ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز ميزات الإصدار 1.0 من scikit-learn#
يسعدنا الإعلان عن إصدار scikit-learn 1.0! لقد كانت المكتبة مستقرة لفترة طويلة، وإصدار الإصدار 1.0 هو اعتراف بذلك وإشارة إلى مستخدمينا. لا يتضمن هذا الإصدار أي تغييرات جذرية باستثناء دورة الاستبعاد المعتادة على مدى إصدارين. بالنسبة للمستقبل، سنبذل قصارى جهدنا للحفاظ على هذا النمط.
يتضمن هذا الإصدار بعض الميزات الرئيسية الجديدة بالإضافة إلى العديد من التحسينات وإصلاح الأخطاء. نقدم أدناه بعض الميزات الرئيسية لهذا الإصدار. للاطلاع على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
الحجج الكلمة المفتاحية والحجج الموضعية#
تعرض واجهة برمجة التطبيقات (API) الخاصة بـ scikit-learn العديد من الوظائف والطرق التي لها العديد من معلمات الإدخال. على سبيل المثال، قبل هذا الإصدار، كان من الممكن إنشاء مثيل لـ HistGradientBoostingRegressor كما يلي:
HistGradientBoostingRegressor("squared_error", 0.1, 100, 31, None,
20, 0.0, 255, None, None, False, "auto", "loss", 0.1, 10, 1e-7,
0, None)
يتطلب فهم الكود أعلاه من القارئ الذهاب إلى وثائق واجهة برمجة التطبيقات والتحقق من كل معلمة لموضعها ومعناها. لتحسين قابلية قراءة الكود المكتوب بناءً على scikit-learn، يجب على المستخدمين الآن توفير معظم المعلمات بأسمائها، كحجج الكلمة المفتاحية، بدلاً من الحجج الموضعية. على سبيل المثال، سيكون الكود أعلاه:
HistGradientBoostingRegressor(
loss="squared_error",
learning_rate=0.1,
max_iter=100,
max_leaf_nodes=31,
max_depth=None,
min_samples_leaf=20,
l2_regularization=0.0,
max_bins=255,
categorical_features=None,
monotonic_cst=None,
warm_start=False,
early_stopping="auto",
scoring="loss",
validation_fraction=0.1,
n_iter_no_change=10,
tol=1e-7,
verbose=0,
random_state=None,
)
وهو أكثر قابلية للقراءة. تم إيقاف الحجج الموضعية منذ الإصدار 0.23، وسيؤدي الآن إلى إثارة خطأ من النوع TypeError. لا يزال عدد محدود من الحجج الموضعية مسموحًا به في بعض الحالات، على سبيل المثال في PCA، حيث PCA(10) لا يزال مسموحًا به، ولكن PCA(10,
False) غير مسموح به.
محولات المنحنيات#
إحدى الطرق لإضافة مصطلحات غير خطية إلى مجموعة ميزات مجموعة بيانات هي توليد
دوال أساس المنحنيات للسمات المستمرة/العددية باستخدام SplineTransformer الجديد. المنحنيات هي متعددات حدود قطعية،
يتم معلمتها بدرجة متعددة الحدود ومواضع العقد. ينفذ SplineTransformer أساس المنحنيات من النوع B.
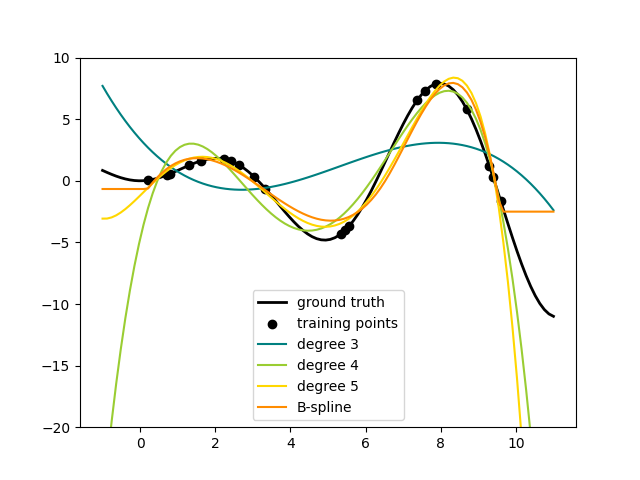
يوضح الكود التالي المنحنيات في العمل، للحصول على مزيد من المعلومات، يرجى الرجوع إلى دليل المستخدم.
