ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
انحدار شجرة القرار#
في هذا المثال، نوضح تأثير تغيير العمق الأقصى لشجرة القرار على كيفية ملاءمتها للبيانات. نقوم بذلك مرة على مهمة انحدار 1D ومرة على مهمة انحدار متعددة المخرجات.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
شجرة القرار على مهمة انحدار 1D#
هنا نقوم بضبط شجرة على مهمة انحدار 1D.
تستخدم شجرة القرار لضبط منحنى جيب التمام مع إضافة ملاحظة عشوائية. ونتيجة لذلك، تتعلم انحدارات خطية محلية تقريب منحنى جيب التمام.
يمكننا أن نرى أنه إذا تم تعيين العمق الأقصى للشجرة (الذي يتحكم فيه
بمعلمة max_depth) مرتفعًا جدًا، فإن شجرة القرار تتعلم تفاصيل دقيقة
لبيانات التدريب وتتعلم من الضوضاء، أي أنها تبالغ في التعميم.
إنشاء مجموعة بيانات عشوائية 1D#
import numpy as np
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
ضبط نموذج الانحدار#
هنا نقوم بضبط نموذجين بعمقين أقصى مختلفين
from sklearn.tree import DecisionTreeRegressor
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)
التنبؤ#
الحصول على تنبؤات على مجموعة الاختبار
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
رسم النتائج#
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
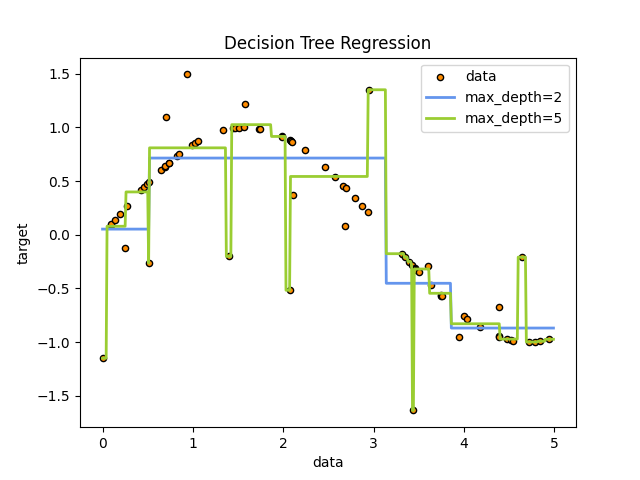
كما ترى، فإن النموذج بعمق 5 (أصفر) يتعلم تفاصيل بيانات التدريب إلى الحد الذي يبالغ فيه في التعميم على الضوضاء. من ناحية أخرى، النموذج بعمق 2 (أزرق) يتعلم الاتجاهات الرئيسية في البيانات جيدًا ولا يبالغ في التعميم. في حالات الاستخدام الفعلية، تحتاج إلى التأكد من أن الشجرة لا تبالغ في التعميم على بيانات التدريب، والتي يمكن القيام بها باستخدام تقسيم البيانات.
انحدار شجرة القرار مع أهداف متعددة المخرجات#
هنا تستخدم شجرة القرار للتنبؤ في نفس الوقت بالملاحظات العشوائية 'x' و 'y' لدائرة مع ميزة أساسية واحدة. ونتيجة لذلك، تتعلم انحدارات خطية محلية تقريب الدائرة.
يمكننا أن نرى أنه إذا تم تعيين العمق الأقصى للشجرة (الذي يتحكم فيه
بمعلمة max_depth) مرتفعًا جدًا، فإن شجرة القرار تتعلم تفاصيل دقيقة
لبيانات التدريب وتتعلم من الضوضاء، أي أنها تبالغ في التعميم.
إنشاء مجموعة بيانات عشوائية#
ضبط نموذج الانحدار#
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_3 = DecisionTreeRegressor(max_depth=8)
regr_1.fit(X, y)
regr_2.fit(X, y)
regr_3.fit(X, y)
التنبؤ#
الحصول على تنبؤات على مجموعة الاختبار
X_test = np.arange(-100.0, 100.0, 0.01)[:, np.newaxis]
y_1 = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
y_3 = regr_3.predict(X_test)
رسم النتائج#
plt.figure()
s = 25
plt.scatter(y[:, 0], y[:, 1], c="yellow", s=s, edgecolor="black", label="data")
plt.scatter(
y_1[:, 0],
y_1[:, 1],
c="cornflowerblue",
s=s,
edgecolor="black",
label="max_depth=2",
)
plt.scatter(y_2[:, 0], y_2[:, 1], c="red", s=s, edgecolor="black", label="max_depth=5")
plt.scatter(y_3[:, 0], y_3[:, 1], c="blue", s=s, edgecolor="black", label="max_depth=8")
plt.xlim([-6, 6])
plt.ylim([-6, 6])
plt.xlabel("target 1")
plt.ylabel("target 2")
plt.title("Multi-output Decision Tree Regression")
plt.legend(loc="best")
plt.show()
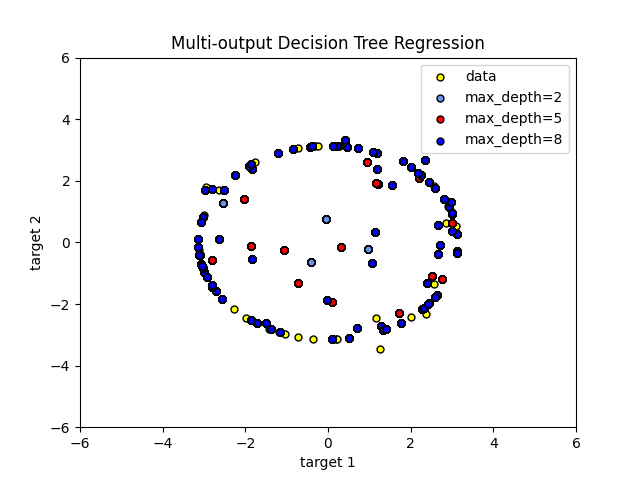
كما ترى، كلما زادت قيمة max_depth، كلما زادت تفاصيل البيانات
التي يلتقطها النموذج. ومع ذلك، فإن النموذج يبالغ أيضًا في التعميم على البيانات ويتأثر
بالضوضاء.
Total running time of the script: (0 minutes 0.431 seconds)
Related examples
مقارنة الغابات العشوائية ومقدر المخرجات المتعددة التلوي

رسم أسطح القرار لمجموعات الأشجار على مجموعة بيانات إيريس
رسم سطح القرار لأشجار القرار المدربة على مجموعة بيانات الزهرة الآرغوانية