
باستخدام pip install nmslib pynndescent.
ملاحظة: في KNeighborsTransformer نستخدم التعريف الذي يتضمن كل
نقطة تدريب كجارتها الخاصة في حساب n_neighbors, ولأسباب التوافق, يتم حساب جار إضافي واحد
عندما mode == 'distance'. يرجى ملاحظة أننا نفعل الشيء نفسه في
غلاف nmslib المقترح.
# المؤلفون: مطوري scikit-learn
# SPDX-License-Identifier: BSD-3-Clause
أولاً, نحاول استيراد الحزم وتحذير المستخدم في حالة عدم توفرها.
نحن نحدد فئة غلاف لتنفيذ واجهة برمجة التطبيقات scikit-learn إلى
nmslib, بالإضافة إلى دالة تحميل.
import joblib
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
class NMSlibTransformer (TransformerMixin, BaseEstimator):
"""غلاف لاستخدام nmslib كـ KNeighborsTransformer لـ sklearn"""
def __init__(self, n_neighbors=5, metric="euclidean", method="sw-graph", n_jobs=-1):
self.n_neighbors = n_neighbors
self.method = method
self.metric = metric
self.n_jobs = n_jobs
def fit(self, X):
self.n_samples_fit_ = X.shape[0]
# راجع المزيد من المقاييس في الدليل
# https://github.com/nmslib/nmslib/tree/master/manual
space = {
"euclidean": "l2",
"cosine": "cosinesimil",
"l1": "l1",
"l2": "l2",
}[self.metric]
self.nmslib_ = nmslib.init(method=self.method, space=space)
self.nmslib_.addDataPointBatch(X.copy())
self.nmslib_.createIndex()
return self
def transform(self, X):
n_samples_transform = X.shape[0]
# لأسباب التوافق, حيث يتم اعتبار كل عينة كجارتها الخاصة,
# سيتم حساب جار إضافي واحد.
n_neighbors = self.n_neighbors + 1
if self.n_jobs < 0:
# نفس المعالجة كما هو مكتوب في joblib للقيم السلبية من n_jobs:
# على وجه الخصوص, `n_jobs == -1` يعني "بقدر ما هو متاح من المعالجات".
num_threads = joblib.cpu_count() + self.n_jobs + 1
else:
num_threads = self.n_jobs
results = self.nmslib_.knnQueryBatch(
X.copy(), k=n_neighbors, num_threads=num_threads
)
indices, distances = zip(*results)
indices, distances = np.vstack(indices), np.vstack(distances)
indptr = np.arange(0, n_samples_transform * n_neighbors + 1, n_neighbors)
kneighbors_graph = csr_matrix(
(distances.ravel(), indices.ravel(), indptr),
الشكل=(n_samples_transform, self.n_samples_fit_),
)
return kneighbors_graph
def load_mnist(n_samples):
"""تحميل MNIST, وخلط البيانات, وإرجاع n_samples فقط."""
mnist = fetch_openml("mnist_784", as_frame=False)
X, y = shuffle(mnist.data, mnist.target, random_state=2)
return X[:n_samples] / 255, y[:n_samples]
نحن نقيس أداء المحولات المختلفة لأقرب النقاط المجاورة الدقيقة/التقريبية.
import time
from sklearn.manifold import TSNE
from sklearn.neighbors import KNeighborsTransformer
from sklearn.pipeline import make_pipeline
datasets = [
("MNIST_10000", load_mnist(n_samples=10_000)),
("MNIST_20000", load_mnist(n_samples=20_000)),
]
n_iter = 500
perplexity = 30
metric = "euclidean"
