ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز ميزات الإصدار 0.24 من scikit-learn#
يسعدنا الإعلان عن إصدار scikit-learn 0.24! تم إجراء العديد من الإصلاحات والتحسينات، بالإضافة إلى بعض الميزات الرئيسية الجديدة. نستعرض أدناه بعض الميزات الرئيسية لهذا الإصدار. للاطلاع على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
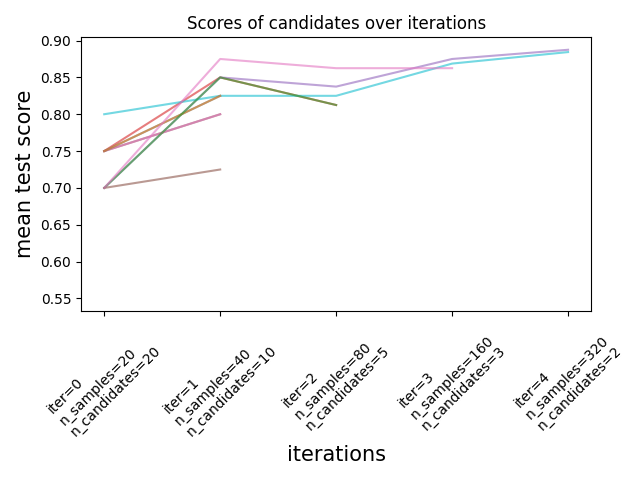
خوارزميات Successive Halving لضبط المعاملات#
أصبحت خوارزمية Successive Halving، وهي طريقة متطورة، متاحة الآن لاستكشاف مساحة المعاملات وتحديد أفضل تركيبة لها.
HalvingGridSearchCV و
HalvingRandomSearchCV يمكن استخدامهما
كبديل مباشر لـ
GridSearchCV و
RandomizedSearchCV.
خوارزمية Successive Halving هي عملية اختيار تكرارية موضحة في الشكل أدناه. يتم تشغيل التكرار الأول باستخدام كمية صغيرة من الموارد،
حيث عادةً ما تتوافق الموارد مع عدد العينات التدريبية،
ولكن يمكن أن تكون أيضًا معلمة عدد صحيح تعسفية مثل n_estimators في
غابة عشوائية. يتم اختيار مجموعة فرعية فقط من مرشحي المعاملات للتكرار التالي، والذي سيتم تشغيله بكمية متزايدة من الموارد المخصصة.
ستستمر مجموعة فرعية فقط من المرشحين حتى نهاية عملية التكرار، وأفضل مرشح للمعاملات هو الذي يحقق أعلى نتيجة في التكرار الأخير.
اقرأ المزيد في دليل المستخدم (ملاحظة: خوارزميات Successive Halving ما زالت تجريبية).
import numpy as np
from scipy.stats import randint
from sklearn.experimental import enable_halving_search_cv # noqa
from sklearn.model_selection import HalvingRandomSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
rng = np.random.RandomState(0)
X, y = make_classification(n_samples=700, random_state=rng)
clf = RandomForestClassifier(n_estimators=10, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 11),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
rsh.best_params_
{'bootstrap': True, 'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10}
الدعم الأصلي للخصائص التصنيفية في خوارزميات HistGradientBoosting#
HistGradientBoostingClassifier و
HistGradientBoostingRegressor أصبح لديهما دعم أصلي
للخصائص التصنيفية: يمكنهما الآن التعامل مع الانقسامات على البيانات غير المرتبة،
والبيانات التصنيفية. اقرأ المزيد في دليل المستخدم.
