ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تجريد الميزات#
توضيح لتجريد الميزات على مجموعات بيانات التصنيف الاصطناعية. يقوم تجريد الميزات بتفكيك كل ميزة إلى مجموعة من الصناديق, هنا موزعة بالتساوي في العرض. ثم يتم ترميز القيم المنفصلة بطريقة الترميز أحادي الساخن, وتعطى لمصنف خطي. تمكن هذه المعالجة المسبقة من سلوك غير خطي حتى على الرغم من أن المصنف خطي.
في هذا المثال, يمثل الصفان الأولان مجموعات بيانات غير قابلة للفصل خطيًا (أقمار صناعية ودوائر متحدة المركز) بينما الثالثة قابلة للفصل تقريبًا. خطي. على مجموعات البيانات غير القابلة للفصل خطيًا, يزيد تجريد الميزات بشكل كبير من أداء المصنفات الخطية. على مجموعة البيانات القابلة للفصل خطيًا, يقلل تجريد الميزات من أداء المصنفات الخطية. يتم أيضًا عرض مصنفين غير خطيين للمقارنة.
يجب أخذ هذا المثال مع حبة من الملح, حيث أن الحدس المنقول لا ينتقل بالضرورة إلى مجموعات البيانات الحقيقية. خاصة في الأبعاد العالية, يمكن فصل البيانات بسهولة أكبر بشكل خطي. علاوة على ذلك, يؤدي استخدام تجريد الميزات والترميز أحادي الساخن إلى زيادة عدد الميزات, والتي تؤدي بسهولة إلى الإفراط في التكيف عندما يكون عدد العينات صغيرًا.
تظهر المخططات نقاط التدريب بألوان صلبة ونقاط الاختبار شبه شفافة. يظهر اليمين السفلي دقة التصنيف على مجموعة الاختبار.
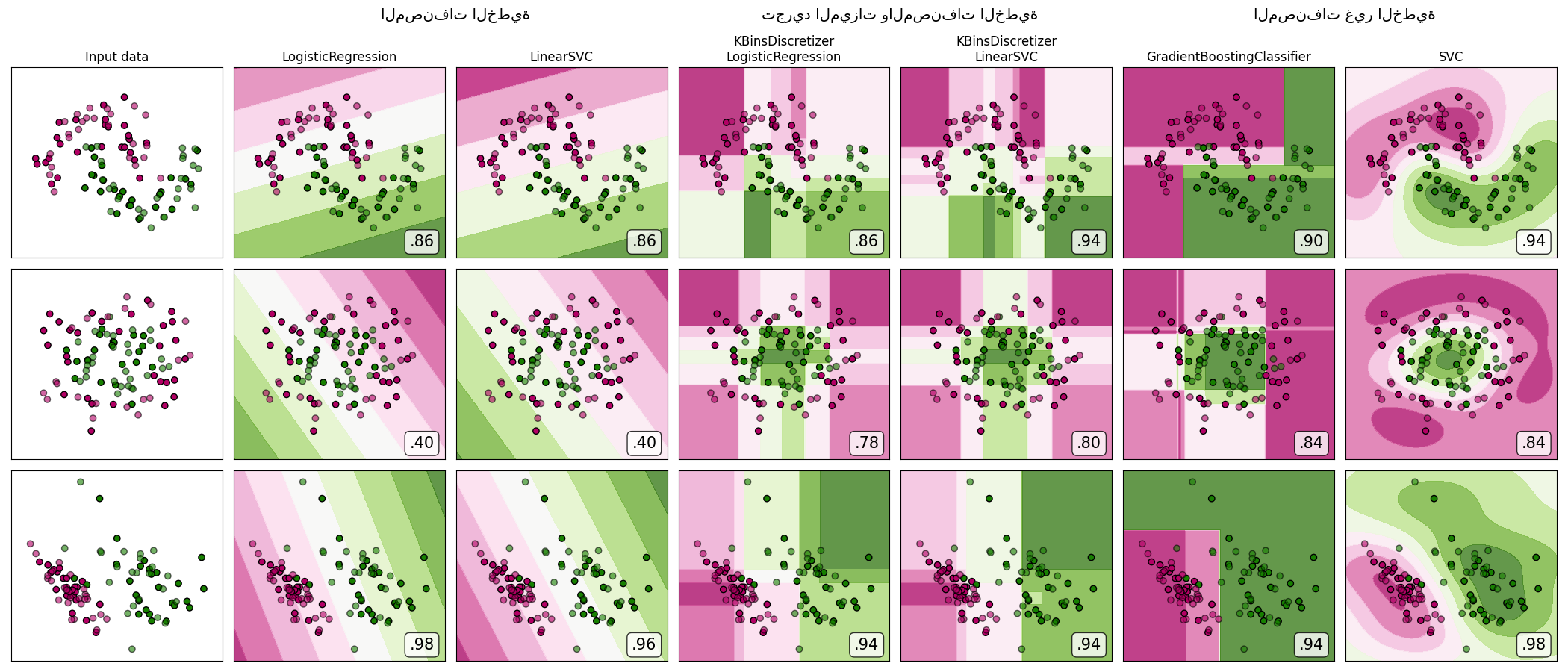
dataset 0
---------
LogisticRegression: 0.86
LinearSVC: 0.86
KBinsDiscretizer + LogisticRegression: 0.86
KBinsDiscretizer + LinearSVC: 0.94
GradientBoostingClassifier: 0.90
SVC: 0.94
dataset 1
---------
LogisticRegression: 0.40
LinearSVC: 0.40
KBinsDiscretizer + LogisticRegression: 0.78
KBinsDiscretizer + LinearSVC: 0.80
GradientBoostingClassifier: 0.84
SVC: 0.84
dataset 2
---------
LogisticRegression: 0.98
LinearSVC: 0.96
KBinsDiscretizer + LogisticRegression: 0.94
KBinsDiscretizer + LinearSVC: 0.94
GradientBoostingClassifier: 0.94
SVC: 0.98
# المؤلفون: مطوري سكايت-ليرن
# معرف SPDX-License: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_circles, make_classification, make_moons
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.exceptions import ConvergenceWarning
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import KBinsDiscretizer, StandardScaler
from sklearn.svm import SVC, LinearSVC
from sklearn.utils._testing import ignore_warnings
h = 0.02 # حجم الخطوة في الشبكة
def get_name(estimator):
name = estimator.__class__.__name__
if name == "Pipeline":
