ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
مقارنة بين FeatureHasher و DictVectorizer#
في هذا المثال، نوضح عملية تمثيل ناقلات النصوص، وهي عملية تمثيل بيانات الإدخال غير الرقمية (مثل القواميس أو وثائق النصوص) كمتجهات من الأعداد الحقيقية.
نقارن أولاً بين FeatureHasher و
DictVectorizer باستخدام كلتا الطريقتين لتمثيل ناقلات وثائق النصوص التي تتم معالجتها مسبقًا (تجزيئها) بمساعدة دالة بايثون مخصصة.
فيما بعد، نقدم ونحلل ناقلات النصوص المخصصة:
HashingVectorizer،
CountVectorizer و
TfidfVectorizer التي تتعامل مع كل من تجزيء النصوص وتجميع مصفوفة الخصائص ضمن فئة واحدة.
هدف المثال هو توضيح استخدام واجهة برمجة التطبيقات (API) لتمثيل ناقلات النصوص ومقارنة أوقات معالجتها. راجع نصوص الأمثلة تصنيف وثائق النصوص باستخدام الميزات المتناثرة و تجميع مستندات النص باستخدام k-means للتعلم الفعلي على وثائق النصوص.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
تحميل البيانات#
نقوم بتحميل البيانات من The 20 newsgroups text dataset، والتي تتضمن حوالي 18000 منشورات مجموعات الأخبار حول 20 موضوعًا مقسمة إلى مجموعتين: واحدة للتدريب والأخرى للاختبار. من أجل البساطة وتقليل التكلفة الحسابية، نختار مجموعة فرعية من 7 مواضيع ونستخدم مجموعة التدريب فقط.
from sklearn.datasets import fetch_20newsgroups
categories = [
"alt.atheism",
"comp.graphics",
"comp.sys.ibm.pc.hardware",
"misc.forsale",
"rec.autos",
"sci.space",
"talk.religion.misc",
]
print("تحميل بيانات تدريب مجموعات الأخبار 20")
raw_data, _ = fetch_20newsgroups(subset="train", categories=categories, return_X_y=True)
data_size_mb = sum(len(s.encode("utf-8")) for s in raw_data) / 1e6
print(f"{len(raw_data)} وثائق - {data_size_mb:.3f}MB")
تحميل بيانات تدريب مجموعات الأخبار 20
3803 وثائق - 6.245MB
تحديد دالات ما قبل المعالجة#
قد يكون الرمز عبارة عن كلمة، أو جزء من كلمة، أو أي شيء يقع بين المسافات أو الرموز في سلسلة. هنا، نحدد دالة تستخرج الرموز باستخدام تعبير عادي (regex) بسيط يطابق حروف الكلمات. وهذا يشمل معظم الرموز التي يمكن أن تكون جزءًا من كلمة في أي لغة، بالإضافة إلى الأرقام وخط التحتية:
import re
def tokenize(doc):
"""استخراج الرموز من doc.
يستخدم هذا تعبيرًا عاديًا بسيطًا يطابق حروف الكلمات لتقسيم السلاسل
إلى رموز. للحصول على نهج أكثر مبدأية، راجع CountVectorizer أو
TfidfVectorizer.
"""
return (tok.lower() for tok in re.findall(r"\w+", doc))
list(tokenize("This is a simple example, isn't it?"))
['this', 'is', 'a', 'simple', 'example', 'isn', 't', 'it']
نحدد دالة إضافية تحسب (تكرار) حدوث كل رمز في وثيقة معينة. تعيد دالة قاموس الترددات لاستخدامها بواسطة ناقلات النصوص.
from collections import defaultdict
def token_freqs(doc):
"""استخراج قاموس يُمَثِل خريطة من الرموز في doc إلى تكراراتها."""
freq = defaultdict(int)
for tok in tokenize(doc):
freq[tok] += 1
return freq
token_freqs("That is one example, but this is another one")
defaultdict(<class 'int'>, {'that': 1, 'is': 2, 'one': 2, 'example': 1, 'but': 1, 'this': 1, 'another': 1})
لاحظ على وجه الخصوص أن الرمز المتكرر "is" يتم حسابه مرتين على سبيل
المثال.