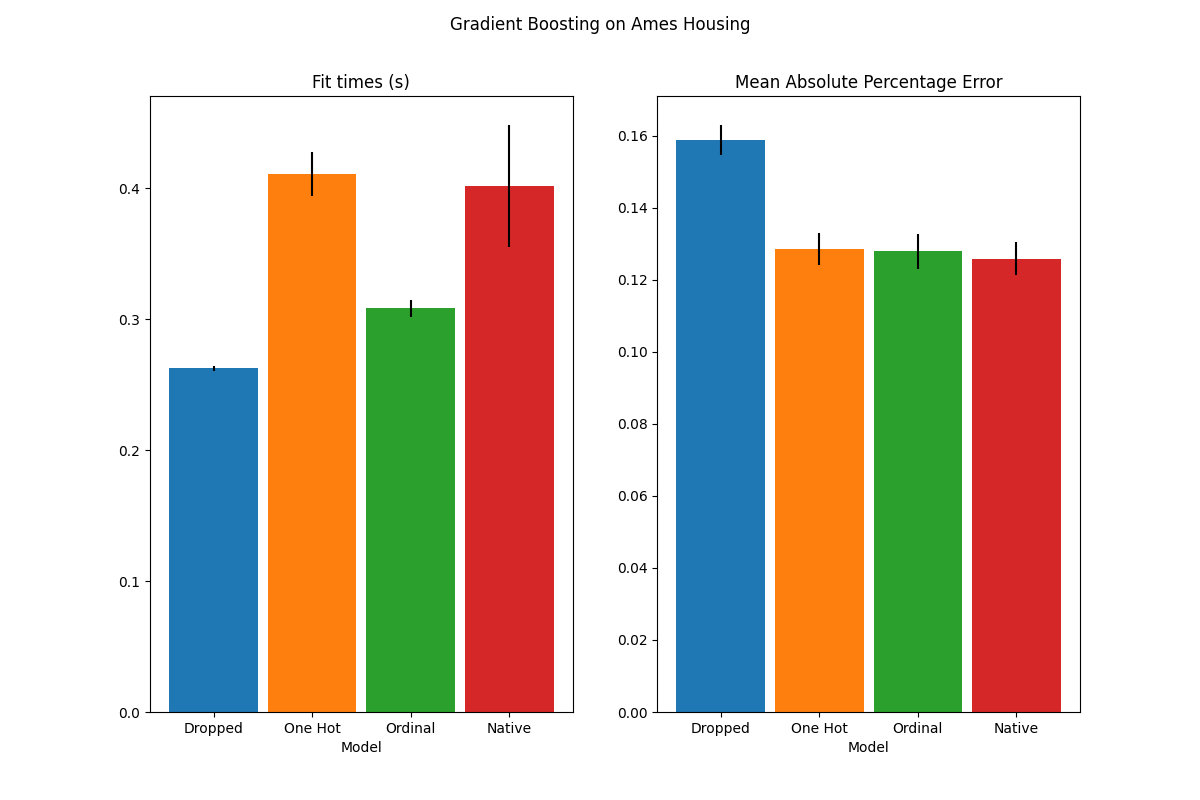
يوضح الرسم البياني أن الدعم الأصلي الجديد للخصائص التصنيفية يؤدي إلى
أوقات ملائمة قابلة للمقارنة مع النماذج التي يتم فيها التعامل مع الفئات
ككميات مرتبة، أي ببساطة الترميز الترتيبي. الدعم الأصلي هو أيضًا
أكثر تعبيرًا من الترميز الثنائي والترميز الترتيبي. ومع ذلك، لاستخدام
المعلمة الجديدة categorical_features، لا يزال من الضروري
معالجة البيانات ضمن خط أنابيب كما هو موضح في هذا المثال:
<sphx_glr_auto_examples_ensemble_plot_gradient_boosting_categorical.py>`.
تحسين أداء خوارزميات HistGradientBoosting#
تم تحسين بصمة الذاكرة بشكل كبير لـ ensemble.HistGradientBoostingRegressor و
ensemble.HistGradientBoostingClassifier أثناء المكالمات إلى fit. بالإضافة إلى ذلك، يتم الآن
تهيئة المخطط البياني بشكل متوازي مما يؤدي إلى تحسينات طفيفة في السرعة.
اقرأ المزيد في صفحة المعايير
<https://scikit-learn.org/scikit-learn-benchmarks/>`_.
خوارزمية جديدة للتعلم الذاتي#
يمكن الآن استخدام خوارزمية جديدة للتعلم الذاتي، تعتمد على خوارزمية ياروسكي <https://doi.org/10.3115/981658.981684>`_ مع أي مصنف ينفذ predict_proba. سيتصرف المصنف الفرعي كمصنف شبه مشرف، مما يسمح له بالتعلم من البيانات غير المصنفة. اقرأ المزيد في دليل المستخدم.
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.svm import SVC
rng = np.random.RandomState(42)
iris = datasets.load_iris()
random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3
iris.target[random_unlabeled_points] = -1
svc = SVC(probability=True, gamma="auto")
self_training_model = SelfTrainingClassifier(svc)
self_training_model.fit(iris.data, iris.target)
محول SequentialFeatureSelector جديد#
متاح محول تكراري جديد لاختيار الخصائص:
SequentialFeatureSelector.
يمكن لاختيار الخصائص التتابعي إضافة خصائص واحدة تلو الأخرى (الاختيار الأمامي) أو
إزالة الخصائص من قائمة الخصائص المتاحة
(الاختيار العكسي)، بناءً على تعظيم النتيجة عبر التحقق.
اقرأ المزيد في دليل المستخدم.
