ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
التصنيف شبه المُشرف على مجموعة بيانات نصية#
في هذا المثال، يتم تدريب المصنفات شبه المُشرفة على مجموعة بيانات 20 مجموعة إخبارية (والتي سيتم تنزيلها تلقائيًا).
يمكنك ضبط عدد الفئات عن طريق إعطاء أسمائها إلى محمل مجموعة البيانات أو تعيينها إلى 'None' للحصول على جميع الفئات العشرين.
2823 documents
5 categories
Supervised SGDClassifier on 100% of the data:
Number of training samples: 2117
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.880
----------
Supervised SGDClassifier on 20% of the training data:
Number of training samples: 422
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.738
----------
SelfTrainingClassifier on 20% of the training data (rest is unlabeled):
Number of training samples: 2117
Unlabeled samples in training set: 1695
End of iteration 1, added 1115 new labels.
End of iteration 2, added 193 new labels.
End of iteration 3, added 50 new labels.
End of iteration 4, added 25 new labels.
End of iteration 5, added 9 new labels.
End of iteration 6, added 8 new labels.
End of iteration 7, added 5 new labels.
End of iteration 8, added 3 new labels.
End of iteration 9, added 3 new labels.
End of iteration 10, added 4 new labels.
Micro-averaged F1 score on test set: 0.790
----------
LabelSpreading on 20% of the data (rest is unlabeled):
Number of training samples: 2117
Unlabeled samples in training set: 1695
Micro-averaged F1 score on test set: 0.661
----------
# المؤلفون: مطوري مكتبة ساي كيت ليرن
# معرف الترخيص: BSD-3-Clause
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer
from sklearn.semi_supervised import LabelSpreading, SelfTrainingClassifier
# تحميل مجموعة البيانات التي تحتوي على أول خمس فئات
data = fetch_20newsgroups(
subset="train",
categories=[
"alt.atheism",
"comp.graphics",
"comp.os.ms-windows.misc",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
],
)
print("%d documents" % len(data.filenames))
print("%d categories" % len(data.target_names))
print()
# المعاملات
sdg_params = dict(alpha=1e-5, penalty="l2", loss="log_loss")
vectorizer_params = dict(ngram_range=(1, 2), min_df=5, max_df=0.8)
# خط أنابيب مُشرف
pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SGDClassifier(**sdg_params)),
]
)
# خط أنابيب SelfTraining
st_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SelfTrainingClassifier(SGDClassifier(**sdg_params), verbose=True)),
]
)
# خط أنابيب LabelSpreading
ls_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
# LabelSpreading لا يدعم المصفوفات الكثيفة
("toarray", FunctionTransformer(lambda x: x.toarray())),
("clf", LabelSpreading()),
]
)
def eval_and_print_metrics(clf, X_train, y_train, X_test, y_test):
print("Number of training samples:", len(X_train))
print("Unlabeled samples in training set:", sum(1 for x in y_train if x == -1))
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(
"Micro-averaged F1 score on test set: %0.3f"
% f1_score(y_test, y_pred, average="micro")
)
print("-" * 10)
print()
if __name__ == "__main__":
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
print("Supervised SGDClassifier on 100% of the data:")
eval_and_print_metrics(pipeline, X_train, y_train, X_test, y_test)
# تحديد قناع 20% من مجموعة البيانات التدريبية
y_mask = np.random.rand(len(y_train)) < 0.2
# X_20 و y_20 هي مجموعة فرعية من مجموعة البيانات التدريبية المحددة بواسطة القناع
X_20, y_20 = map(
list, zip(*((x, y) for x, y, m in zip(X_train, y_train, y_mask) if m))
)
print("Supervised SGDClassifier on 20% of the training data:")
eval_and_print_metrics(pipeline, X_20, y_20, X_test, y_test)
# تعيين المجموعة الفرعية غير المقنعة لتكون غير مصنفة
y_train[~y_mask] = -1
print("SelfTrainingClassifier on 20% of the training data (rest is unlabeled):")
eval_and_print_metrics(st_pipeline, X_train, y_train, X_test, y_test)
print("LabelSpreading on 20% of the data (rest is unlabeled):")
eval_and_print_metrics(ls_pipeline, X_train, y_train, X_test, y_test)
Total running time of the script: (0 minutes 10.723 seconds)
Related examples

التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك
التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك
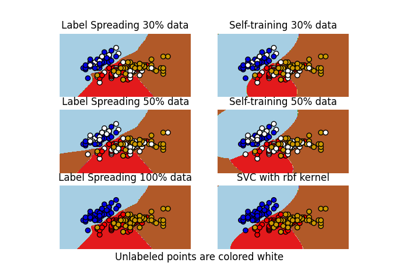
حدود القرار للمصنفات شبه المُشرفة مقابل SVM على مجموعة بيانات Iris
حدود القرار للمصنفات شبه المُشرفة مقابل SVM على مجموعة بيانات Iris