إن تقسيم وثيقة نصية إلى رموز كلمات، مع فقدان محتمل لمعلومات الترتيب بين الكلمات في جملة، يُطلق عليه غالبًا تمثيل "حقيبة الكلمات <https://en.wikipedia.org/wiki/Bag-of-words_model>`_".
DictVectorizer#
أولاً، نقوم باختبار أداء DictVectorizer،
ثم نقارنه بـ FeatureHasher حيث أن كلاهما
يستقبل القواميس كمدخلات.
from time import time
from sklearn.feature_extraction import DictVectorizer
dict_count_vectorizers = defaultdict(list)
t0 = time()
vectorizer = DictVectorizer()
vectorizer.fit_transform(token_freqs(d) for d in raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(
vectorizer.__class__.__name__ + "\non freq dicts"
)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {len(vectorizer.get_feature_names_out())} unique terms")
done in 1.418 s at 4.4 MB/s
Found 47928 unique terms
يتم تخزين الخريطة الفعلية من رموز النص إلى فهرس العمود بشكل صريح في
سمة .vocabulary_ والتي هي عبارة عن قاموس بايثون كبير محتمل:
type(vectorizer.vocabulary_)
len(vectorizer.vocabulary_)
47928
vectorizer.vocabulary_["example"]
19145
FeatureHasher#
تأخذ القواميس مساحة تخزين كبيرة وتنمو في الحجم مع نمو مجموعة التدريب. بدلاً من
زيادة حجم المتجهات مع القاموس، يقوم تمثيل الخصائص الهاشة ببناء متجه من
طول محدد مسبقًا عن طريق تطبيق دالة هاش h على الخصائص (مثل الرموز)، ثم
استخدام قيم الهاش مباشرةً كفهرس للخصائص وتحديث المتجه الناتج عند تلك
الفهارس. عندما لا تكون مساحة الخصائص كبيرة بما يكفي، تميل دالات الهاش إلى
تعيين قيم متميزة إلى نفس كود الهاش (اصطدامات الهاش). ونتيجة لذلك، من
المستحيل تحديد الكائن الذي أنتج أي كود هاش معين.
بسبب ما سبق، من المستحيل استعادة الرموز الأصلية من مصفوفة الخصائص، وأفضل نهج لتقدير عدد المصطلحات الفريدة في القاموس الأصلي هو حساب عدد الأعمدة النشطة في مصفوفة الخصائص المشفرة. لهذا الغرض، نحدد الدالة التالية:
import numpy as np
def n_nonzero_columns(X):
"""عدد الأعمدة التي تحتوي على قيمة غير صفرية واحدة على الأقل في مصفوفة CSR.
هذا مفيد لحساب عدد أعمدة الخصائص التي تكون نشطة بشكل فعال عند استخدام
FeatureHasher.
"""
return len(np.unique(X.nonzero()[1]))
العدد الافتراضي للخصائص لـ
FeatureHasher هو 2**20. هنا نحدد
n_features = 2**18 لتوضيح اصطدامات الهاش.
FeatureHasher على قواميس الترددات
from sklearn.feature_extraction import FeatureHasher
t0 = time()
hasher = FeatureHasher(n_features=2**18)
X = hasher.transform(token_freqs(d) for d in raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(
hasher.__class__.__name__ + "\non freq dicts"
)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {n_nonzero_columns(X)} unique tokens")
done in 0.824 s at 7.6 MB/s
Found 43873 unique tokens
عدد الرموز الفريدة عند استخدام
FeatureHasher أقل من تلك التي تم الحصول عليها
باستخدام DictVectorizer. ويرجع ذلك إلى
اصطدامات الهاش.
