ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
مقارنة استراتيجيات التعلم العشوائي لتصنيف الشبكة العصبية متعددة الطبقات#
هذا المثال يوضح بعض منحنيات الخسارة التدريبية لاستراتيجيات التعلم العشوائي المختلفة، بما في ذلك SGD و Adam. بسبب قيود الوقت، نستخدم عدة مجموعات بيانات صغيرة، والتي قد تكون مناسبة أكثر لخوارزمية L-BFGS. ومع ذلك، يبدو أن الاتجاه العام الموضح في هذه الأمثلة ينطبق أيضًا على مجموعات البيانات الأكبر.
ملاحظة: يمكن أن تعتمد هذه النتائج بشكل كبير على قيمة "learning_rate_init".
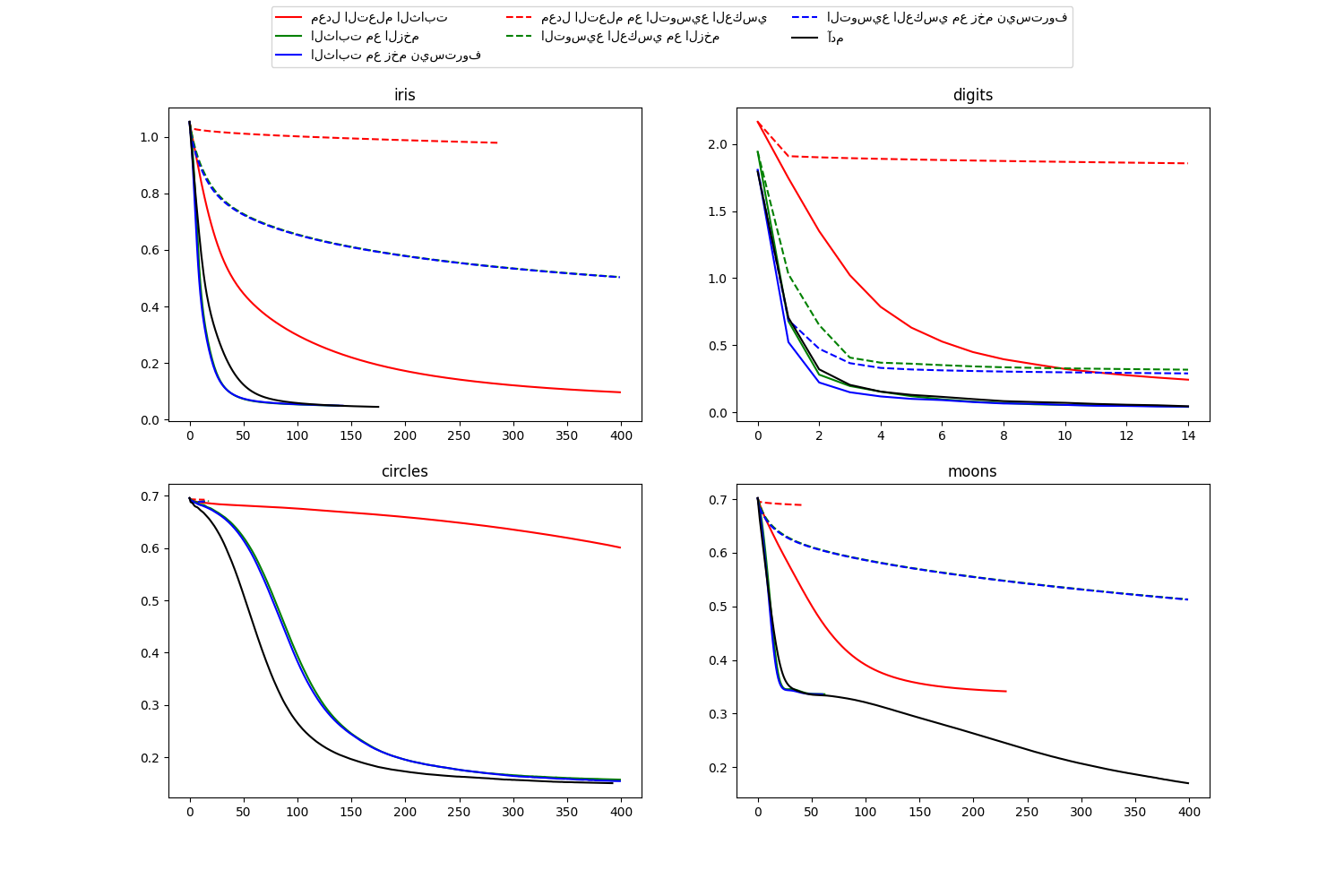
التعلم على مجموعة البيانات iris
التدريب: معدل التعلم الثابت
درجة مجموعة التدريب: 0.980000
خسارة مجموعة التدريب: 0.096950
التدريب: الثابت مع الزخم
درجة مجموعة التدريب: 0.980000
خسارة مجموعة التدريب: 0.049530
التدريب: الثابت مع زخم نيستروف
درجة مجموعة التدريب: 0.980000
خسارة مجموعة التدريب: 0.049540
التدريب: معدل التعلم مع التوسيع العكسي
درجة مجموعة التدريب: 0.360000
خسارة مجموعة التدريب: 0.978444
التدريب: التوسيع العكسي مع الزخم
درجة مجموعة التدريب: 0.860000
خسارة مجموعة التدريب: 0.504185
التدريب: التوسيع العكسي مع زخم نيستروف
درجة مجموعة التدريب: 0.860000
خسارة مجموعة التدريب: 0.503452
التدريب: آدم
درجة مجموعة التدريب: 0.980000
خسارة مجموعة التدريب: 0.045311
التعلم على مجموعة البيانات digits
التدريب: معدل التعلم الثابت
درجة مجموعة التدريب: 0.956038
خسارة مجموعة التدريب: 0.243802
التدريب: الثابت مع الزخم
درجة مجموعة التدريب: 0.992766
خسارة مجموعة التدريب: 0.041297
التدريب: الثابت مع زخم نيستروف
درجة مجموعة التدريب: 0.993879
خسارة مجموعة التدريب: 0.042898
التدريب: معدل التعلم مع التوسيع العكسي
درجة مجموعة التدريب: 0.638843
خسارة مجموعة التدريب: 1.855465
التدريب: التوسيع العكسي مع الزخم
درجة مجموعة التدريب: 0.909293
خسارة مجموعة التدريب: 0.318387
التدريب: التوسيع العكسي مع زخم نيستروف
درجة مجموعة التدريب: 0.912632
خسارة مجموعة التدريب: 0.290584
التدريب: آدم
درجة مجموعة التدريب: 0.991653
خسارة مجموعة التدريب: 0.045934
التعلم على مجموعة البيانات circles
التدريب: معدل التعلم الثابت
درجة مجموعة التدريب: 0.840000
خسارة مجموعة التدريب: 0.601052
التدريب: الثابت مع الزخم
درجة مجموعة التدريب: 0.940000
خسارة مجموعة التدريب: 0.157334
التدريب: الثابت مع زخم نيستروف
