ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز الميزات الجديدة في إصدار scikit-learn 0.23#
يسعدنا الإعلان عن إصدار scikit-learn 0.23! تم إصلاح العديد من الأخطاء وإضافة العديد من التحسينات، بالإضافة إلى بعض الميزات الرئيسية الجديدة. نستعرض أدناه بعض الميزات الرئيسية لهذا الإصدار. للاطلاع على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
النماذج الخطية العامة، وخسارة بواسون للتعزيز التدريجي#
النماذج الخطية العامة المنتظرة منذ فترة طويلة مع دالات خسارة غير طبيعية أصبحت
متوفرة الآن. على وجه الخصوص، تم تنفيذ ثلاثة منظمين جدد:
PoissonRegressor،
GammaRegressor، و
TweedieRegressor. يمكن استخدام منظم بواسون
لنمذجة العد الإيجابي للمتغيرات الصحيحة، أو الترددات النسبية. اقرأ المزيد في
دليل المستخدم. بالإضافة إلى ذلك،
HistGradientBoostingRegressor يدعم الآن
'poisson' كخسارة أيضًا.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import PoissonRegressor
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X = rng.randn(n_samples, n_features)
# الهدف الإيجابي للمتغيرات الصحيحة مرتبط بـ X[:, 5] مع العديد من الأصفار:
y = rng.poisson(lam=np.exp(X[:, 5]) / 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=rng)
glm = PoissonRegressor()
gbdt = HistGradientBoostingRegressor(loss="poisson", learning_rate=0.01)
glm.fit(X_train, y_train)
gbdt.fit(X_train, y_train)
print(glm.score(X_test, y_test))
print(gbdt.score(X_test, y_test))
0.35776189065725783
0.42425183539869415
تمثيل مرئي غني للمقدرات#
يمكن الآن تصور المقدرات في الدفاتر من خلال تمكين خيار
display='diagram' . هذا مفيد بشكل خاص لتلخيص بنية الأنابيب والمقدرات
المركبة الأخرى، مع التفاعل لتوفير التفاصيل. انقر على الصورة التوضيحية
أدناه لتوسيع عناصر الأنابيب. راجع تصور المقدرات المركبة
لمعرفة كيفية استخدام هذه الميزة.
from sklearn import set_config
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_transformer
from sklearn.linear_model import LogisticRegression
set_config(display="diagram")
num_proc = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
cat_proc = make_pipeline(
SimpleImputer(strategy="constant", fill_value="missing"),
OneHotEncoder(handle_unknown="ignore"),
)
preprocessor = make_column_transformer(
(num_proc, ("feat1", "feat3")), (cat_proc, ("feat0", "feat2"))
)
clf = make_pipeline(preprocessor, LogisticRegression())
clf
تحسينات في قابلية التوسع والاستقرار لخوارزمية KMeans#
تم إعادة تصميم خوارزمية KMeans بالكامل، وهي الآن
أسرع وأكثر استقرارًا بشكل ملحوظ. بالإضافة إلى ذلك، أصبحت خوارزمية Elkan
متوافقة مع المصفوفات المتناثرة. يستخدم المقدر موازاة قائمة على OpenMP
بدلاً من الاعتماد على joblib، لذلك لم يعد لخيار n_jobs أي تأثير. للحصول
على مزيد من التفاصيل حول كيفية التحكم في عدد الخيوط، يرجى الرجوع إلى
ملاحظاتنا حول الموازاة.
