ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تأثير تحويل الأهداف في نموذج الانحدار#
في هذا المثال، نقدم نظرة عامة على
TransformedTargetRegressor. نستخدم مثالين
لتوضيح فائدة تحويل الأهداف قبل تعلم نموذج الانحدار الخطي. يستخدم المثال الأول بيانات اصطناعية بينما يعتمد المثال
الثاني على مجموعة بيانات إسكان إيمز.
# المؤلفون: مطوري سكايت-ليرن
# معرف الترخيص: BSD-3-Clause
from sklearn.preprocessing import QuantileTransformer
from sklearn.preprocessing import quantile_transform
from sklearn.datasets import fetch_openml
from sklearn.metrics import PredictionErrorDisplay
from sklearn.linear_model import RidgeCV
from sklearn.compose import TransformedTargetRegressor
from sklearn.metrics import median_absolute_error, r2_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
import numpy as np
print(__doc__)
مثال اصطناعي#
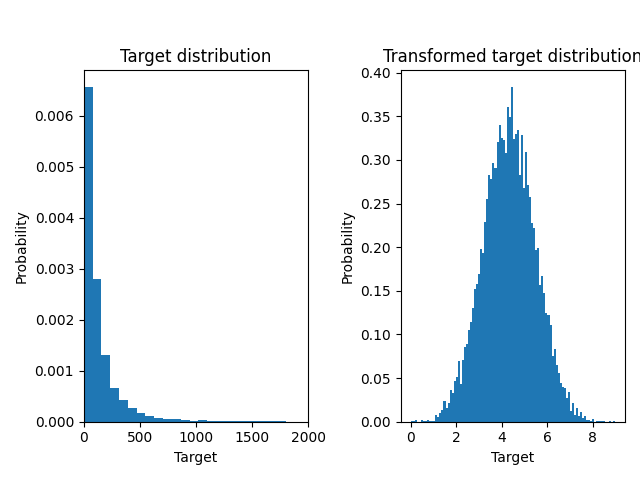
يتم إنشاء مجموعة بيانات تراجعية عشوائية اصطناعية. يتم تعديل الأهداف y
من خلال:
ترجمة جميع الأهداف بحيث تكون جميع الإدخالات غير سلبية (بإضافة القيمة المطلقة لأصغر
y) وتطبيق دالة أسية للحصول على أهداف غير خطية والتي لا يمكن ملاءمتها باستخدام نموذج خطي بسيط.
لذلك، سيتم استخدام دالة لوغاريتمية (np.log1p) ودالة أسية
(np.expm1) لتحويل الأهداف قبل تدريب نموذج الانحدار الخطي
واستخدامه للتنبؤ.
X, y = make_regression(n_samples=10_000, noise=100, random_state=0)
y = np.expm1((y + abs(y.min())) / 200)
y_trans = np.log1p(y)
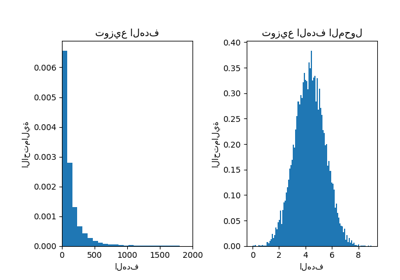
فيما يلي، نرسم دالة الكثافة الاحتمالية للأهداف قبل وبعد تطبيق الدوال اللوغاريتمية.
f, (ax0, ax1) = plt.subplots(1, 2)
ax0.hist(y, bins=100, density=True)
ax0.set_xlim([0, 2000])
ax0.set_ylabel("Probability")
ax0.set_xlabel("Target")
ax0.set_title("Target distribution")
ax1.hist(y_trans, bins=100, density=True)
ax1.set_ylabel("Probability")
ax1.set_xlabel("Target")
ax1.set_title("Transformed target distribution")
f.suptitle("Synthetic data", y=1.05)
plt.tight_layout()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
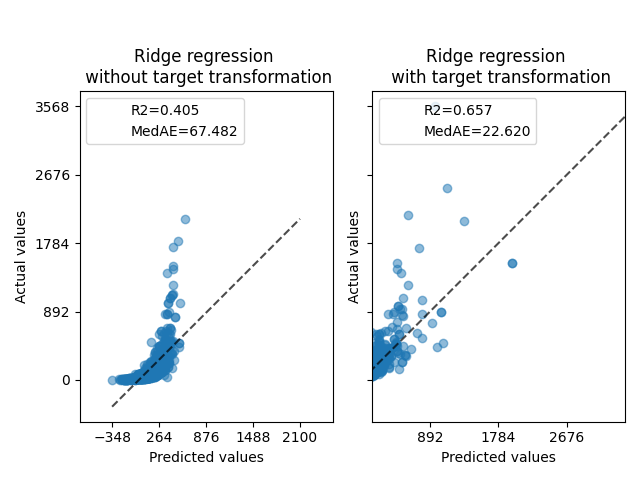
في البداية، سيتم تطبيق نموذج خطي على الأهداف الأصلية. بسبب عدم الخطية، لن يكون النموذج المدرب دقيقاً خلال التنبؤ. بعد ذلك، يتم استخدام دالة لوغاريتمية لخطية الأهداف، مما يسمح بتنبؤ أفضل حتى مع نموذج خطي مشابه كما تم الإبلاغ عنه بواسطة الخطأ المتوسط المطلق (MedAE).