درجة مجموعة التدريب: 0.940000
خسارة مجموعة التدريب: 0.154453
التدريب: معدل التعلم مع التوسيع العكسي
درجة مجموعة التدريب: 0.500000
خسارة مجموعة التدريب: 0.692470
التدريب: التوسيع العكسي مع الزخم
درجة مجموعة التدريب: 0.500000
خسارة مجموعة التدريب: 0.689751
التدريب: التوسيع العكسي مع زخم نيستروف
درجة مجموعة التدريب: 0.500000
خسارة مجموعة التدريب: 0.689143
التدريب: آدم
درجة مجموعة التدريب: 0.940000
خسارة مجموعة التدريب: 0.150527
التعلم على مجموعة البيانات moons
التدريب: معدل التعلم الثابت
درجة مجموعة التدريب: 0.850000
خسارة مجموعة التدريب: 0.341523
التدريب: الثابت مع الزخم
درجة مجموعة التدريب: 0.850000
خسارة مجموعة التدريب: 0.336188
التدريب: الثابت مع زخم نيستروف
درجة مجموعة التدريب: 0.850000
خسارة مجموعة التدريب: 0.335919
التدريب: معدل التعلم مع التوسيع العكسي
درجة مجموعة التدريب: 0.500000
خسارة مجموعة التدريب: 0.689015
التدريب: التوسيع العكسي مع الزخم
درجة مجموعة التدريب: 0.830000
خسارة مجموعة التدريب: 0.513034
التدريب: التوسيع العكسي مع زخم نيستروف
درجة مجموعة التدريب: 0.830000
خسارة مجموعة التدريب: 0.512595
التدريب: آدم
درجة مجموعة التدريب: 0.930000
خسارة مجموعة التدريب: 0.170087
# المؤلفون: مطوري مكتبة ساي كيت ليرن
# معرف الترخيص: BSD-3-Clause
import warnings
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.exceptions import ConvergenceWarning
from sklearn.neural_network import MLPClassifier
from sklearn.preprocessing import MinMaxScaler
# معدلات تعلم مختلفة وجداول زمنية ومعاملات الزخم
params = [
{
"solver": "sgd",
"learning_rate": "constant",
"momentum": 0,
"learning_rate_init": 0.2,
},
{
"solver": "sgd",
"learning_rate": "constant",
"momentum": 0.9,
"nesterovs_momentum": False,
"learning_rate_init": 0.2,
},
{
"solver": "sgd",
"learning_rate": "constant",
"momentum": 0.9,
"nesterovs_momentum": True,
"learning_rate_init": 0.2,
},
{
"solver": "sgd",
"learning_rate": "invscaling",
"momentum": 0,
"learning_rate_init": 0.2,
},
{
"solver": "sgd",
"learning_rate": "invscaling",
"momentum": 0.9,
"nesterovs_momentum": False,
"learning_rate_init": 0.2,
},
{
"solver": "sgd",
"learning_rate": "invscaling",
"momentum": 0.9,
"nesterovs_momentum": True,
"learning_rate_init": 0.2,
},