# تتطلب TSNE عددًا معينًا من الجيران يعتمد على
# معلمة perplexity.
# أضف واحدًا حيث يتم تضمين كل عينة كجارتها الخاصة.
n_neighbors = int(3.0 * perplexity + 1) + 1
tsne_params = dict(
init="random", # pca غير مدعوم للمصفوفات المتناثرة
perplexity=perplexity,
method="barnes_hut",
random_state=42,
n_iter=n_iter,
learning_rate="auto",
)
transformers = [
(
"KNeighborsTransformer",
KNeighborsTransformer(n_neighbors=n_neighbors, mode="distance", metric=metric),
),
(
"NMSlibTransformer",
NMSlibTransformer(n_neighbors=n_neighbors, metric=metric),
),
(
"PyNNDescentTransformer",
PyNNDescentTransformer(
n_neighbors=n_neighbors, metric=metric, parallel_batch_queries=True
),
),
]
for dataset_name, (X, y) in datasets:
msg = f"قياس الأداء على {dataset_name}:"
print (f"\n{msg}\n" + str("-" * len(msg)))
for transformer_name, transformer in المحولات:
longest = np.max([len(name) for name, model in transformer])
start = time.time()
transformer.fit(X)
fit_duration = time.time() - start
print (f"{transformer_name:<{longest}} {fit_duration:.3f} sec (fit)")
start = time.time()
Xt = transformer.transform(X)
transform_duration = time.time() - start
print (f"{transformer_name:<{longest}} {transform_duration:.3f} sec (transform)")
if transformer_name == "PyNNDescentTransformer":
start = time.time()
Xt = transformer.transform(X)
transform_duration = time.time() - start
print (
f"{transformer_name:<{longest}} {transform_duration:.3f} sec"
" (transform)"
)
إخراج العينة:
قياس الأداء على MNIST_10000:
----------------------------
KNeighborsTransformer 0.007 sec (fit)
KNeighborsTransformer 1.139 sec (transform)
NMSlibTransformer 0.208 sec (fit)
NMSlibTransformer 0.315 sec (transform)
PyNNDescentTransformer 4.823 sec (fit)
PyNNDescentTransformer 4.884 sec (transform)
PyNNDescentTransformer 0.744 sec (transform)
قياس الأداء على MNIST_20000:
----------------------------
KNeighborsTransformer 0.011 sec (fit)
KNeighborsTransformer 5.769 sec (transform)
NMSlibTransformer 0.733 sec (fit)
NMSlibTransformer 1.077 sec (transform)
PyNNDescentTransformer 14.448 sec (fit)
PyNNDescentTransformer 7.103 sec (transform)
PyNNDescentTransformer 1.759 sec (transform)
لاحظ أن PyNNDescentTransformer يستغرق وقتًا أطول خلال أول
fit و transform الأول بسبب النفقات العامة لمترجم numba just in time
لكن بعد المكالمة الأولى, يتم الاحتفاظ بالرمز المترجم بلغة بايثون في
ذاكرة التخزين المؤقت بواسطة numba والمكالمات اللاحقة لا تعاني من هذه النفقات العامة الأولية.
يتم تشغيل كل من KNeighborsTransformer و NMSlibTransformer
مرة واحدة فقط هنا حيث سيظهرون أوقات fit و transform أكثر استقرارًا (لا يعانون من مشكلة بدء التشغيل البارد لـ PyNNDescentTransformer).