يمكن تقليل عدد الاصطدامات عن طريق زيادة مساحة الخصائص. لاحظ أن سرعة ناقلة الخصائص لا تتغير بشكل كبير عند تحديد عدد كبير من الخصائص، على الرغم من أنها تسبب أبعاد معاملات أكبر وتتطلب بالتالي استخدام ذاكرة أكبر لتخزينها، حتى لو كانت أغلبيتها غير نشطة.
t0 = time()
hasher = FeatureHasher(n_features=2**22)
X = hasher.transform(token_freqs(d) for d in raw_data)
duration = time() - t0
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {n_nonzero_columns(X)} unique tokens")
done in 0.826 s at 7.6 MB/s
Found 47668 unique tokens
نؤكد أن عدد الرموز الفريدة يقترب من عدد المصطلحات الفريدة التي وجدها
DictVectorizer.
FeatureHasher على الرموز الخام
بدلاً من ذلك، يمكنك تحديد input_type="string" في
FeatureHasher لتمثيل ناقلات السلاسل
الناتجة مباشرة من دالة tokenize المخصصة. وهذا يعادل تمرير قاموس مع
تكرار ضمني يساوي 1 لكل اسم خاصية.
t0 = time()
hasher = FeatureHasher(n_features=2**18, input_type="string")
X = hasher.transform(tokenize(d) for d in raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(
hasher.__class__.__name__ + "\non raw tokens"
)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {n_nonzero_columns(X)} unique tokens")
done in 0.781 s at 8.0 MB/s
Found 43873 unique tokens
نحن الآن نرسم سرعة الطرق المذكورة أعلاه لتمثيل ناقلات النصوص.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 6))
y_pos = np.arange(len(dict_count_vectorizers["vectorizer"]))
ax.barh(y_pos, dict_count_vectorizers["speed"], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels(dict_count_vectorizers["vectorizer"])
ax.invert_yaxis()
_ = ax.set_xlabel("السرعة (MB/s)")
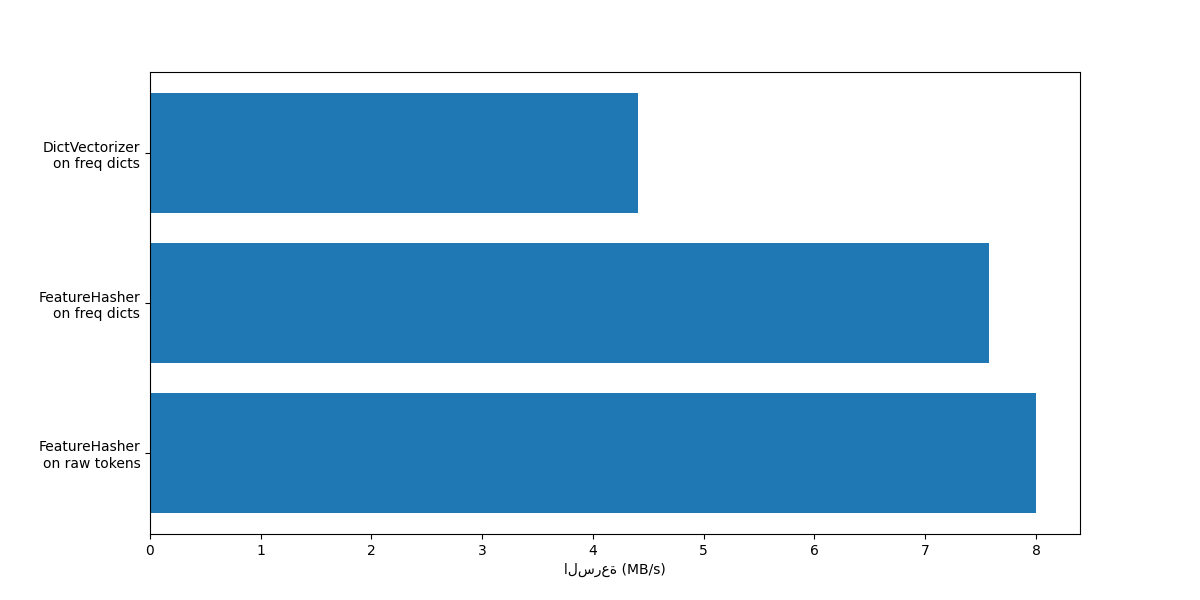
في كلتا الحالتين، FeatureHasher
أسرع مرتين تقريبًا من
DictVectorizer. وهذا مفيد عند التعامل
مع كميات كبيرة من البيانات، مع الجانب السلبي المتمثل في فقدان إمكانية
عكس التحويل، مما يجعل تفسير النموذج مهمة أكثر تعقيدًا.
