ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تعلم متعدد الشعب على الأرقام المكتوبة بخط اليد: التضمين الخطي المحلي، Isomap...#
نوضح تقنيات التضمين المختلفة على مجموعة بيانات الأرقام.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
تحميل مجموعة بيانات الأرقام#
سنقوم بتحميل مجموعة بيانات الأرقام ونستخدم فقط أول ستة من الفئات العشرة المتاحة.
from sklearn.datasets import load_digits
digits = load_digits(n_class=6)
X, y = digits.data, digits.target
n_samples, n_features = X.shape
n_neighbors = 30
يمكننا رسم أول مائة رقم من مجموعة البيانات هذه.
import matplotlib.pyplot as plt
fig, axs = plt.subplots(nrows=10, ncols=10, figsize=(6, 6))
for idx, ax in enumerate(axs.ravel()):
ax.imshow(X[idx].reshape((8, 8)), cmap=plt.cm.binary)
ax.axis("off")
_ = fig.suptitle("مجموعة مختارة من مجموعة بيانات الأرقام ذات 64 بُعدًا", fontsize=16)

دالة مساعدة لرسم التضمين#
أدناه، سنستخدم تقنيات مختلفة لتضمين مجموعة بيانات الأرقام. سنرسم إسقاط البيانات الأصلية على كل تضمين. سيسمح لنا ذلك بالتحقق مما إذا كانت الأرقام مجمعة معًا في فضاء التضمين، أو منتشرة عبره.
import numpy as np
from matplotlib import offsetbox
from sklearn.preprocessing import MinMaxScaler
def plot_embedding(X, title):
_, ax = plt.subplots()
X = MinMaxScaler().fit_transform(X)
for digit in digits.target_names:
ax.scatter(
*X[y == digit].T,
marker=f"${digit}$",
s=60,