def compute_score(y_true, y_pred):
return {
"R2": f"{r2_score(y_true, y_pred):.3f}",
"MedAE": f"{median_absolute_error(y_true, y_pred):.3f}",
}
f, (ax0, ax1) = plt.subplots(1, 2, sharey=True)
ridge_cv = RidgeCV().fit(X_train, y_train)
y_pred_ridge = ridge_cv.predict(X_test)
ridge_cv_with_trans_target = TransformedTargetRegressor(
regressor=RidgeCV(), func=np.log1p, inverse_func=np.expm1
).fit(X_train, y_train)
y_pred_ridge_with_trans_target = ridge_cv_with_trans_target.predict(X_test)
PredictionErrorDisplay.from_predictions(
y_test,
y_pred_ridge,
kind="actual_vs_predicted",
ax=ax0,
scatter_kwargs={"alpha": 0.5},
)
PredictionErrorDisplay.from_predictions(
y_test,
y_pred_ridge_with_trans_target,
kind="actual_vs_predicted",
ax=ax1,
scatter_kwargs={"alpha": 0.5},
)
# Add the score in the legend of each axis
for ax, y_pred in zip([ax0, ax1], [y_pred_ridge, y_pred_ridge_with_trans_target]):
for name, score in compute_score(y_test, y_pred).items():
ax.plot([], [], " ", label=f"{name}={score}")
ax.legend(loc="upper left")
ax0.set_title("Ridge regression \n without target transformation")
ax1.set_title("Ridge regression \n with target transformation")
f.suptitle("Synthetic data", y=1.05)
plt.tight_layout()
ax0.set_title("Ridge regression \n without target transformation")
ax1.set_title("Ridge regression \n with target transformation")
f.suptitle("Synthetic data", y=1.05)
plt.tight_layout()
مجموعة بيانات واقعية#
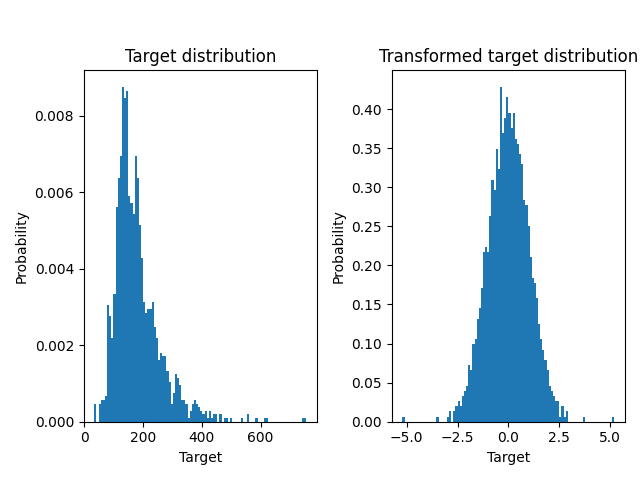
بطريقة مماثلة، يتم استخدام مجموعة بيانات إسكان إيمز لإظهار التأثير لتحويل الأهداف قبل تعلم نموذج. في هذا المثال، الهدف المراد التنبؤ به هو سعر البيع لكل منزل.
ames = fetch_openml(name="house_prices", as_frame=True)
# Keep only numeric columns
X = ames.data.select_dtypes(np.number)
# Remove columns with NaN or Inf values
X = X.drop(columns=["LotFrontage", "GarageYrBlt", "MasVnrArea"])
# Let the price be in k$
y = ames.target / 1000
y_trans = quantile_transform(
y.to_frame(), n_quantiles=900, output_distribution="normal", copy=True
).squeeze()
يتم استخدام QuantileTransformer لتطبيع
توزيع الهدف قبل تطبيق
RidgeCV model.
