ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
فهم بنية شجرة القرار#
يمكن تحليل بنية شجرة القرار للحصول على نظرة ثاقبة حول العلاقة بين الميزات والهدف المراد التنبؤ به. في هذا المثال، نُظهر كيفية استرجاع:
بنية الشجرة الثنائية؛
عمق كل عقدة وما إذا كانت ورقة أم لا؛
العقد التي تم الوصول إليها بواسطة عينة باستخدام طريقة
decision_path؛الورقة التي تم الوصول إليها بواسطة عينة باستخدام طريقة التطبيق؛
القواعد التي تم استخدامها للتنبؤ بعينة؛
مسار القرار المشترك بين مجموعة من العينات.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
تدريب مصنف الشجرة#
أولاً، نقوم بضبط مصنف DecisionTreeClassifier باستخدام
مجموعة بيانات load_iris.
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
clf = DecisionTreeClassifier(max_leaf_nodes=3, random_state=0)
clf.fit(X_train, y_train)
بنية الشجرة#
لمصنف القرار خاصية تسمى tree_ والتي تسمح بالوصول
إلى الخصائص منخفضة المستوى مثل node_count، العدد الإجمالي للعقد،
و max_depth، العمق الأقصى للشجرة. طريقة tree_.compute_node_depths() تحسب عمق كل عقدة في
الشجرة. tree_ تخزن أيضًا بنية الشجرة الثنائية الكاملة، ممثلة كعدد من المصفوفات المتوازية. العنصر i-th من كل مصفوفة
يحتوي على معلومات
حول العقدة i. العقدة 0 هي جذر الشجرة. بعض المصفوفات
تنطبق فقط إما على الأوراق أو عقد الانقسام. في هذه الحالة، تكون قيم عقد
النوع الآخر عشوائية. على سبيل المثال، المصفوفات feature و
threshold تنطبق فقط على عقد الانقسام. لذلك، تكون قيم عقد الأوراق في هذه
المصفوفات عشوائية.
من بين هذه المصفوفات، لدينا:
children_left[i]: معرف العقدة اليسرى للعقدةiأو -1 إذا كانت عقدة ورقةchildren_right[i]: معرف العقدة اليمنى للعقدةiأو -1 إذا كانت عقدة ورقةfeature[i]: الميزة المستخدمة لتقسيم العقدةithreshold[i]: قيمة العتبة في العقدةin_node_samples[i]: عدد العينات التدريبية التي تصل إلى العقدةiimpurity[i]: عدم النقاء في العقدةiweighted_n_node_samples[i]: العدد المرجح لعينات التدريب التي تصل إلى العقدةivalue[i, j, k]: ملخص عينات التدريب التي وصلت إلى العقدة i لل الإخراج j والصنف k (لشجرة الانحدار، يتم تعيين الصنف إلى 1). انظر أدناه لمزيد من المعلومات حولvalue.
باستخدام المصفوفات، يمكننا عبور بنية الشجرة لحساب خصائص مختلفة. أدناه، سنحسب عمق كل عقدة وما إذا كانت ورقة أم لا.