import matplotlib.pyplot as plt
from matplotlib.ticker import NullFormatter
transforms = [
("TSNE مع NearestNeighbors الداخلي", TSNE(metric=metric, **tsne_params)),
(
"TSNE مع KNeighborsTransformer",
make_pipeline(
KNeighborsTransformer(
n_neighbors=n_neighbors, mode="distance", metric=metric
),
TSNE(metric="precomputed", **tsne_params),
),
),
(
"TSNE مع NMSlibTransformer",
make_pipeline(
NMSlibTransformer(n_neighbors=n_neighbors, metric=metric),
TSNE(metric="precomputed", **tsne_params),
),
),
]
# بدء الرسم
nrows = len(datasets)
ncols = np.sum([1 for name, model in transformers if "TSNE" in name])
fig, axes = plt.subplots(
nrows=nrows, ncols=ncols, squeeze=False, figsize=(5 * ncols, 4 * nrows)
)
axes = axes.ravel()
i_ax = 0
for dataset_name, (X, y) in datasets:
msg = f"Benchmarking on {dataset_name}:"
print(f"\n{msg}\n" + str("-" * len(msg)))
for transformer_name, transformer in transformers:
longest = np.max([len(name) for name, model in transformers])
start = time.time()
Xt = transformer.fit_transform(X)
transform_duration = time.time() - start
print(
f"{transformer_name:<{longest}} {transform_duration:.3f} sec"
" (fit_transform)"
)
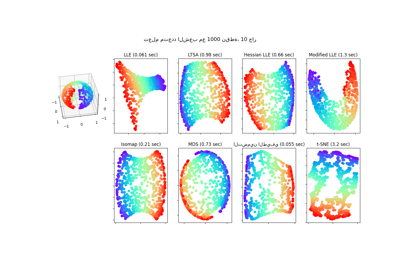
# plot TSNE embedding which should be very similar across methods
axes[i_ax].set_title(transformer_name + "\non " + dataset_name)
axes[i_ax].scatter(
Xt[:, 0],
Xt[:, 1],
c=y.astype(np.int32),
alpha=0.2,
cmap=plt.cm.viridis,
)
axes[i_ax].xaxis.set_major_formatter(NullFormatter())
axes[i_ax].yaxis.set_major_formatter(NullFormatter())
axes[i_ax].axis("tight")
i_ax += 1
fig.tight_layout()
plt.show()
إخراج العينة:
قياس الأداء على MNIST_10000:
----------------------------
TSNE مع NearestNeighbors الداخلي 24.828 sec (fit_transform)
TSNE مع KNeighborsTransformer 20.111 sec (fit_transform)
TSNE مع NMSlibTransformer 21.757 sec (fit_transform)
قياس الأداء على MNIST_20000:
----------------------------
TSNE مع NearestNeighbors الداخلي 51.955 sec (fit_transform)
TSNE مع KNeighborsTransformer 50.994 sec (fit_transform)
TSNE مع NMSlibTransformer 43.536 sec (fit_transform)
يمكننا ملاحظة أن المحول الافتراضي TSNE مع
التنفيذ الداخلي لـ NearestNeighbors هو
مكافئ تقريبًا لخط الأنابيب مع TSNE و
KNeighborsTransformer من حيث الأداء.
هذا متوقع لأن كلا خطي الأنابيب يعتمدان داخليًا على نفس
التنفيذ NearestNeighbors الذي يقوم
بالبحث الدقيق عن الجيران. البحث التقريبي NMSlibTransformer هو بالفعل
أسرع قليلاً من البحث الدقيق على أصغر مجموعة بيانات ولكن من المتوقع أن يصبح هذا الاختلاف في السرعة
أكثر أهمية في مجموعات البيانات ذات العدد الأكبر من العينات.
لاحظ مع ذلك أن ليس كل طرق البحث التقريبية مضمونة
لتحسين سرعة طريقة البحث الدقيقة الافتراضية: في الواقع, تحسنت طريقة البحث الدقيقة بشكل كبير
منذ scikit-learn 1.1. علاوة على ذلك, لا تتطلب طريقة البحث الدقيقة "brute-force" بناء فهرس في وقت fit.
لذلك, للحصول على تحسن عام في الأداء في سياق خط أنابيب
TSNE, يجب أن تكون المكاسب في البحث التقريبي في transform
أكبر من الوقت الإضافي الذي يتم إنفاقه لبناء فهرس البحث التقريبي في وقت fit.
أخيرًا, خوارزمية TSNE نفسها كثيفة الحسابات, بغض النظر عن البحث عن أقرب الجيران. لذلك, لن يؤدي تسريع خطوة البحث عن أقرب الجيران إلى تسريع خط الأنابيب بمقدار 5 مرات.
Related examples