name = [get_name(est[1]) for est in estimator.steps]
name = " + ".join(name)
return name
# قائمة (المقدر, param_grid), حيث يتم استخدام param_grid في GridSearchCV
# تم تحديد مساحات المعلمات في هذا المثال لتكون محدودة النطاق لتقليل
# وقت تشغيله. في حالة الاستخدام الفعلي, يجب استخدام مساحة بحث أوسع للخوارزميات
# يجب استخدام.
classifiers = [
(
make_pipeline (StandardScaler (), LogisticRegression (random_state = 0)),
{"logisticregression__C": np.logspace (-1, 1, 3)},
),
(
make_pipeline (StandardScaler (), LinearSVC (random_state = 0)),
{"linearsvc__C": np.logspace (-1, 1, 3)},
),
(
make_pipeline (
StandardScaler (),
KBinsDiscretizer (encode = "onehot", random_state = 0),
LogisticRegression (random_state = 0),
),
{
"kbinsdiscretizer__n_bins": np.arange (5, 8),
"logisticregression__C": np.logspace (-1, 1, 3),
},
),
(
make_pipeline (
StandardScaler (),
KBinsDiscretizer (encode = "onehot", random_state = 0),
LinearSVC (random_state = 0),
),
{
"kbinsdiscretizer__n_bins": np.arange (5, 8),
"linearsvc__C": np.logspace (-1, 1, 3),
},
),
(
make_pipeline (
StandardScaler (), GradientBoostingClassifier (n_estimators = 5, random_state = 0)
),
{"gradientboostingclassifier__learning_rate": np.logspace (-2, 0, 5)},
),
(
make_pipeline (StandardScaler (), SVC (random_state = 0)),
{"svc__C": np.logspace (-1, 1, 3)},
),
]
names = [get_name(e).replace("StandardScaler + ", "") for e, _ in classifiers]
n_samples = 100
datasets = [
make_moons (n_samples = n_samples, noise = 0.2, random_state = 0),
make_circles (n_samples = n_samples, noise = 0.2, factor = 0.5, random_state = 1),
make_classification (
n_samples = n_samples,
n_features = 2,
n_redundant = 0,
n_informative = 2,
random_state = 2,
n_clusters_per_class = 1,
),
]
fig, axes = plt.subplots(
nrows=len(datasets), ncols=len(classifiers) + 1, figsize=(21, 9)
)
cm_piyg = plt.cm.PiYG
cm_bright = ListedColormap(["#b30065", "#178000"])
# التكرار عبر مجموعات البيانات
for ds_cnt, (X, y) in enumerate(datasets):
print(f"\ndataset {ds_cnt}\n---------")
# تقسيم إلى جزء التدريب والاختبار
X_train, X_test, y_train, y_test = train_test_split (
X, y, test_size = 0.5, random_state = 42
)
# إنشاء الشبكة لألوان الخلفية
x_min, x_max = X [:, 0].min () - 0.5, X [:, 0].max () + 0.5
y_min, y_max = X [:, 1].min () - 0.5, X [:, 1].max () + 0.5
