ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
اختيار تقليل الأبعاد باستخدام Pipeline و GridSearchCV#
يبني هذا المثال خط أنابيب يقوم بتقليل الأبعاد متبوعًا بالتنبؤ باستخدام مصنف متجه الدعم. يوضح استخدام GridSearchCV و
Pipeline للتحسين على فئات مختلفة من المقدرات في تشغيل CV واحد - تتم مقارنة تقليل الأبعاد غير الخاضع للإشراف PCA و NMF باختيار الميزات أحادي المتغير أثناء البحث الشبكي.
بالإضافة إلى ذلك، يمكن إنشاء مثيل لـ Pipeline باستخدام وسيطة memory لحفظ المحولات داخل خط الأنابيب، وتجنب ملاءمة نفس المحولات مرارًا وتكرارًا.
لاحظ أن استخدام memory لتمكين التخزين المؤقت يصبح مثيرًا للاهتمام عندما تكون ملاءمة المحول مكلفة.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
توضيح Pipeline و GridSearchCV#
from joblib import Memory
from shutil import rmtree
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import NMF, PCA
from sklearn.feature_selection import SelectKBest, mutual_info_classif
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import LinearSVC
X, y = load_digits(return_X_y=True)
pipe = Pipeline(
[
("scaling", MinMaxScaler()),
# يتم ملء مرحلة reduce_dim بواسطة param_grid
("reduce_dim", "passthrough"),
("classify", LinearSVC(dual=False, max_iter=10000)),
]
)
N_FEATURES_OPTIONS = [2, 4, 8]
C_OPTIONS = [1, 10, 100, 1000]
param_grid = [
{
"reduce_dim": [PCA(iterated_power=7), NMF(max_iter=1_000)],
"reduce_dim__n_components": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
{
"reduce_dim": [SelectKBest(mutual_info_classif)],
"reduce_dim__k": N_FEATURES_OPTIONS,
"classify__C": C_OPTIONS,
},
]
reducer_labels = ["PCA", "NMF", "KBest(mutual_info_classif)"]
grid = GridSearchCV(pipe, n_jobs=1, param_grid=param_grid)
grid.fit(X, y)
mean_scores = np.array(grid.cv_results_["mean_test_score"])
# الدرجات بترتيب تكرار param_grid، وهو أبجدي
mean_scores = mean_scores.reshape(len(C_OPTIONS), -1, len(N_FEATURES_OPTIONS))
# تحديد الدرجة لأفضل C
mean_scores = mean_scores.max(axis=0)
# إنشاء إطار بيانات لتسهيل التخطيط
mean_scores = pd.DataFrame(
mean_scores.T, index=N_FEATURES_OPTIONS, columns=reducer_labels
)
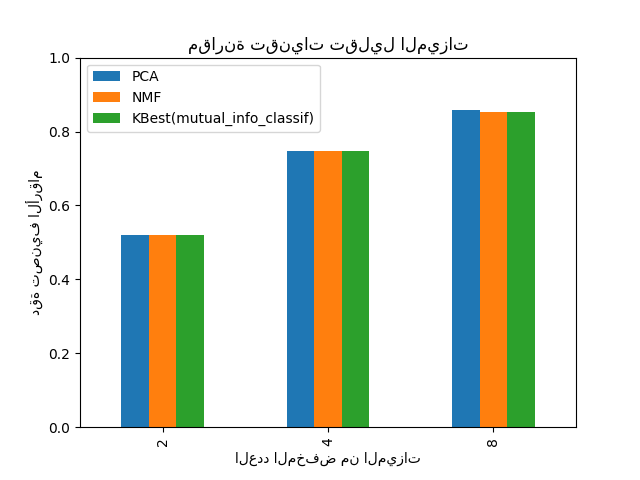
ax = mean_scores.plot.bar()
ax.set_title("مقارنة تقنيات تقليل الميزات")
ax.set_xlabel("العدد المخفض من الميزات")
ax.set_ylabel("دقة تصنيف الأرقام")
ax.set_ylim((0, 1))
ax.legend(loc="upper left")
plt.show()
تخزين المحولات مؤقتًا داخل Pipeline#
من المفيد أحيانًا تخزين حالة محول معين
لأنه يمكن استخدامه مرة أخرى. استخدام خط أنابيب في GridSearchCV يؤدي
إلى مثل هذه المواقف. لذلك، نستخدم الوسيطة memory لتمكين التخزين المؤقت.
تحذير
لاحظ أن هذا المثال هو مجرد توضيح لأنه في هذه الحالة
ملاءمة PCA ليست بالضرورة أبطأ من تحميل ذاكرة التخزين المؤقت. ومن ثم، استخدم معلمة المنشئ memory عندما تكون ملاءمة
المحول مكلفة.
# إنشاء مجلد مؤقت لتخزين محولات خط الأنابيب
location = "cachedir"
memory = Memory(location=location, verbose=10)
cached_pipe = Pipeline(
[("reduce_dim", PCA()), ("classify", LinearSVC(dual=False, max_iter=10000))],
memory=memory,
)
# هذه المرة، سيتم استخدام خط أنابيب مخزن مؤقتًا داخل البحث الشبكي
# حذف ذاكرة التخزين المؤقت المؤقتة قبل الخروج
memory.clear(warn=False)
rmtree(location)
يتم حساب ملاءمة PCA فقط عند تقييم التكوين الأول
لمعلمة C لمصنف LinearSVC. التكوينات الأخرى لـ C ستؤدي إلى تحميل بيانات مقدر PCA المخزنة مؤقتًا، مما يؤدي إلى توفير وقت المعالجة. لذلك، فإن استخدام
تخزين خط الأنابيب مؤقتًا باستخدام memory مفيد للغاية عندما تكون ملاءمة
المحول مكلفة.
Total running time of the script: (0 minutes 52.509 seconds)
Related examples


sphx_glr_auto_examples_cluster_plot_feature_agglomeration_vs_univariate_selection.py