ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز ميزات الإصدار 1.2 من scikit-learn#
يسعدنا الإعلان عن إصدار scikit-learn 1.2! تم إجراء العديد من الإصلاحات والتحسينات، بالإضافة إلى بعض الميزات الرئيسية الجديدة. نستعرض أدناه بعض الميزات الرئيسية لهذا الإصدار. للاطلاع على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
إخراج Pandas مع واجهة برمجة التطبيقات set_output#
تدعم محولات scikit-learn الآن إخراج Pandas مع واجهة برمجة التطبيقات set_output. لمزيد من المعلومات حول واجهة برمجة التطبيقات set_output، راجع المثال: تقديم واجهة برمجة التطبيقات set_output و # هذا الفيديو، إخراج DataFrame لـ Pandas لمحولات scikit-learn (بعض الأمثلة) <https://youtu.be/5bCg8VfX2x8>`__.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler, KBinsDiscretizer
from sklearn.compose import ColumnTransformer
X, y = load_iris(as_frame=True, return_X_y=True)
sepal_cols = ["sepal length (cm)", "sepal width (cm)"]
petal_cols = ["petal length (cm)", "petal width (cm)"]
preprocessor = ColumnTransformer(
[
("scaler", StandardScaler(), sepal_cols),
("kbin", KBinsDiscretizer(encode="ordinal"), petal_cols),
],
verbose_feature_names_out=False,
).set_output(transform="pandas")
X_out = preprocessor.fit_transform(X)
X_out.sample(n=5, random_state=0)
قيود التفاعل في أشجار التدرج التدريجي القائمة على التوزيع التكراري#
HistGradientBoostingRegressor و
HistGradientBoostingClassifier يدعمان الآن قيود التفاعل
مع معلمة interaction_cst. لمزيد من التفاصيل، راجع
دليل المستخدم. في المثال التالي، لا يُسمح للميزات بالتفاعل.
from sklearn.datasets import load_diabetes
from sklearn.ensemble import HistGradientBoostingRegressor
X, y = load_diabetes(return_X_y=True, as_frame=True)
hist_no_interact = HistGradientBoostingRegressor(
interaction_cst=[[i] for i in range(X.shape[1])], random_state=0
)
hist_no_interact.fit(X, y)
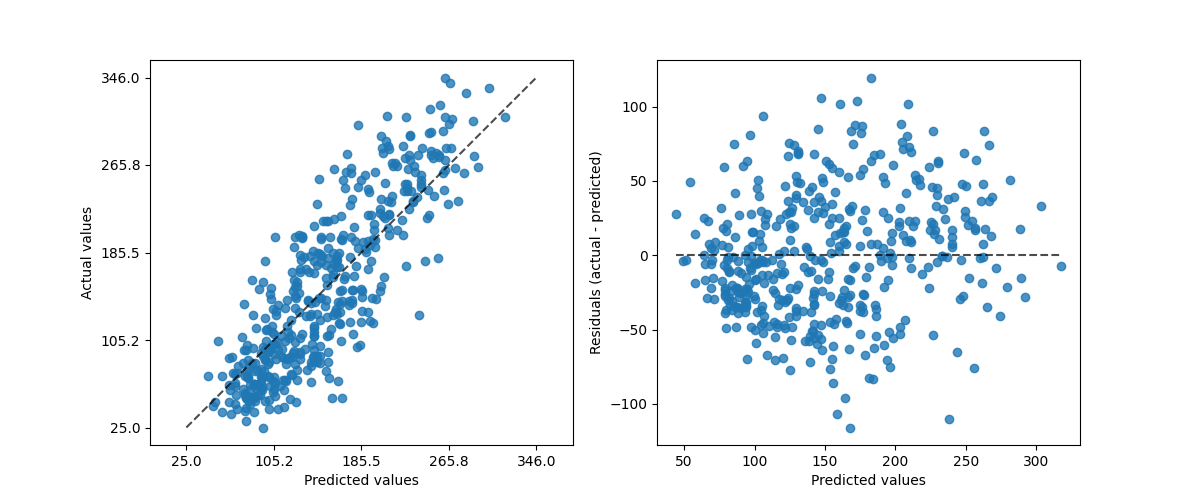
شاشات العرض الجديدة والمحسنة#
PredictionErrorDisplay توفر طريقة لتحليل نماذج الانحدار
بطريقة نوعية.
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 5))
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="actual_vs_predicted", ax=axs[0]
)
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="residual_vs_predicted", ax=axs[1]
)
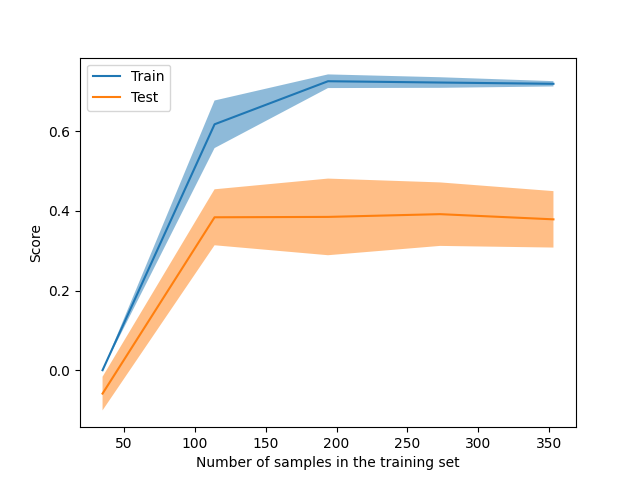
LearningCurveDisplay متاح الآن لعرض
النتائج من learning_curve.