{"solver": "adam", "learning_rate_init": 0.01},
]
labels = [
"معدل التعلم الثابت",
"الثابت مع الزخم",
"الثابت مع زخم نيستروف",
"معدل التعلم مع التوسيع العكسي",
"التوسيع العكسي مع الزخم",
"التوسيع العكسي مع زخم نيستروف",
"آدم",
]
plot_args = [
{"c": "red", "linestyle": "-"},
{"c": "green", "linestyle": "-"},
{"c": "blue", "linestyle": "-"},
{"c": "red", "linestyle": "--"},
{"c": "green", "linestyle": "--"},
{"c": "blue", "linestyle": "--"},
{"c": "black", "linestyle": "-"},
]
def plot_on_dataset(X, y, ax, name):
# لكل مجموعة بيانات، قم برسم منحنى التعلم لكل استراتيجية تعلم
print("\nالتعلم على مجموعة البيانات %s" % name)
ax.set_title(name)
X = MinMaxScaler().fit_transform(X)
mlps = []
if name == "digits":
# مجموعة digits أكبر ولكن تتقارب بشكل سريع نسبيًا
max_iter = 15
else:
max_iter = 400
for label, param in zip(labels, params):
print("التدريب: %s" % label)
mlp = MLPClassifier(random_state=0, max_iter=max_iter, **param)
# بعض تركيبات المعاملات لن تتقارب كما هو موضح في الرسوم البيانية، لذلك يتم تجاهلها هنا
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore", category=ConvergenceWarning, module="sklearn"
)
mlp.fit(X, y)
mlps.append(mlp)
print("درجة مجموعة التدريب: %f" % mlp.score(X, y))
print("خسارة مجموعة التدريب: %f" % mlp.loss_)
for mlp, label, args in zip(mlps, labels, plot_args):
ax.plot(mlp.loss_curve_, label=label, **args)
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# تحميل / توليد بعض مجموعات البيانات التجريبية
iris = datasets.load_iris()
X_digits, y_digits = datasets.load_digits(return_X_y=True)
data_sets = [
(iris.data, iris.target),
(X_digits, y_digits),
datasets.make_circles(noise=0.2, factor=0.5, random_state=1),
datasets.make_moons(noise=0.3, random_state=0),
]
for ax, data, name in zip(
axes.ravel(), data_sets, ["iris", "digits", "circles", "moons"]
):
plot_on_dataset(*data, ax=ax, name=name)
fig.legend(ax.get_lines(), labels, ncol=3, loc="upper center")
plt.show()
Total running time of the script: (0 minutes 3.636 seconds)
Related examples

تصور أوزان الشبكة العصبية متعددة الطبقات على مجموعة بيانات MNIST
تصور أوزان الشبكة العصبية متعددة الطبقات على مجموعة بيانات MNIST