ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
التعرف على الأرقام المكتوبة بخط اليد#
هذا المثال يوضح كيفية استخدام scikit-learn للتعرف على صور الأرقام المكتوبة بخط اليد، من 0 إلى 9.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
# استيراد مكتبات بايثون العلمية
import matplotlib.pyplot as plt
# استيراد مجموعات البيانات، والتصنيفات، ومقاييس الأداء
from sklearn import datasets, metrics, svm
from sklearn.model_selection import train_test_split
مجموعة بيانات الأرقام#
تتكون مجموعة بيانات الأرقام من صور بكسل بحجم 8x8. يحتوي خاصية "images" في مجموعة البيانات على مصفوفات 8x8 من قيم التدرج الرمادي لكل صورة. سنستخدم هذه المصفوفات لعرض أول 4 صور. يحتوي خاصية "target" في مجموعة البيانات على الرقم الذي تمثله كل صورة، ويتم تضمينه في عنوان الرسوم البيانية الأربعة أدناه.
ملاحظة: إذا كنا نعمل مع ملفات الصور (مثل ملفات 'png')، فسنقوم بتحميلها باستخدام: func:matplotlib.pyplot.imread.
digits = datasets.load_digits()
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title("Training: %i" % label)

التصنيف#
لتطبيق مصنف على هذه البيانات، نحتاج إلى تسطيح الصور، وتحويل كل مصفوفة 2-D من قيم التدرج الرمادي من الشكل (8, 8) إلى الشكل (64,). وبالتالي، ستكون مجموعة البيانات بأكملها على الشكل (n_samples, n_features)، حيث n_samples هو عدد الصور و n_features هو العدد الإجمالي للبكسلات في كل صورة.
بعد ذلك، يمكننا تقسيم البيانات إلى مجموعتين فرعيتين للتدريب والاختبار وتدريب مصنف ناقل الدعم على عينات التدريب. يمكن استخدام المصنف المدرب بعد ذلك للتنبؤ بقيمة الرقم لعينات مجموعة الاختبار.
# تسطيح الصور
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
# إنشاء مصنف: مصنف ناقل الدعم
clf = svm.SVC(gamma=0.001)
# تقسيم البيانات إلى 50% للتدريب و50% للاختبار
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False
)
# تدريب المصنف على مجموعة التدريب
clf.fit(X_train, y_train)
# التنبؤ بقيمة الرقم في مجموعة الاختبار
predicted = clf.predict(X_test)
نعرض أدناه أول 4 عينات من مجموعة الاختبار ونظهر قيمة الرقم المتوقع في العنوان.
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, prediction in zip(axes, X_test, predicted):
ax.set_axis_off()
image = image.reshape(8, 8)
ax.imshow(image, cmap=plt.cm.gray_r, interpolation="nearest")
ax.set_title(f"Prediction: {prediction}")

classification_report ينشئ تقريراً نصياً يظهر
مقاييس التصنيف الرئيسية.
print(
f"تقرير التصنيف للمصنف {clf}:\n"
f"{metrics.classification_report(y_test, predicted)}\n"
)
تقرير التصنيف للمصنف SVC(gamma=0.001):
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
يمكننا أيضاً رسم مصفوفة الارتباك لل قيم الأرقام الحقيقية والمتنبأ بها.
disp = metrics.ConfusionMatrixDisplay.from_predictions(y_test, predicted)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
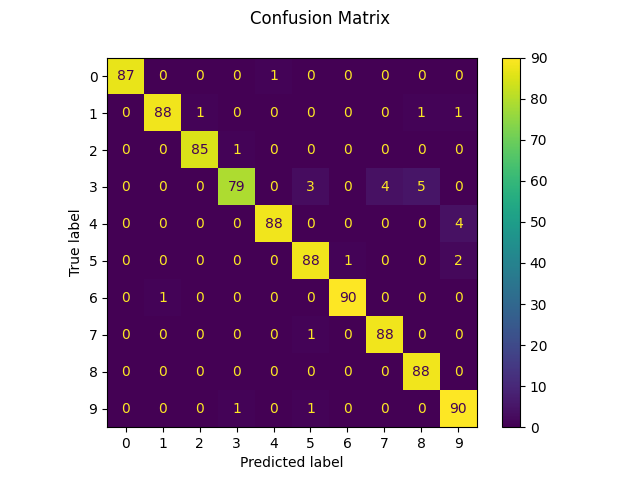
disp = metrics.ConfusionMatrixDisplay.from_predictions(y_test, predicted)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
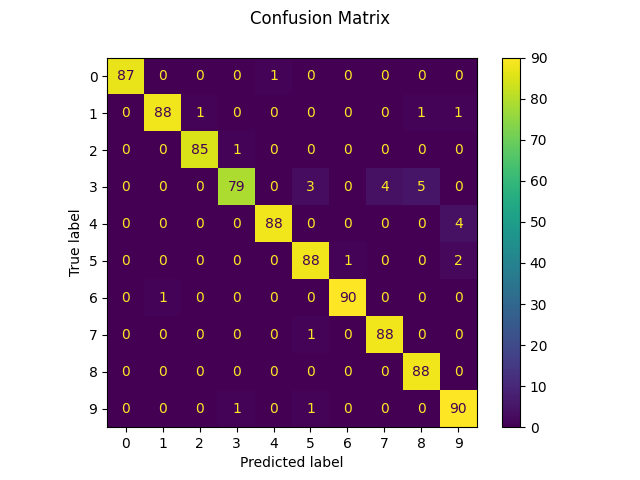
Confusion matrix:
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]
Confusion matrix:
[[87 0 0 0 1 0 0 0 0 0]
[ 0 88 1 0 0 0 0 0 1 1]
[ 0 0 85 1 0 0 0 0 0 0]
[ 0 0 0 79 0 3 0 4 5 0]
[ 0 0 0 0 88 0 0 0 0 4]
[ 0 0 0 0 0 88 1 0 0 2]
[ 0 1 0 0 0 0 90 0 0 0]
[ 0 0 0 0 0 1 0 88 0 0]
[ 0 0 0 0 0 0 0 0 88 0]
[ 0 0 0 1 0 1 0 0 0 90]]
إذا كانت نتائج تقييم المصنف مخزنة على شكل
مصفوفة ارتباك وليس على شكل y_true و
y_pred، يمكننا مع ذلك إنشاء تقرير تصنيف باستخدام: func:~sklearn.metrics.classification_report
كما يلي:
# قوائم القيم الحقيقية والمتنبأ بها
y_true = []
y_pred = []
cm = disp.confusion_matrix
# لكل خلية في مصفوفة الارتباك، أضف القيم الحقيقية والمتنبأ بها
# إلى القوائم
for gt in range(len(cm)):
for pred in range(len(cm)):
y_true += [gt] * cm[gt][pred]
y_pred += [pred] * cm[gt][pred]
print(
"تقرير التصنيف المعاد بناؤه من مصفوفة الارتباك:\n"
f"{metrics.classification_report(y_true, y_pred)}\n"
)
تقرير التصنيف المعاد بناؤه من مصفوفة الارتباك:
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
Total running time of the script: (0 minutes 0.770 seconds)
Related examples