import scipy
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import completeness_score
rng = np.random.RandomState(0)
X, y = make_blobs(random_state=rng)
X = scipy.sparse.csr_matrix(X)
X_train, X_test, _, y_test = train_test_split(X, y, random_state=rng)
kmeans = KMeans(n_init="auto").fit(X_train)
print(completeness_score(kmeans.predict(X_test), y_test))
0.6992415257664282
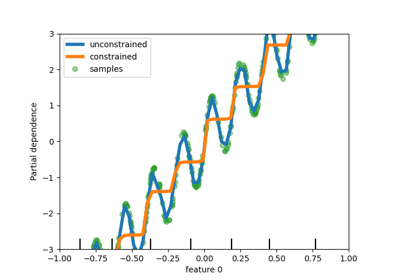
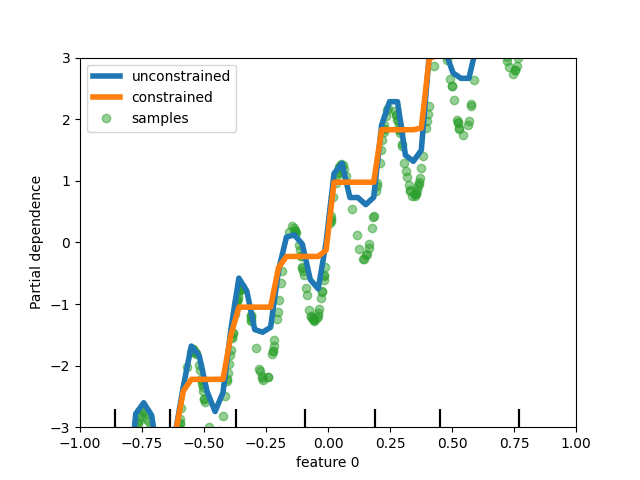
تحسينات على المقدرات القائمة على التدرج التدريجي للتعزيز التدريجي#
تم إجراء العديد من التحسينات على
HistGradientBoostingClassifier و
HistGradientBoostingRegressor. بالإضافة إلى
خسارة بواسون المذكورة أعلاه، تدعم هذه المقدرات الآن أوزان العينات. أيضًا، تم إضافة معيار إيقاف مبكر تلقائي: يتم تمكين الإيقاف المبكر
بشكل افتراضي عندما يتجاوز عدد العينات 10 آلاف. أخيرًا، يمكن للمستخدمين الآن
تحديد قيود أحادية الاتجاه لتقييد التوقعات بناءً
على تغيرات ميزات محددة. في المثال التالي، نقوم ببناء هدف مرتبط بشكل عام
بالمتغير الأول، مع بعض الضجيج. يسمح تطبيق القيود الأحادية الاتجاه
بالتوقعات بالتقاط التأثير العام للمتغير الأول، بدلاً من ملاءمة الضجيج.
لمثال على الاستخدام، راجع الميزات في أشجار التعزيز المتدرج للهيستوغرام.
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
# from sklearn.inspection import plot_partial_dependence
from sklearn.inspection import PartialDependenceDisplay
from sklearn.ensemble import HistGradientBoostingRegressor
n_samples = 500
rng = np.random.RandomState(0)
X = rng.randn(n_samples, 2)
noise = rng.normal(loc=0.0, scale=0.01, size=n_samples)
y = 5 * X[:, 0] + np.sin(10 * np.pi * X[:, 0]) - noise
gbdt_no_cst = HistGradientBoostingRegressor().fit(X, y)
gbdt_cst = HistGradientBoostingRegressor(monotonic_cst=[1, 0]).fit(X, y)
# plot_partial_dependence has been removed in version 1.2. From 1.2, use
# PartialDependenceDisplay instead.
# disp = plot_partial_dependence(
disp = PartialDependenceDisplay.from_estimator(
gbdt_no_cst,
X,
features=[0],
feature_names=["feature 0"],
line_kw={"linewidth": 4, "label": "unconstrained", "color": "tab:blue"},
)
# plot_partial_dependence(
PartialDependenceDisplay.from_estimator(
gbdt_cst,
X,
features=[0],
line_kw={"linewidth": 4, "label": "constrained", "color": "tab:orange"},
ax=disp.axes_,
)
disp.axes_[0, 0].plot(
X[:, 0], y, "o", alpha=0.5, zorder=-1, label="samples", color="tab:green"
)
disp.axes_[0, 0].set_ylim(-3, 3)
disp.axes_[0, 0].set_xlim(-1, 1)
plt.legend()
plt.show()
دعم أوزان العينات لخوارزميتي Lasso و ElasticNet#
خوارزميتا الانحدار الخطي Lasso و
ElasticNet تدعمان الآن أوزان العينات.
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
from sklearn.linear_model import Lasso
import numpy as np
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X, y = make_regression(n_samples, n_features, random_state=rng)
sample_weight = rng.rand(n_samples)
X_train, X_test, y_train, y_test, sw_train, sw_test = train_test_split(
X, y, sample_weight, random_state=rng
)
reg = Lasso()
reg.fit(X_train, y_train, sample_weight=sw_train)
print(reg.score(X_test, y_test, sw_test))
0.999791942438998
Total running time of the script: (0 minutes 1.036 seconds)
Related examples