from sklearn.model_selection import LearningCurveDisplay
_ = LearningCurveDisplay.from_estimator(
hist_no_interact, X, y, cv=5, n_jobs=2, train_sizes=np.linspace(0.1, 1, 5)
)
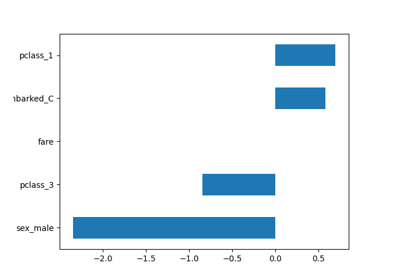
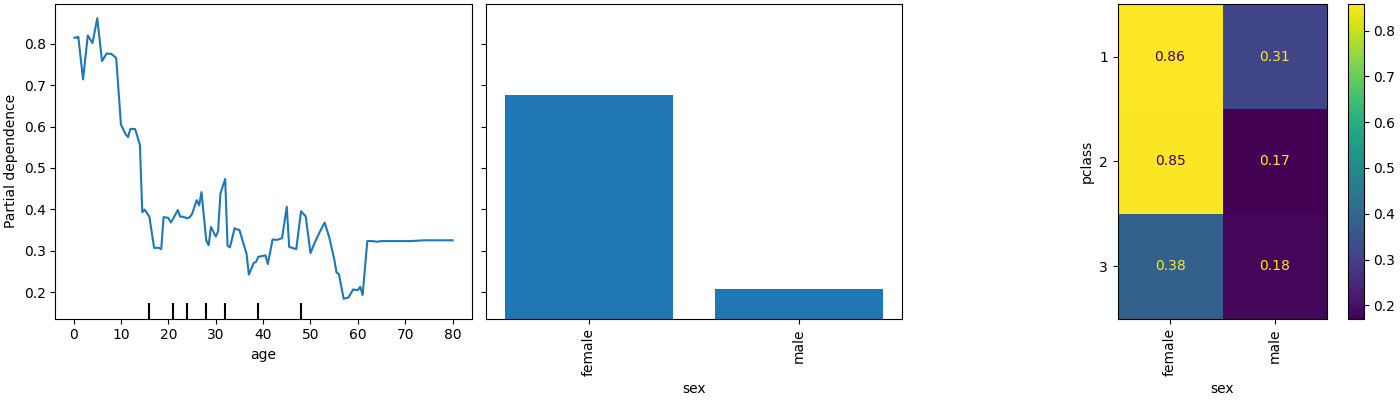
PartialDependenceDisplay تعرض معلمة جديدة
categorical_features لعرض الاعتماد الجزئي للميزات التصنيفية
باستخدام مخططات الأعمدة والخرائط الحرارية.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X = X.select_dtypes(["number", "category"]).drop(columns=["body"])
from sklearn.preprocessing import OrdinalEncoder
from sklearn.pipeline import make_pipeline
categorical_features = ["pclass", "sex", "embarked"]
model = make_pipeline(
ColumnTransformer(
transformers=[("cat", OrdinalEncoder(), categorical_features)],
remainder="passthrough",
),
HistGradientBoostingRegressor(random_state=0),
).fit(X, y)
from sklearn.inspection import PartialDependenceDisplay
fig, ax = plt.subplots(figsize=(14, 4), constrained_layout=True)
_ = PartialDependenceDisplay.from_estimator(
model,
X,
features=["age", "sex", ("pclass", "sex")],
categorical_features=categorical_features,
ax=ax,
)
معالج أسرع في fetch_openml#
fetch_openml يدعم الآن معالج جديد "pandas" وهو أكثر
كفاءة في الذاكرة والمعالجة. في الإصدار 1.4، سيتم تغيير المعالج الافتراضي إلى
parser="auto" والذي سيستخدم تلقائيًا معالج "pandas" للبيانات الكثيفة
و"liac-arff" للبيانات المتناثرة.
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X.head()
دعم تجريبي لواجهة برمجة التطبيقات Array في LinearDiscriminantAnalysis#
تمت إضافة دعم تجريبي لمواصفات Array API
إلى LinearDiscriminantAnalysis.
يمكن للمقدر الآن العمل على أي مكتبات متوافقة مع واجهة برمجة التطبيقات Array مثل
CuPy، وهي مكتبة صفائف معجلة بواسطة GPU. لمزيد من التفاصيل، راجع دليل المستخدم.
تحسين كفاءة العديد من المقدرات#
في الإصدار 1.1، تم تحسين كفاءة العديد من المقدرات التي تعتمد على حساب المسافات الزوجية (بشكل أساسي المقدرات المتعلقة بالتجمع، وتعلم المانيفولد، وخوارزميات البحث عن الجيران) بشكل كبير للمدخلات float64 الكثيفة. شملت تحسينات الكفاءة بشكل خاص تقليل استهلاك الذاكرة وتحسين قابلية التوسع على أجهزة متعددة النواة. في الإصدار 1.2، تم تحسين كفاءة هذه المقدرات بشكل أكبر لجميع مجموعات المدخلات الكثيفة والمبعثرة على مجموعات البيانات float32 وfloat64، باستثناء مجموعات البيانات المبعثرة-الكثيفة والكثيفة-المبعثرة لمقاييس المسافة Euclidean وSquared Euclidean. يمكن العثور على قائمة مفصلة بالمقدرات المتأثرة في سجل التغييرات.
Total running time of the script: (0 minutes 4.811 seconds)
Related examples