xx, yy = np.meshgrid (np.arange (x_min, x_max, h), np.arange (y_min, y_max, h))
# قم برسم مجموعة البيانات أولاً
ax = axes [ds_cnt, 0]
if ds_cnt == 0:
ax.set_title ("Input data")
# قم برسم نقاط التدريب
ax.scatter (X_train [:, 0], X_train [:, 1], c = y_train, cmap = cm_bright, edgecolors = "k")
# ونقاط الاختبار
ax.scatter (
X_test [:, 0], X_test [:, 1], c = y_test, cmap = cm_bright, alpha = 0.6, edgecolors = "k"
)
ax.set_xlim (xx.min (), xx.max ())
ax.set_ylim (yy.min (), yy.max ())
ax.set_xticks (())
ax.set_yticks (())
# التكرار عبر المصنفات
for est_idx, (name, (estimator, param_grid)) in enumerate(zip(names, classifiers)):
ax = axes[ds_cnt, est_idx + 1]
clf = GridSearchCV(estimator=estimator, param_grid=param_grid)
with ignore_warnings(category=ConvergenceWarning):
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print(f"{name}: {score:.2f}")
# قم برسم حدود القرار. لهذا, سنقوم بتعيين لون لكل
# نقطة في الشبكة [x_min, x_max] * [y_min, y_max].
if hasattr(clf, "decision_function"):
Z = clf.decision_function(np.column_stack([xx.ravel(), yy.ravel()]))
else:
Z = clf.predict_proba(np.column_stack([xx.ravel(), yy.ravel()]))[:, 1]
# ضع النتيجة في رسم تخطيطي ملون
Z = Z.reshape (xx.shape)
ax.contourf (xx, yy, Z, cmap = cm_piyg, alpha = 0.8)
# قم برسم نقاط التدريب
ax.scatter (
X_train [:, 0], X_train [:, 1], c = y_train, cmap = cm_bright, edgecolors = "k"
)
# ونقاط الاختبار
ax.scatter (
X_test [:, 0],
X_test [:, 1],
c = y_test,
cmap = cm_bright,
edgecolors = "k",
alpha = 0.6,
)
ax.set_xlim (xx.min (), xx.max ())
ax.set_ylim (yy.min (), yy.max ())
ax.set_xticks (())
ax.set_yticks (())
if ds_cnt == 0:
ax.set_title(name.replace(" + ", "\n"))
ax.text(
0.95,
0.06,
(f"{score:.2f}").lstrip("0"),
size=15,
bbox=dict(boxstyle="round", alpha=0.8, facecolor="white"),
transform=ax.transAxes,
horizontalalignment="right",
)
plt.tight_layout()
# إضافة suptitles فوق الشكل
plt.subplots_adjust (top = 0.90)
suptitles = [
"المصنفات الخطية",
"تجريد الميزات والمصنفات الخطية",
"المصنفات غير الخطية",
]
for i, suptitle in zip([1, 3, 5], suptitles):
ax = axes[0, i]
ax.text(
1.05,
1.25,
suptitle,
transform=ax.transAxes,
horizontalalignment="center",
size="x-large",
)
plt.show()
Total running time of the script: (0 minutes 4.848 seconds)
Related examples
تغيير معامل التنظيم في الشبكة العصبية متعددة الطبقات