ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
القيود الرتيبة#
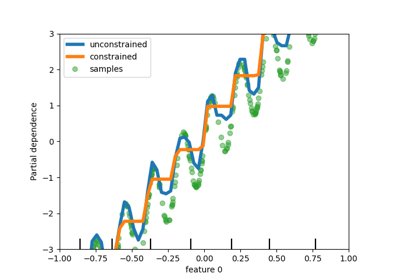
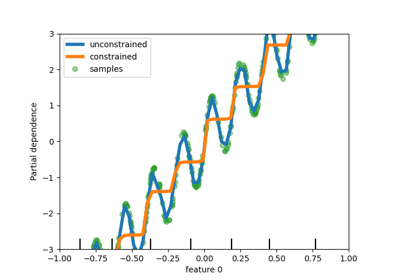
يوضح هذا المثال تأثير القيود الرتيبة على مقدر التعزيز المتدرج.
نقوم ببناء مجموعة بيانات اصطناعية حيث تكون قيمة الهدف بشكل عام مرتبطة بشكل إيجابي بالميزة الأولى (مع بعض الاختلافات العشوائية وغير العشوائية)، ومرتبطة بشكل سلبي بالميزة الثانية بشكل عام.
من خلال فرض قيد زيادة رتيبة أو قيد نقصان رتيب، على التوالي، على الميزات أثناء عملية التعلم، يكون المقدر قادرًا على اتباع الاتجاه العام بشكل صحيح بدلاً من أن يخضع للاختلافات.
استوحى هذا المثال من وثائق XGBoost.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.inspection import PartialDependenceDisplay
rng = np.random.RandomState(0)
n_samples = 1000
f_0 = rng.rand(n_samples)
f_1 = rng.rand(n_samples)
X = np.c_[f_0, f_1]
noise = rng.normal(loc=0.0, scale=0.01, size=n_samples)
# y مرتبط بشكل إيجابي بـ f_0، ومرتبط بشكل سلبي بـ f_1
y = 5 * f_0 + np.sin(10 * np.pi * f_0) - 5 * f_1 - np.cos(10 * np.pi * f_1) + noise
ملاءمة نموذج أول على مجموعة البيانات هذه بدون أي قيود.
gbdt_no_cst = HistGradientBoostingRegressor()
gbdt_no_cst.fit(X, y)
ملاءمة نموذج ثانٍ على مجموعة البيانات هذه مع قيود زيادة رتيبة (1) وقيد نقصان رتيب (-1)، على التوالي.
gbdt_with_monotonic_cst = HistGradientBoostingRegressor(monotonic_cst=[1, -1])
gbdt_with_monotonic_cst.fit(X, y)
دعونا نعرض الاعتماد الجزئي للتنبؤات على الميزتين.
fig, ax = plt.subplots()
disp = PartialDependenceDisplay.from_estimator(
gbdt_no_cst,
X,
features=[0, 1],
feature_names=(
"الميزة الأولى",
"الميزة الثانية",
),
line_kw={"linewidth": 4, "label": "بدون قيود", "color": "tab:blue"},
ax=ax,
)
PartialDependenceDisplay.from_estimator(
gbdt_with_monotonic_cst,
X,
features=[0, 1],
line_kw={"linewidth": 4, "label": "مقيد", "color": "tab:orange"},
ax=disp.axes_,
)
for f_idx in (0, 1):
disp.axes_[0, f_idx].plot(
X[:, f_idx], y, "o", alpha=0.3, zorder=-1, color="tab:green"
)
disp.axes_[0, f_idx].set_ylim(-6, 6)
plt.legend()
fig.suptitle("تأثير القيود الرتيبة على التبعيات الجزئية")
plt.show()
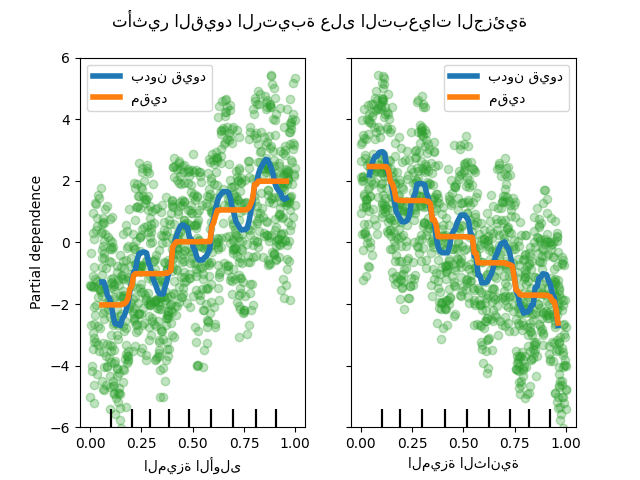
يمكننا أن نرى أن تنبؤات النموذج غير المقيد تلتقط تذبذبات البيانات بينما يتبع النموذج المقيد الاتجاه العام ويتجاهل الاختلافات المحلية.
استخدام أسماء الميزات لتحديد القيود الرتيبة#
لاحظ أنه إذا كانت بيانات التدريب تحتوي على أسماء ميزات، فمن الممكن تحديد القيود الرتيبة عن طريق تمرير قاموس:
import pandas as pd
X_df = pd.DataFrame(X, columns=["f_0", "f_1"])
gbdt_with_monotonic_cst_df = HistGradientBoostingRegressor(
monotonic_cst={"f_0": 1, "f_1": -1}
).fit(X_df, y)
np.allclose(
gbdt_with_monotonic_cst_df.predict(X_df), gbdt_with_monotonic_cst.predict(X)
)
True
Total running time of the script: (0 minutes 0.832 seconds)
Related examples