f, (ax0, ax1) = plt.subplots(1, 2)
ax0.hist(y, bins=100, density=True)
ax0.set_ylabel("Probability")
ax0.set_xlabel("Target")
ax0.set_title("Target distribution")
ax1.hist(y_trans, bins=100, density=True)
ax1.set_ylabel("Probability")
ax1.set_xlabel("Target")
ax1.set_title("Transformed target distribution")
f.suptitle("Ames housing data: selling price", y=1.05)
plt.tight_layout()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
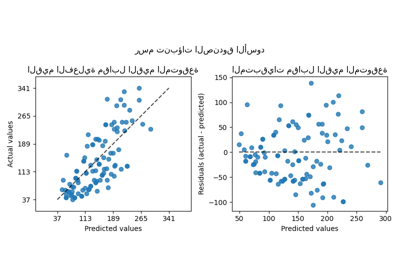
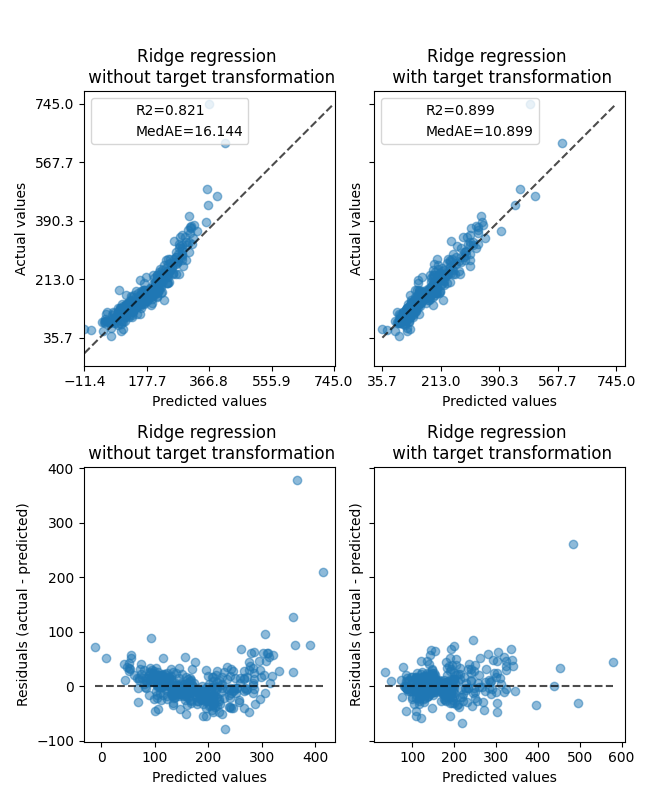
تأثير المحول أضعف من تأثير البيانات الاصطناعية. ومع ذلك، يؤدي التحول إلى زيادة في \(R^2\) وانخفاض كبير في MedAE. يأخذ مخطط البقايا (القيمة المستهدفة المتنبأ بها - القيمة المستهدفة الحقيقية مقابل القيمة المستهدفة المتنبأ بها) بدون تحويل الهدف شكلًا منحنيًا، على شكل "ابتسامة عكسية" بسبب قيم البقايا التي تختلف حسب قيمة الهدف المتنبأ به. مع تحويل الهدف، يكون الشكل أكثر خطية مما يشير إلى ملاءمة أفضل للنموذج.
f, (ax0, ax1) = plt.subplots(2, 2, sharey="row", figsize=(6.5, 8))
ridge_cv = RidgeCV().fit(X_train, y_train)
y_pred_ridge = ridge_cv.predict(X_test)
ridge_cv_with_trans_target = TransformedTargetRegressor(
regressor=RidgeCV(),
transformer=QuantileTransformer(
n_quantiles=900, output_distribution="normal"),
).fit(X_train, y_train)
y_pred_ridge_with_trans_target = ridge_cv_with_trans_target.predict(X_test)
# plot the actual vs predicted values
PredictionErrorDisplay.from_predictions(
y_test,
y_pred_ridge,
kind="actual_vs_predicted",
ax=ax0[0],
scatter_kwargs={"alpha": 0.5},
)
PredictionErrorDisplay.from_predictions(
y_test,
y_pred_ridge_with_trans_target,
kind="actual_vs_predicted",
ax=ax0[1],
scatter_kwargs={"alpha": 0.5},
)
# Add the score in the legend of each axis
for ax, y_pred in zip([ax0[0], ax0[1]], [y_pred_ridge, y_pred_ridge_with_trans_target]):
for name, score in compute_score(y_test, y_pred).items():
ax.plot([], [], " ", label=f"{name}={score}")
ax.legend(loc="upper left")
ax0[0].set_title("Ridge regression \n without target transformation")
ax0[1].set_title("Ridge regression \n with target transformation")
# plot the residuals vs the predicted values
PredictionErrorDisplay.from_predictions(
y_test,
y_pred_ridge,
kind="residual_vs_predicted",
ax=ax1[0],
scatter_kwargs={"alpha": 0.5},
)
PredictionErrorDisplay.from_predictions(
y_test,
y_pred_ridge_with_trans_target,
kind="residual_vs_predicted",
ax=ax1[1],
scatter_kwargs={"alpha": 0.5},
)
ax1[0].set_title("Ridge regression \n without target transformation")
ax1[1].set_title("Ridge regression \n with target transformation")
f.suptitle("Ames housing data: selling price", y=1.05)
plt.tight_layout()
plt.show()
Total running time of the script: (0 minutes 1.644 seconds)
Related examples