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True, as_frame=True)
feature_names = X.columns
knn = KNeighborsClassifier(n_neighbors=3)
sfs = SequentialFeatureSelector(knn, n_features_to_select=2)
sfs.fit(X, y)
print(
"Features selected by forward sequential selection: "
f"{feature_names[sfs.get_support()].tolist()}"
)
Features selected by forward sequential selection: ['sepal length (cm)', 'petal width (cm)']
دالة تقريب Kernel جديدة PolynomialCountSketch#
تقوم دالة التقريب الجديدة PolynomialCountSketch
بتقريب توسيع متعدد الحدود لمساحة الخصائص عند استخدامها مع النماذج الخطية، ولكنها تستخدم ذاكرة أقل بكثير من
PolynomialFeatures.
from sklearn.datasets import fetch_covtype
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.kernel_approximation import PolynomialCountSketch
from sklearn.linear_model import LogisticRegression
X, y = fetch_covtype(return_X_y=True)
pipe = make_pipeline(
MinMaxScaler(),
PolynomialCountSketch(degree=2, n_components=300),
LogisticRegression(max_iter=1000),
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=5000, test_size=10000, random_state=42
)
pipe.fit(X_train, y_train).score(X_test, y_test)
0.7364
للمقارنة، إليك نتيجة خط الأساس الخطي لنفس البيانات:
linear_baseline = make_pipeline(MinMaxScaler(), LogisticRegression(max_iter=1000))
linear_baseline.fit(X_train, y_train).score(X_test, y_test)
0.7137
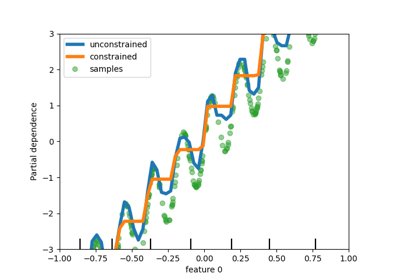
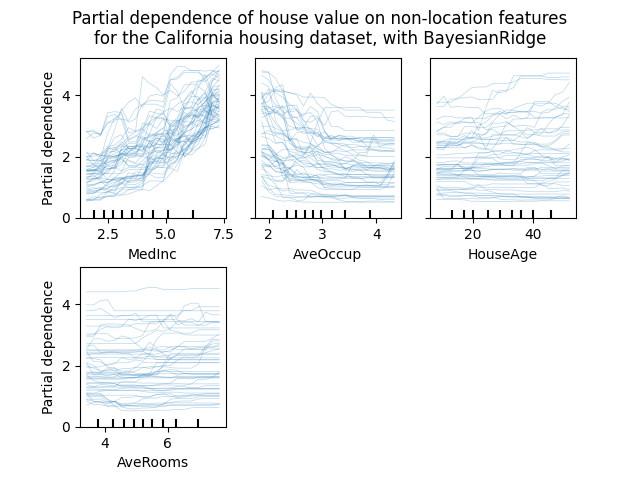
مخططات Individual Conditional Expectation#
متاح نوع جديد من مخططات الاعتماد الجزئي: مخطط Individual Conditional Expectation (ICE). توضح مخططات ICE اعتماد التنبؤ على خاصية لكل عينة بشكل منفصل، مع خط واحد لكل عينة. اقرأ المزيد في دليل المستخدم
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import fetch_california_housing
# from sklearn.inspection import plot_partial_dependence
from sklearn.inspection import PartialDependenceDisplay
X, y = fetch_california_housing(return_X_y=True, as_frame=True)
features = ["MedInc", "AveOccup", "HouseAge", "AveRooms"]
est = RandomForestRegressor(n_estimators=10)
est.fit(X, y)
# plot_partial_dependence has been removed in version 1.2. From 1.2, use
# PartialDependenceDisplay instead.
# display = plot_partial_dependence(
display = PartialDependenceDisplay.from_estimator(
est,
X,
features,
kind="individual",
subsample=50,
n_jobs=3,
grid_resolution=20,
random_state=0,
)
display.figure_.suptitle(
"Partial dependence of house value on non-location features\n"
"for the California housing dataset, with BayesianRidge"
)
display.figure_.subplots_adjust(hspace=0.3)
معيار تقسيم Poisson جديد لخوارزمية DecisionTreeRegressor#
يستمر دمج تقدير الانحدار الشعاعي من الإصدار 0.23.
DecisionTreeRegressor يدعم الآن معيار تقسيم جديد 'poisson'.
قد يكون تعيين criterion="poisson" خيارًا جيدًا
إذا كان الهدف هو عدد أو تكرار.
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
import numpy as np
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X = rng.randn(n_samples, n_features)
# هدف عدد صحيح إيجابي مرتبط بـ X[:, 5] مع العديد من الأصفار:
y = rng.poisson(lam=np.exp(X[:, 5]) / 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=rng)
regressor = DecisionTreeRegressor(criterion="poisson", random_state=0)
regressor.fit(X_train, y_train)
تحسينات توثيق جديدة#
تم إضافة أمثلة وصفحات توثيق جديدة، في جهد مستمر لتحسين فهم ممارسات التعلم الآلي:
قسم جديد حول المشاكل الشائعة والممارسات الموصى بها،
مثال يوضح كيفية المقارنة الإحصائية لأداء النماذج التي تم تقييمها باستخدام
GridSearchCV،مثال حول كيفية تفسير معاملات النماذج الخطية،
مثال يقارن بين Principal Component Regression و Partial Least Squares.
Total running time of the script: (1 minutes 27.782 seconds)
Related examples