color=plt.cm.Dark2(digit),
alpha=0.425,
zorder=2,
)
shown_images = np.array([[1.0, 1.0]]) # just something big
for i in range(X.shape[0]):
# plot every digit on the embedding
# show an annotation box for a group of digits
dist = np.sum((X[i] - shown_images) ** 2, 1)
if np.min(dist) < 4e-3:
# don't show points that are too close
continue
shown_images = np.concatenate([shown_images, [X[i]]], axis=0)
imagebox = offsetbox.AnnotationBbox(
offsetbox.OffsetImage(digits.images[i], cmap=plt.cm.gray_r), X[i]
)
imagebox.set(zorder=1)
ax.add_artist(imagebox)
ax.set_title(title)
ax.axis("off")
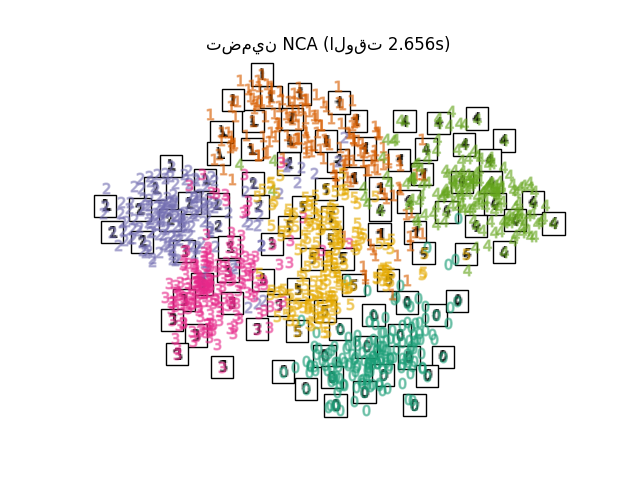
مقارنة تقنيات التضمين#
أدناه، نقارن بين التقنيات المختلفة. ومع ذلك، هناك بعض الأشياء التي يجب ملاحظتها:
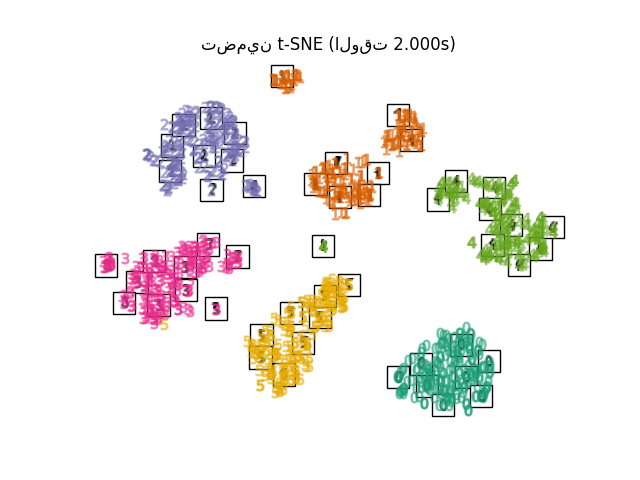
RandomTreesEmbeddingليست من الناحية الفنية طريقة تضمين متعدد الشعب، حيث إنها تتعلم تمثيلًا عالي الأبعاد والذي نطبق عليه طريقة لخفض الأبعاد. ومع ذلك، غالبًا ما يكون من المفيد تحويل مجموعة البيانات إلى تمثيل يكون فيه من الممكن فصل الفئات خطيًا.LinearDiscriminantAnalysisوNeighborhoodComponentsAnalysis، هما طريقتان لخفض الأبعاد خاضعتان للإشراف، أي أنهما تستخدمان الملصقات المقدمة، على عكس الطرق الأخرى.TSNEيتم تهيئتها بالتضمين الذي تم إنشاؤه بواسطة PCA في هذا المثال. وهذا يضمن الاستقرار الشامل للتضمين، أي أن التضمين لا يعتمد على التهيئة العشوائية.
from sklearn.decomposition import TruncatedSVD