n_nodes = clf.tree_.node_count
children_left = clf.tree_.children_left
children_right = clf.tree_.children_right
feature = clf.tree_.feature
threshold = clf.tree_.threshold
values = clf.tree_.value
node_depth = np.zeros(shape=n_nodes, dtype=np.int64)
is_leaves = np.zeros(shape=n_nodes, dtype=bool)
stack = [(0, 0)] # ابدأ بمعرف العقدة الجذر (0) وعمقه (0)
while len(stack) > 0:
# `pop` يضمن زيارة كل عقدة مرة واحدة فقط
node_id, depth = stack.pop()
node_depth[node_id] = depth
# إذا كان الطفل الأيسر والطفل الأيمن للعقدة ليسا متساويين، فإن لدينا عقدة انقسام
#
is_split_node = children_left[node_id] != children_right[node_id]
# إذا كانت عقدة انقسام، أضف الطفل الأيسر والطفل الأيمن والعمق إلى `stack`
# حتى نتمكن من المرور خلالهم
if is_split_node:
stack.append((children_left[node_id], depth + 1))
stack.append((children_right[node_id], depth + 1))
else:
is_leaves[node_id] = True
print(
"The binary tree structure has {n} nodes and has "
"the following tree structure:\n".format(n=n_nodes)
)
for i in range(n_nodes):
if is_leaves[i]:
print(
"{space}node={node} is a leaf node with value={value}.".format(
space=node_depth[i] * "\t", node=i, value=np.around(values[i], 3)
)
)
else:
print(
"{space}node={node} is a split node with value={value}: "
"go to node {left} if X[:, {feature}] <= {threshold} "
"else to node {right}.".format(
space=node_depth[i] * "\t",
node=i,
left=children_left[i],
feature=feature[i],
threshold=threshold[i],
right=children_right[i],
value=np.around(values[i], 3),
)
)
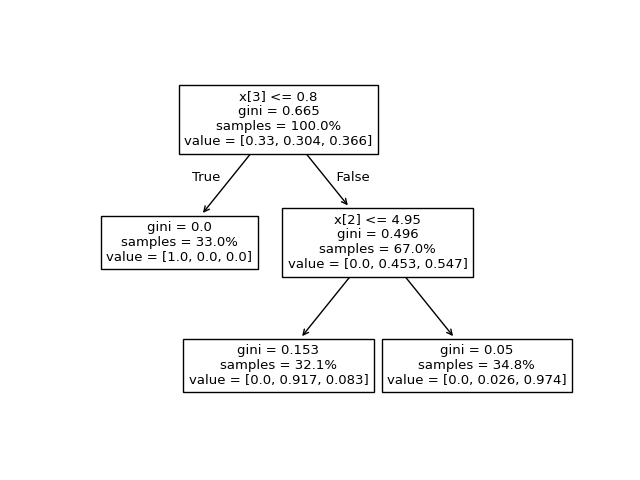
The binary tree structure has 5 nodes and has the following tree structure:
node=0 is a split node with value=[[0.33 0.304 0.366]]: go to node 1 if X[:, 3] <= 0.800000011920929 else to node 2.
node=1 is a leaf node with value=[[1. 0. 0.]].
node=2 is a split node with value=[[0. 0.453 0.547]]: go to node 3 if X[:, 2] <= 4.950000047683716 else to node 4.
node=3 is a leaf node with value=[[0. 0.917 0.083]].
node=4 is a leaf node with value=[[0. 0.026 0.974]].
ما هو مصفوفة القيم المستخدمة هنا؟#
مصفوفة tree_.value هي مصفوفة ثلاثية الأبعاد من الشكل
[n_nodes، n_classes، n_outputs] والتي توفر نسبة العينات
التي تصل إلى عقدة لكل صنف ولكل إخراج.
لكل عقدة مصفوفة value والتي هي نسبة العينات المرجحة التي تصل
إلى هذه العقدة لكل إخراج وصنف فيما يتعلق بالعقدة الأصل.
يمكن للمرء تحويل هذا إلى العدد المطلق للعينات المرجحة التي تصل إلى عقدة،
من خلال ضرب هذا العدد بـ tree_.weighted_n_node_samples[node_idx] للعقدة
المعطاة. لاحظ أن أوزان العينات لا تستخدم في هذا المثال، لذلك العدد المرجح
للعينات هو عدد العينات التي تصل إلى العقدة لأن كل عينة
لها وزن 1 بشكل افتراضي.
على سبيل المثال، في الشجرة أعلاه المبنية على مجموعة بيانات الزهرة، تحتوي العقدة الجذر على
value = [0.33, 0.304, 0.366] مما يشير إلى وجود 33% من العينات من الصنف 0،
30.4% من العينات من الصنف 1، و 36.6% من العينات من الصنف 2 في العقدة الجذر. يمكن للمرء
تحويل هذا إلى العدد المطلق للعينات من خلال الضرب في عدد
العينات التي تصل إلى العقدة الجذر، والتي هي tree_.weighted_n_node_samples[0].
ثم تحتوي العقدة الجذر على value = [37, 34, 41]، مما يشير إلى وجود 37 عينة
من الصنف 0، و 34 عينة من الصنف 1، و 41 عينة من الصنف 2 في العقدة الجذر.
عند عبور الشجرة، تنقسم العينات ونتيجة لذلك، تتغير مصفوفة value
التي تصل إلى كل عقدة. الطفل الأيسر للعقدة الجذر لديه value = [1., 0, 0]
(أو value = [37, 0, 0] عند تحويلها إلى العدد المطلق للعينات)
لأن جميع العينات الـ 37 في العقدة الطفل اليسرى هي من الصنف 0.