إن FeatureHeasher مع input_type="string" أسرع قليلاً من المتغير الذي
يعمل على قاموس الترددات لأنه لا يحسب الرموز المتكررة: يتم حساب كل رمز
ضمنيًا مرة واحدة، حتى لو تكرر. وهذا يعتمد على مهمة التعلم الآلي
النهائية، فقد يكون هذا عيبًا أو لا.
المقارنة مع ناقلات النصوص المخصصة#
CountVectorizer يقبل البيانات الخام
حيث أنه ينفذ تجزيء النصوص وحساب الترددات داخليًا. وهو مشابه
لـ DictVectorizer عند استخدامه مع
دالة token_freqs المخصصة كما هو الحال في القسم السابق. الفرق هو أن
CountVectorizer أكثر مرونة.
على وجه الخصوص، يقبل أنماط تعبيرات عادية مختلفة من خلال معامل
token_pattern.
from sklearn.feature_extraction.text import CountVectorizer
t0 = time()
vectorizer = CountVectorizer()
vectorizer.fit_transform(raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(vectorizer.__class__.__name__)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {len(vectorizer.get_feature_names_out())} unique terms")
done in 0.771 s at 8.1 MB/s
Found 47885 unique terms
نلاحظ أن استخدام CountVectorizer
أسرع مرتين تقريبًا من استخدام
DictVectorizer مع الدالة البسيطة التي
حددناها لتمثيل خريطة الرموز. والسبب هو أن
CountVectorizer يتم تحسينه عن طريق
إعادة استخدام تعبير عادي مجمع للمجموعة التدريبية بالكامل بدلاً من
إنشاء واحد لكل وثيقة كما هو الحال في دالة tokenize البسيطة التي حددناها.
الآن، نجري تجربة مماثلة مع
HashingVectorizer، والتي
تعادل الجمع بين "خدعة الهاش" التي ينفذها
FeatureHasher ومعالجة النصوص
وتجزيئها في
CountVectorizer.
from sklearn.feature_extraction.text import HashingVectorizer
t0 = time()
vectorizer = HashingVectorizer(n_features=2**18)
vectorizer.fit_transform(raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(vectorizer.__class__.__name__)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
done in 0.690 s at 9.0 MB/s
يمكننا ملاحظة أن هذه هي أسرع استراتيجية لتجزيء النصوص حتى الآن، بافتراض أن مهمة التعلم الآلي النهائية يمكنها تحمل بعض الاصطدامات.
TfidfVectorizer#
في مجموعة نصوص كبيرة، تظهر بعض الكلمات بتردد أعلى (مثل "the"،
"a"، "is" في اللغة الإنجليزية) ولا تحمل معلومات ذات معنى حول المحتوى
الفعلي لوثيقة ما. إذا كنا سنقوم بتغذية بيانات تكرار الكلمات مباشرةً
إلى مصنف، فإن هذه المصطلحات الشائعة جدًا ستطغى على ترددات المصطلحات
النادرة ولكنها أكثر إفادة. من أجل إعادة وزن ميزات تكرار الكلمات إلى
قيم ذات أعداد عائمة مناسبة للاستخدام بواسطة مصنف، من الشائع جدًا
استخدام تحويل tf-idf كما ينفذه
TfidfTransformer. TF تعني
"تردد المصطلح" بينما "tf-idf" تعني تردد المصطلح مضروبًا في عكس
تردد الوثيقة.