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.ensemble import RandomTreesEmbedding
from sklearn.manifold import (
MDS,
TSNE,
Isomap,
LocallyLinearEmbedding,
SpectralEmbedding,
)
from sklearn.neighbors import NeighborhoodComponentsAnalysis
from sklearn.pipeline import make_pipeline
from sklearn.random_projection import SparseRandomProjection
embeddings = {
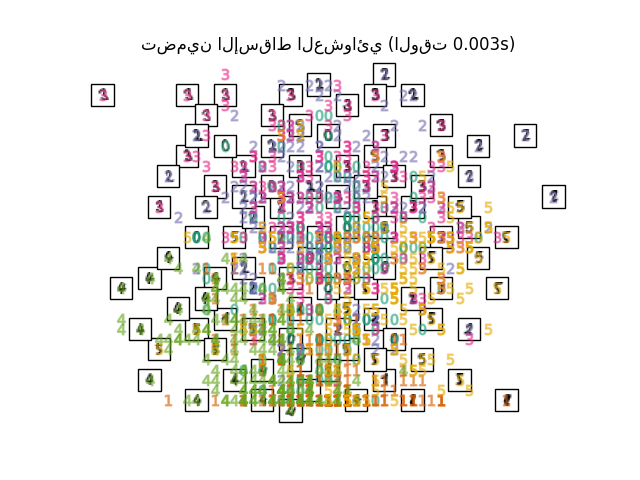
"تضمين الإسقاط العشوائي": SparseRandomProjection(
n_components=2, random_state=42
),
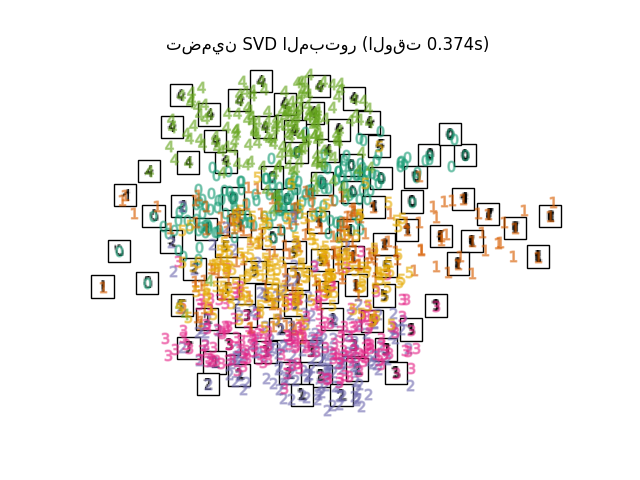
"تضمين SVD المبتور": TruncatedSVD(n_components=2),
"تضمين تحليل التمايز الخطي": LinearDiscriminantAnalysis(
n_components=2
),
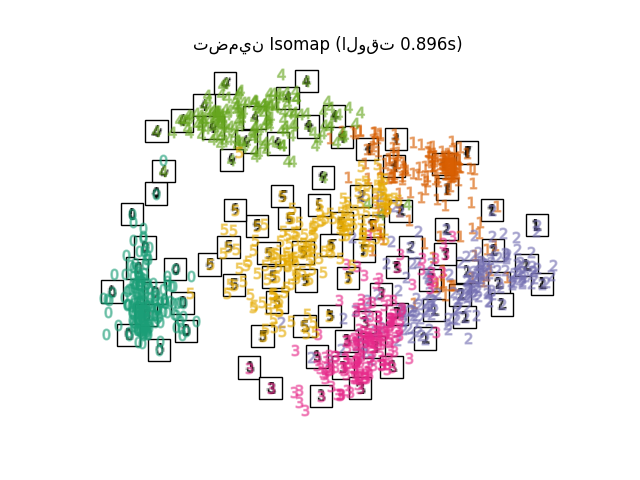
"تضمين Isomap": Isomap(n_neighbors=n_neighbors, n_components=2),
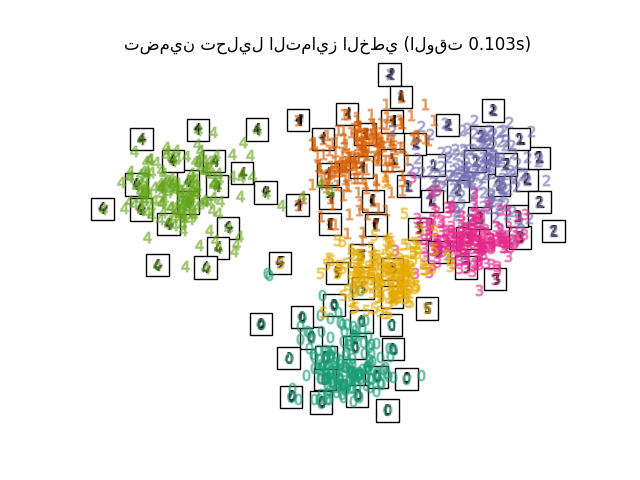
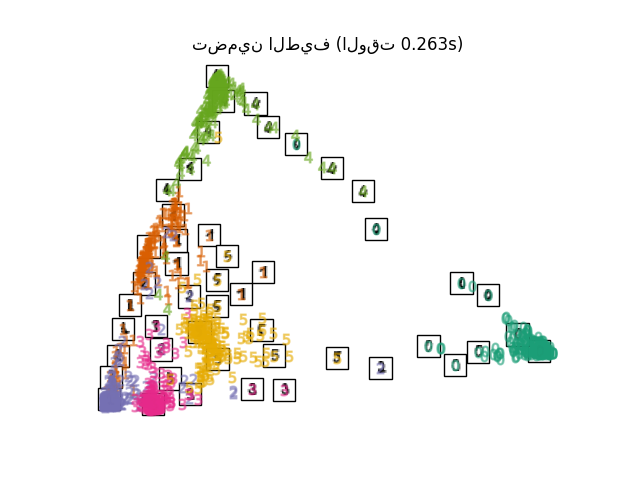
"تضمين LLE القياسي": LocallyLinearEmbedding(
n_neighbors=n_neighbors, n_components=2, method="standard"
),
"تضمين LLE المعدل": LocallyLinearEmbedding(
n_neighbors=n_neighbors, n_components=2, method="modified"
),
"تضمين Hessian LLE": LocallyLinearEmbedding(
n_neighbors=n_neighbors, n_components=2, method="hessian"
),
"تضمين LTSA LLE": LocallyLinearEmbedding(
n_neighbors=n_neighbors, n_components=2, method="ltsa"
),
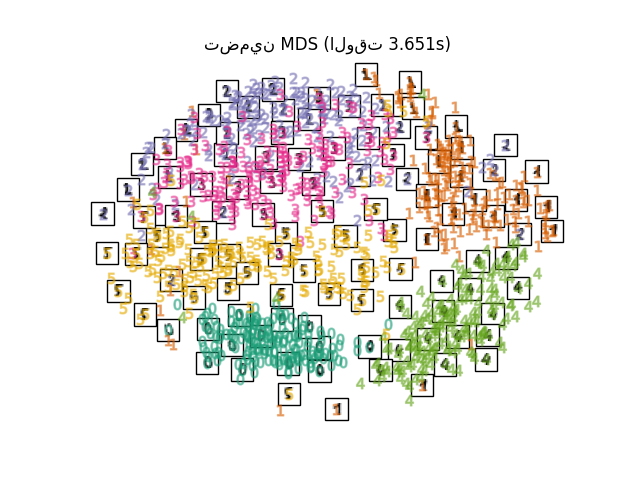
"تضمين MDS": MDS(n_components=2, n_init=1, max_iter=120, n_jobs=2),
