ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تقديم واجهة برمجة التطبيقات set_output#
هذا المثال سيوضح واجهة برمجة التطبيقات set_output لتكوين المحولات لإخراج إطارات بيانات باندا. يمكن تكوين set_output لكل مقدر عن طريق استدعاء طريقة set_output أو بشكل عام عن طريق تعيين set_config(transform_output="pandas"). للحصول على التفاصيل، راجع SLEP018.
أولاً، نقوم بتحميل مجموعة بيانات إيريس كإطار بيانات لإظهار واجهة برمجة التطبيقات set_output.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
X, y = load_iris(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
X_train.head()
لتكوين مقدر مثل preprocessing.StandardScaler لإرجاع
إطارات البيانات، استدع set_output. تتطلب هذه الميزة تثبيت باندا.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler().set_output(transform="pandas")
scaler.fit(X_train)
X_test_scaled = scaler.transform(X_test)
X_test_scaled.head()
يمكن استدعاء set_output بعد fit لتكوين transform بعد ذلك.
scaler2 = StandardScaler()
scaler2.fit(X_train)
X_test_np = scaler2.transform(X_test)
print(f"نوع الإخراج الافتراضي: {type(X_test_np).__name__}")
scaler2.set_output(transform="pandas")
X_test_df = scaler2.transform(X_test)
print(f"نوع الإخراج المُهيأ من باندا: {type(X_test_df).__name__}")
نوع الإخراج الافتراضي: ndarray
نوع الإخراج المُهيأ من باندا: DataFrame
في pipeline.Pipeline، يقوم set_output بتكوين جميع الخطوات لإخراج
إطارات البيانات.
from sklearn.feature_selection import SelectPercentile
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
clf = make_pipeline(
StandardScaler(), SelectPercentile(percentile=75), LogisticRegression()
)
clf.set_output(transform="pandas")
clf.fit(X_train, y_train)
يتم تكوين كل محول في خط الأنابيب لإرجاع إطارات البيانات. هذا يعني أن خطوة الانحدار اللوجستي النهائي تحتوي على أسماء ميزات الإدخال.
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
ملاحظة
إذا استخدم المرء طريقة set_params، فسيتم استبدال المحول
بآخر بتنسيق الإخراج الافتراضي.
clf.set_params(standardscaler=StandardScaler())
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['x0', 'x2', 'x3'], dtype=object)
للحفاظ على السلوك المقصود، استخدم set_output على المحول الجديد
مسبقاً
scaler = StandardScaler().set_output(transform="pandas")
clf.set_params(standardscaler=scaler)
clf.fit(X_train, y_train)
clf[-1].feature_names_in_
array(['sepal length (cm)', 'petal length (cm)', 'petal width (cm)'],
dtype=object)
بعد ذلك، نقوم بتحميل مجموعة بيانات تيتانيك لإظهار set_output مع
compose.ColumnTransformer والبيانات غير المتجانسة.
from sklearn.datasets import fetch_openml
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
يمكن تكوين واجهة برمجة التطبيقات set_output بشكل عام باستخدام set_config و
تعيين transform_output إلى "pandas".
from sklearn import set_config
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
set_config(transform_output="pandas")
num_pipe = make_pipeline(SimpleImputer(), StandardScaler())
num_cols = ["age", "fare"]
ct = ColumnTransformer(
(
("numerical", num_pipe, num_cols),
(
"categorical",
OneHotEncoder(
sparse_output=False, drop="if_binary", handle_unknown="ignore"
),
["embarked", "sex", "pclass"],
),
),
verbose_feature_names_out=False,
)
clf = make_pipeline(ct, SelectPercentile(percentile=50), LogisticRegression())
clf.fit(X_train, y_train)
clf.score(X_test, y_test)
0.7804878048780488
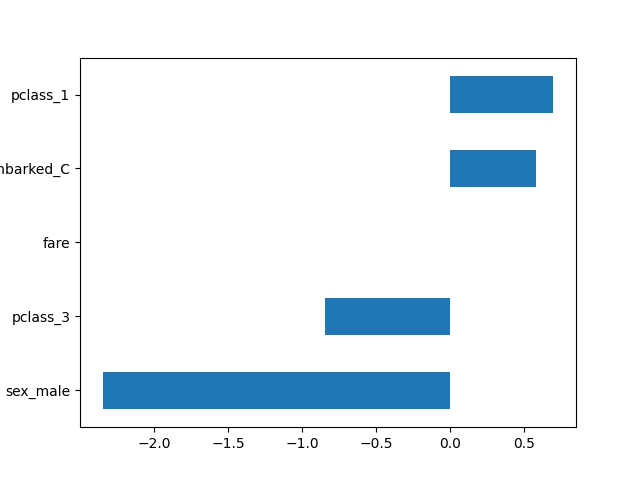
مع التهيئة العامة، تخرج جميع المحولات إطارات بيانات. هذا يسمح لنا بسهولة رسم معاملات الانحدار اللوجستي مع أسماء الميزات المقابلة.
import pandas as pd
log_reg = clf[-1]
coef = pd.Series(log_reg.coef_.ravel(), index=log_reg.feature_names_in_)
_ = coef.sort_values().plot.barh()
من أجل توضيح وظيفة config_context أدناه، دعنا
أولاً إعادة تعيين transform_output إلى قيمته الافتراضية.
set_config(transform_output="default")
عند تكوين نوع الإخراج باستخدام config_context فإن
التهيئة في الوقت الذي يتم فيه استدعاء transform أو fit_transform هي ما يهم. تعيين هذه فقط عند إنشاء أو تكييف
المحول ليس له أي تأثير.
from sklearn import config_context
scaler = StandardScaler()
scaler.fit(X_train[num_cols])
with config_context(transform_output="pandas"):
# سيكون إخراج التحويل إطار بيانات باندا
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled.head()
خارج مدير السياق، سيكون الإخراج مصفوفة نومبي
X_test_scaled = scaler.transform(X_test[num_cols])
X_test_scaled[:5]
array([[ 0.14, 0.45],
[ 0.63, -0.08],
[ 0.42, -0.52],
[ nan, 0.17],
[-0.84, -0.51]])
Total running time of the script: (0 minutes 0.191 seconds)
Related examples