ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
SVM-Anova: SVM مع اختيار الميزات أحادية المتغير#
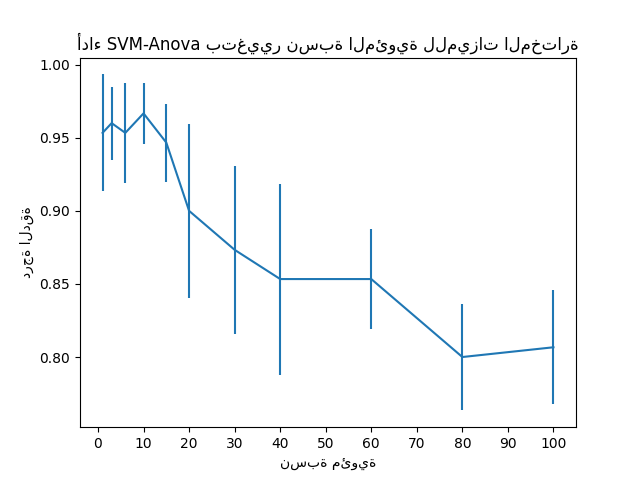
هذا المثال يوضح كيفية إجراء اختيار الميزات أحادية المتغير قبل تشغيل SVC (مصنف المتجه الداعم) لتحسين درجات التصنيف. نحن نستخدم مجموعة بيانات الزهرة (4 ميزات) ونضيف 36 ميزة غير إعلامية. يمكننا أن نجد أن نموذجنا يحقق أفضل أداء عندما نختار حوالي 10% من الميزات.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
تحميل بعض البيانات للتجربة#
import numpy as np
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
# إضافة ميزات غير إعلامية
rng = np.random.RandomState(0)
X = np.hstack((X, 2 * rng.random((X.shape[0], 36))))
إنشاء خط الأنابيب#
from sklearn.feature_selection import SelectPercentile, f_classif
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# إنشاء تحويل اختيار الميزات، ومقياس، ونسخة من SVM التي
# نجمعها معًا للحصول على أداة تقدير كاملة
clf = Pipeline(
[
("anova", SelectPercentile(f_classif)),
("scaler", StandardScaler()),
("svc", SVC(gamma="auto")),
]
)
رسم متوسط درجات التحقق الصليبي كدالة لنسبة المئوية للميزات#
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
score_means = list()
score_stds = list()
percentiles = (1, 3, 6, 10, 15, 20, 30, 40, 60, 80, 100)
for percentile in percentiles:
clf.set_params(anova__percentile=percentile)
this_scores = cross_val_score(clf, X, y)
score_means.append(this_scores.mean())
score_stds.append(this_scores.std())
plt.errorbar(percentiles, score_means, np.array(score_stds))
plt.title("أداء SVM-Anova بتغيير نسبة المئوية للميزات المختارة")
plt.xticks(np.linspace(0, 100, 11, endpoint=True))
plt.xlabel("نسبة مئوية")
plt.ylabel("درجة الدقة")
plt.axis("tight")
plt.show()
Total running time of the script: (0 minutes 0.415 seconds)
Related examples

رسم مخططات لمصنفات SVM المختلفة في مجموعة بيانات الزهرة
رسم مخططات لمصنفات SVM المختلفة في مجموعة بيانات الزهرة