"تضمين الأشجار العشوائية": make_pipeline(
RandomTreesEmbedding(n_estimators=200, max_depth=5, random_state=0),
TruncatedSVD(n_components=2),
),
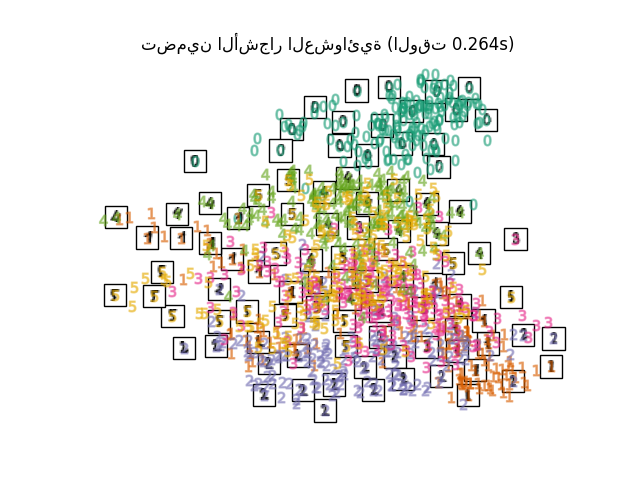
"تضمين الطيف": SpectralEmbedding(
n_components=2, random_state=0, eigen_solver="arpack"
),
"تضمين t-SNE": TSNE(
n_components=2,
max_iter=500,
n_iter_without_progress=150,
n_jobs=2,
random_state=0,
),
"تضمين NCA": NeighborhoodComponentsAnalysis(
n_components=2, init="pca", random_state=0
),
}
بمجرد أن نعلن عن جميع الطرق ذات الأهمية، يمكننا تشغيل وإجراء إسقاط البيانات الأصلية. سنخزن البيانات المسقطة بالإضافة إلى الوقت الحسابي اللازم لإجراء كل إسقاط.
from time import time
projections, timing = {}, {}
for name, transformer in embeddings.items():
if name.startswith("تحليل التمايز الخطي"):
data = X.copy()
data.flat[:: X.shape[1] + 1] += 0.01 # Make X invertible
else:
data = X
print(f"حساب {name}...")
start_time = time()
projections[name] = transformer.fit_transform(data, y)
timing[name] = time() - start_time
حساب تضمين الإسقاط العشوائي...
حساب تضمين SVD المبتور...
حساب تضمين تحليل التمايز الخطي...
حساب تضمين Isomap...
حساب تضمين LLE القياسي...
حساب تضمين LLE المعدل...
حساب تضمين Hessian LLE...
حساب تضمين LTSA LLE...
حساب تضمين MDS...
حساب تضمين الأشجار العشوائية...
حساب تضمين الطيف...
حساب تضمين t-SNE...
حساب تضمين NCA...