ملاحظة: في هذا المثال، n_outputs=1، ولكن يمكن لمصنف الشجرة أيضًا التعامل
مع المشاكل متعددة الإخراج. ستكون مصفوفة value في كل عقدة مجرد مصفوفة ثنائية الأبعاد
بدلاً من ذلك.
يمكننا مقارنة الإخراج أعلاه برسم شجرة القرار.
هنا، نُظهر نسب عينات كل صنف التي تصل إلى كل
عقدة مطابقة للعناصر الفعلية لمصفوفة tree_.value.
tree.plot_tree(clf, proportion=True)
plt.show()
مسار القرار#
يمكننا أيضًا استرجاع مسار القرار لعينات الاهتمام.
طريقة decision_path تُخرج مصفوفة مؤشر تسمح لنا
باسترجاع العقد التي تمر عبرها عينات الاهتمام. عنصر غير صفري
في مصفوفة المؤشر في الموضع (i, j) يشير إلى أن
العينة i تمر عبر العقدة j. أو، لعينة واحدة i،
تحدد مواضع العناصر غير الصفرية في الصف i من مصفوفة المؤشر
معرّفات العقد التي تمر عبرها العينة.
يمكن الحصول على معرّفات الأوراق التي وصلت إليها عينات الاهتمام باستخدام
طريقة apply. هذا يعيد مصفوفة من معرّفات عقد الأوراق
التي وصلت إليها كل عينة من عينات الاهتمام. باستخدام معرّفات الأوراق و
decision_path يمكننا الحصول على شروط التقسيم التي تم استخدامها
للتنبؤ بعينة أو مجموعة من العينات. أولاً، دعنا نفعل ذلك لعينة واحدة.
لاحظ أن node_index هي مصفوفة نادرة.
node_indicator = clf.decision_path(X_test)
leaf_id = clf.apply(X_test)
sample_id = 0
# الحصول على معرّفات العقد التي تمر عبرها العينة `sample_id`، أي الصف `sample_id`
node_index = node_indicator.indices[
node_indicator.indptr[sample_id] : node_indicator.indptr[sample_id + 1]
]
print("Rules used to predict sample {id}:\n".format(id=sample_id))
for node_id in node_index:
# استمر إلى العقدة التالية إذا كانت عقدة ورقة
if leaf_id[sample_id] == node_id:
continue
# تحقق إذا كانت قيمة ميزة التقسيم للعينة 0 أقل من العتبة
if X_test[sample_id, feature[node_id]] <= threshold[node_id]:
threshold_sign = "<="
else:
threshold_sign = ">"
print(
"decision node {node} : (X_test[{sample}, {feature}] = {value}) "
"{inequality} {threshold})".format(
node=node_id,
sample=sample_id,
feature=feature[node_id],
value=X_test[sample_id, feature[node_id]],
inequality=threshold_sign,
threshold=threshold[node_id],
)
)
Rules used to predict sample 0:
decision node 0 : (X_test[0, 3] = 2.4) > 0.800000011920929)
decision node 2 : (X_test[0, 2] = 5.1) > 4.950000047683716)
لمجموعة من العينات، يمكننا تحديد العقد المشتركة التي تمر عبرها العينات.
sample_ids = [0, 1]
# مصفوفة منطقية تشير إلى العقد التي تمر عبرها كلتا العينتين
common_nodes = node_indicator.toarray()[sample_ids].sum(axis=0) == len(sample_ids)
# الحصول على معرّفات العقد باستخدام الموضع في المصفوفة
common_node_id = np.arange(n_nodes)[common_nodes]
print(
"\nThe following samples {samples} share the node(s) {nodes} in the tree.".format(
samples=sample_ids, nodes=common_node_id
)
)
print("This is {prop}% of all nodes.".format(prop=100 * len(common_node_id) / n_nodes))
The following samples [0, 1] share the node(s) [0 2] in the tree.
This is 40.0% of all nodes.
Total running time of the script: (0 minutes 0.093 seconds)
Related examples
تشذيب أشجار القرار بعد التدريب باستخدام تقنية تشذيب تعقيد التكلفة
رسم سطح القرار لأشجار القرار المدربة على مجموعة بيانات الزهرة الآرغوانية

تناسب شبكة مرنة مع مصفوفة جرام مسبقة الحساب وعينات مرجحة