نقوم الآن باختبار أداء TfidfVectorizer،
والذي يعادل الجمع بين تجزيء النصوص وحساب تردداتها في
CountVectorizer إلى جانب
التطبيع والوزن من
TfidfTransformer.
from sklearn.feature_extraction.text import TfidfVectorizer
t0 = time()
vectorizer = TfidfVectorizer()
vectorizer.fit_transform(raw_data)
duration = time() - t0
dict_count_vectorizers["vectorizer"].append(vectorizer.__class__.__name__)
dict_count_vectorizers["speed"].append(data_size_mb / duration)
print(f"done in {duration:.3f} s at {data_size_mb / duration:.1f} MB/s")
print(f"Found {len(vectorizer.get_feature_names_out())} unique terms")
done in 0.832 s at 7.5 MB/s
Found 47885 unique terms
ملخص#
دعونا نختتم هذا الدفتر بتلخيص جميع سرعات المعالجة المسجلة في مخطط واحد:
fig, ax = plt.subplots(figsize=(12, 6))
y_pos = np.arange(len(dict_count_vectorizers["vectorizer"]))
ax.barh(y_pos, dict_count_vectorizers["speed"], align="center")
ax.set_yticks(y_pos)
ax.set_yticklabels(dict_count_vectorizers["vectorizer"])
ax.invert_yaxis()
_ = ax.set_xlabel("السرعة (MB/s)")
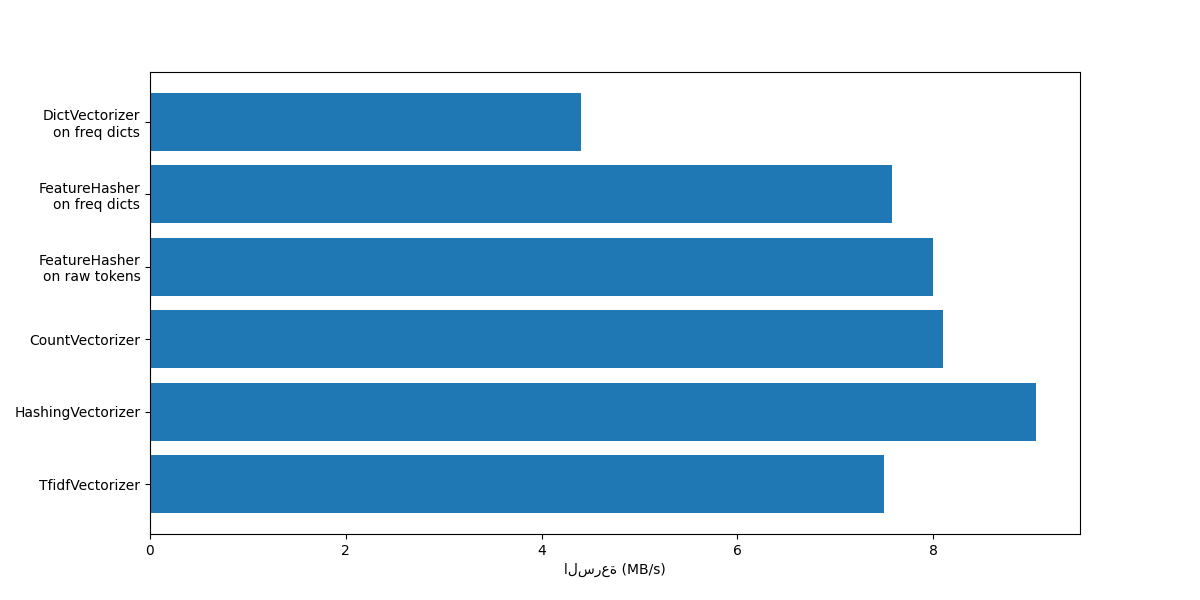
لاحظ من الرسم البياني أن
TfidfVectorizer أبطأ قليلاً
من CountVectorizer بسبب
العملية الإضافية الناتجة عن
TfidfTransformer.
لاحظ أيضًا أنه من خلال تعيين عدد الميزات n_features = 2**18، فإن
HashingVectorizer يعمل بشكل
أفضل من CountVectorizer على
حساب انعكاس التحويل بسبب تصادمات التجزئة.
نسلط الضوء على أن CountVectorizer و
HashingVectorizer يعملان بشكل
أفضل من DictVectorizer و
FeatureHasher على المستندات
المميزة يدويًا لأن خطوة التمييز الداخلية للناقلات الأولى
تقوم بتجميع تعبير عادي مرة واحدة ثم تعيد استخدامه لجميع المستندات.
Total running time of the script: (0 minutes 6.605 seconds)
Related examples

التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك