ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تقييم تجريبي لتأثير تهيئة k-means#
تقييم قدرة إستراتيجيات تهيئة k-means على جعل خوارزمية التقارب قوية، كما يقاس بالانحراف المعياري النسبي للقصور الذاتي للتجميع (أي مجموع مربعات المسافات إلى أقرب مركز للتجميع).
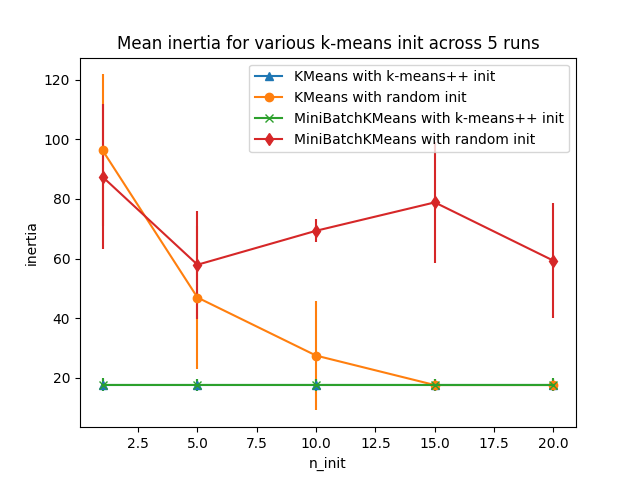
الرسم البياني الأول يظهر أفضل قصور ذاتي تم الوصول إليه لكل مجموعة
من النموذج (KMeans أو MiniBatchKMeans)، وطريقة التهيئة
(init="random" أو init="k-means++") لقيم متزايدة من المعامل
n_init الذي يتحكم في عدد التهيئات الأولية.
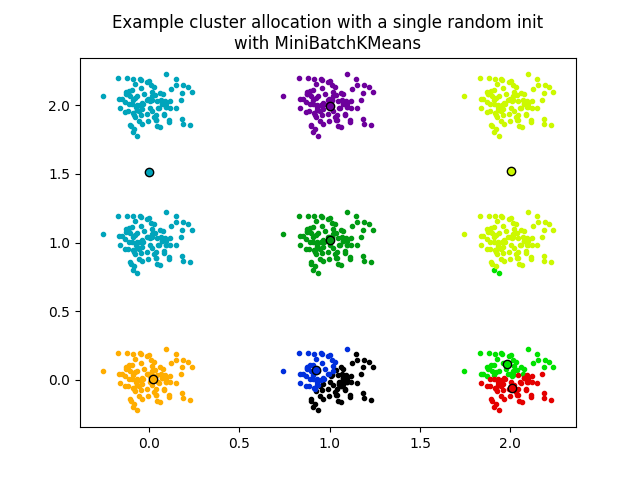
الرسم البياني الثاني يوضح تشغيل واحد للمقدر MiniBatchKMeans
باستخدام init="random" و n_init=1. هذا التشغيل يؤدي إلى
تقارب سيئ (مثالية جزئية)، مع مراكز مقدرة تعلق
بين التجميعات الحقيقية.
مجموعة البيانات المستخدمة للتقييم هي شبكة ثنائية الأبعاد من التوزيعات الغاوسية المتناظرة ومتباعدة بشكل واسع.
Evaluation of KMeans with k-means++ init
Evaluation of KMeans with random init
Evaluation of MiniBatchKMeans with k-means++ init
Evaluation of MiniBatchKMeans with random init
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans, MiniBatchKMeans
from sklearn.utils import check_random_state, shuffle
random_state = np.random.RandomState(0)
# عدد التشغيلات (مع مجموعة بيانات مولدة عشوائيًا) لكل استراتيجية حتى
# يمكن حساب تقدير للانحراف المعياري
n_runs = 5
# نماذج k-means يمكنها القيام بعدة تهيئات عشوائية حتى تتمكن من تبادل
# وقت CPU لتقوية التقارب
n_init_range = np.array([1, 5, 10, 15, 20])
# معلمات توليد مجموعات البيانات
n_samples_per_center = 100
grid_size = 3
scale = 0.1
n_clusters = grid_size**2
def make_data(random_state, n_samples_per_center, grid_size, scale):
random_state = check_random_state(random_state)
centers = np.array([[i, j] for i in range(grid_size)
for j in range(grid_size)])
n_clusters_true, n_features = centers.shape
noise = random_state.normal(
scale=scale, size=(n_samples_per_center, centers.shape[1])
)
X = np.concatenate([c + noise for c in centers])
y = np.concatenate(
[[i] * n_samples_per_center for i in range(n_clusters_true)])
return shuffle(X, y, random_state=random_state)
# الجزء الأول: التقييم الكمي لإستراتيجيات تهيئة مختلفة
plt.figure()
plots = []
legends = []
cases = [
(KMeans, "k-means++", {}, "^-"),
(KMeans, "random", {}, "o-"),
(MiniBatchKMeans, "k-means++", {"max_no_improvement": 3}, "x-"),
(MiniBatchKMeans, "random", {
"max_no_improvement": 3, "init_size": 500}, "d-"),
]
for factory, init, params, format in cases:
print("Evaluation of %s with %s init" % (factory.__name__, init))
inertia = np.empty((len(n_init_range), n_runs))
for run_id in range(n_runs):
X, y = make_data(run_id, n_samples_per_center, grid_size, scale)
for i, n_init in enumerate(n_init_range):
km = factory(
n_clusters=n_clusters,
init=init,
random_state=run_id,
n_init=n_init,
**params,
).fit(X)
inertia[i, run_id] = km.inertia_
p = plt.errorbar(
n_init_range, inertia.mean(axis=1), inertia.std(axis=1), fmt=format
)
plots.append(p[0])
legends.append("%s with %s init" % (factory.__name__, init))
plt.xlabel("n_init")
plt.ylabel("inertia")
plt.legend(plots, legends)
plt.title("Mean inertia for various k-means init across %d runs" % n_runs)
# الجزء الثاني: الفحص البصري النوعي للتقارب
X, y = make_data(random_state, n_samples_per_center, grid_size, scale)
km = MiniBatchKMeans(
n_clusters=n_clusters, init="random", n_init=1, random_state=random_state
).fit(X)
plt.figure()
for k in range(n_clusters):
my_members = km.labels_ == k
color = cm.nipy_spectral(float(k) / n_clusters, 1)
plt.plot(X[my_members, 0], X[my_members, 1], ".", c=color)
cluster_center = km.cluster_centers_[k]
plt.plot(
cluster_center[0],
cluster_center[1],
"o",
markerfacecolor=color,
markeredgecolor="k",
markersize=6,
)
plt.title(
"Example cluster allocation with a single random init\nwith MiniBatchKMeans"
)
plt.show()
Total running time of the script: (0 minutes 1.633 seconds)
Related examples
مقارنة خوارزميات التجميع K-Means و MiniBatchKMeans
sphx_glr_auto_examples_cluster_plot_bisect_kmeans.py