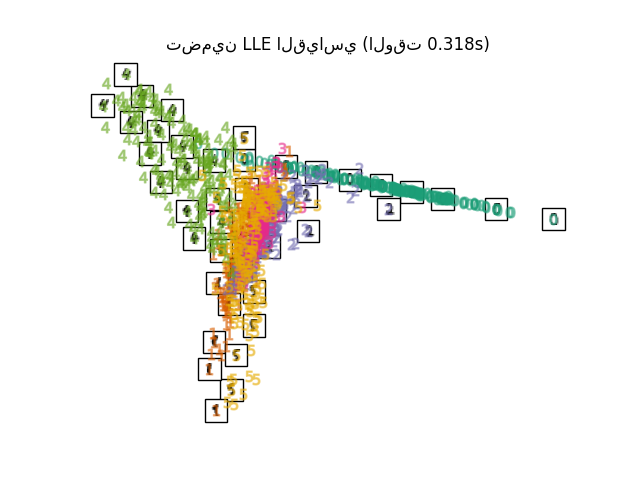
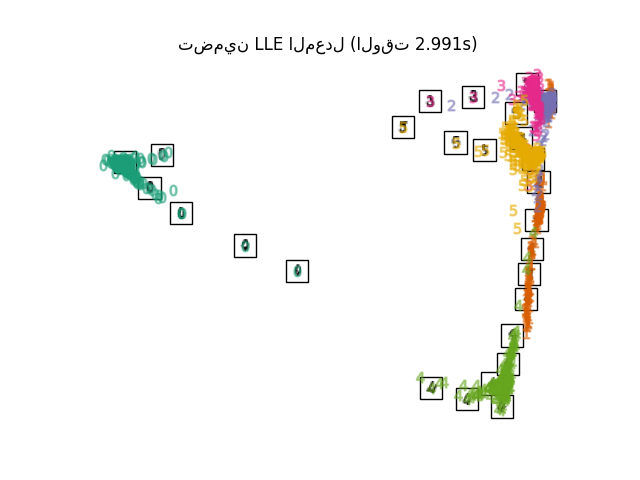
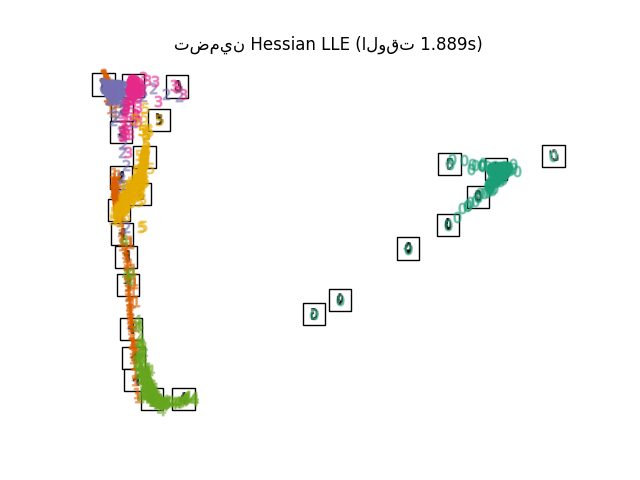
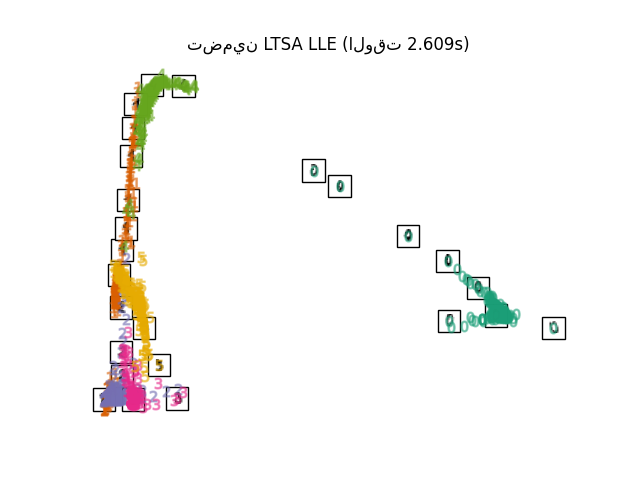
أخيرًا، يمكننا رسم الإسقاط الناتج المعطى بواسطة كل طريقة.
for name in timing:
title = f"{name} (الوقت {timing[name]:.3f}s)"
plot_embedding(projections[name], title)
plt.show()
Total running time of the script: (0 minutes 24.242 seconds)
Related examples
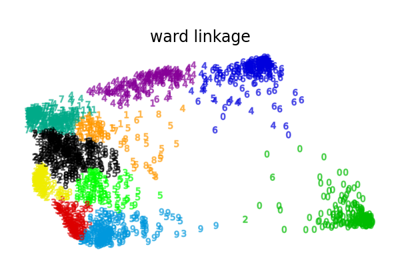
مختلف خوارزميات التجميع الهرمي على تضمين ثنائي الأبعاد لمجموعة بيانات الأرقام
خفض اللفافة السويسرية واللفافة السويسرية ذات الثقب