import numpy as np
from sklearn.preprocessing import SplineTransformer
X = np.arange(5).reshape(5, 1)
spline = SplineTransformer(degree=2, n_knots=3)
spline.fit_transform(X)
array([[0.5 , 0.5 , 0. , 0. ],
[0.125, 0.75 , 0.125, 0. ],
[0. , 0.5 , 0.5 , 0. ],
[0. , 0.125, 0.75 , 0.125],
[0. , 0. , 0.5 , 0.5 ]])
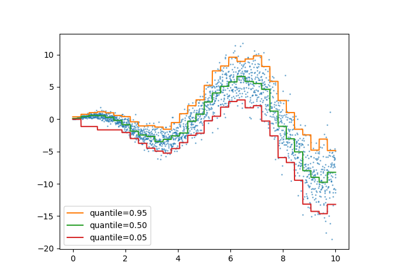
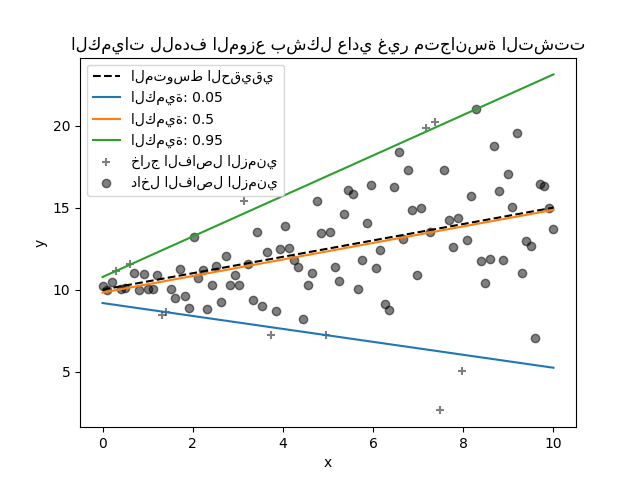
منظم الكمية#
تقدر عملية الانحدار الكمي الوسيط أو الكميات الأخرى لـ \(y\) المشروطة على \(X\)، بينما تقدر طريقة المربعات الصغرى العادية (OLS) المتوسط الشرطي.
كنموذج خطي، يعطي QuantileRegressor الجديد
تنبؤات خطية \(\hat{y}(w, X) = Xw\) للكمية \(q\)-th،
\(q \in (0, 1)\). يتم بعد ذلك العثور على الأوزان أو المعاملات \(w\) عن طريق
مشكلة التقليص التالية:
يتكون هذا من خسارة pinball (المعروفة أيضًا باسم الخسارة الخطية)،
راجع أيضًا mean_pinball_loss،
وعقوبة L1 التي يتحكم فيها المعامل "alpha"، مشابهة لـ
linear_model.Lasso.
يرجى التحقق من المثال التالي لمعرفة كيفية عمله، و دليل المستخدم للحصول على مزيد من التفاصيل.
دعم أسماء الميزات#
عندما يتم تمرير مصنف إلى إطار بيانات pandas' أثناء
fit، سيقوم المصنف بتعيين سمة feature_names_in_
تحتوي على أسماء الميزات. يرجى ملاحظة أن دعم أسماء الميزات ممكن فقط
عندما تكون أسماء الأعمدة في إطار البيانات جميعها من النوع سلسلة. يتم استخدام feature_names_in_
للتحقق من أن أسماء أعمدة إطار البيانات الممررة في
non-fit، مثل predict، متسقة مع الميزات في
fit:
from sklearn.preprocessing import StandardScaler
import pandas as pd
X = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=["a", "b", "c"])
scalar = StandardScaler().fit(X)
scalar.feature_names_in_
array(['a', 'b', 'c'], dtype=object)
يتوفر دعم get_feature_names_out للمحولات
التي كان لديها بالفعل get_feature_names والمحولات ذات المراسلات من واحد إلى واحد
بين الإدخال والإخراج مثل
StandardScaler. سيتم إضافة دعم get_feature_names_out
إلى جميع المحولات الأخرى في الإصدارات المستقبلية. بالإضافة إلى ذلك،
compose.ColumnTransformer.get_feature_names_out متاح
لدمج أسماء الميزات لمحولاته:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
X = pd.DataFrame({"pet": ["dog", "cat", "fish"], "age": [3, 7, 1]})
preprocessor = ColumnTransformer(
[
("numerical", StandardScaler(), ["age"]),
("categorical", OneHotEncoder(), ["pet"]),
],
verbose_feature_names_out=False,
).fit(X)
preprocessor.get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
عند استخدام هذا المحول preprocessor مع خط أنابيب، يتم الحصول على أسماء الميزات
التي يستخدمها المصنف عن طريق تقطيع واستدعاء
get_feature_names_out:
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
y = [1, 0, 1]
pipe = make_pipeline(preprocessor, LogisticRegression())
pipe.fit(X, y)
pipe[:-1].get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
واجهة برمجة تطبيقات رسم أكثر مرونة#
metrics.ConfusionMatrixDisplay،
metrics.PrecisionRecallDisplay، metrics.DetCurveDisplay،
و inspection.PartialDependenceDisplay تعرض الآن طريقتين للصف: from_estimator و from_predictions والتي تسمح للمستخدمين بإنشاء
رسم بياني معطى التنبؤات أو المصنف. وهذا يعني أن وظائف plot_* المقابلة تم إيقافها. يرجى التحقق من المثال الأول
<sphx_glr_auto_examples_model_selection_plot_confusion_matrix.py>` والمثال الثاني
<sphx_glr_auto_examples_classification_plot_digits_classification.py>` لمعرفة كيفية استخدام وظائف الرسم الجديدة.
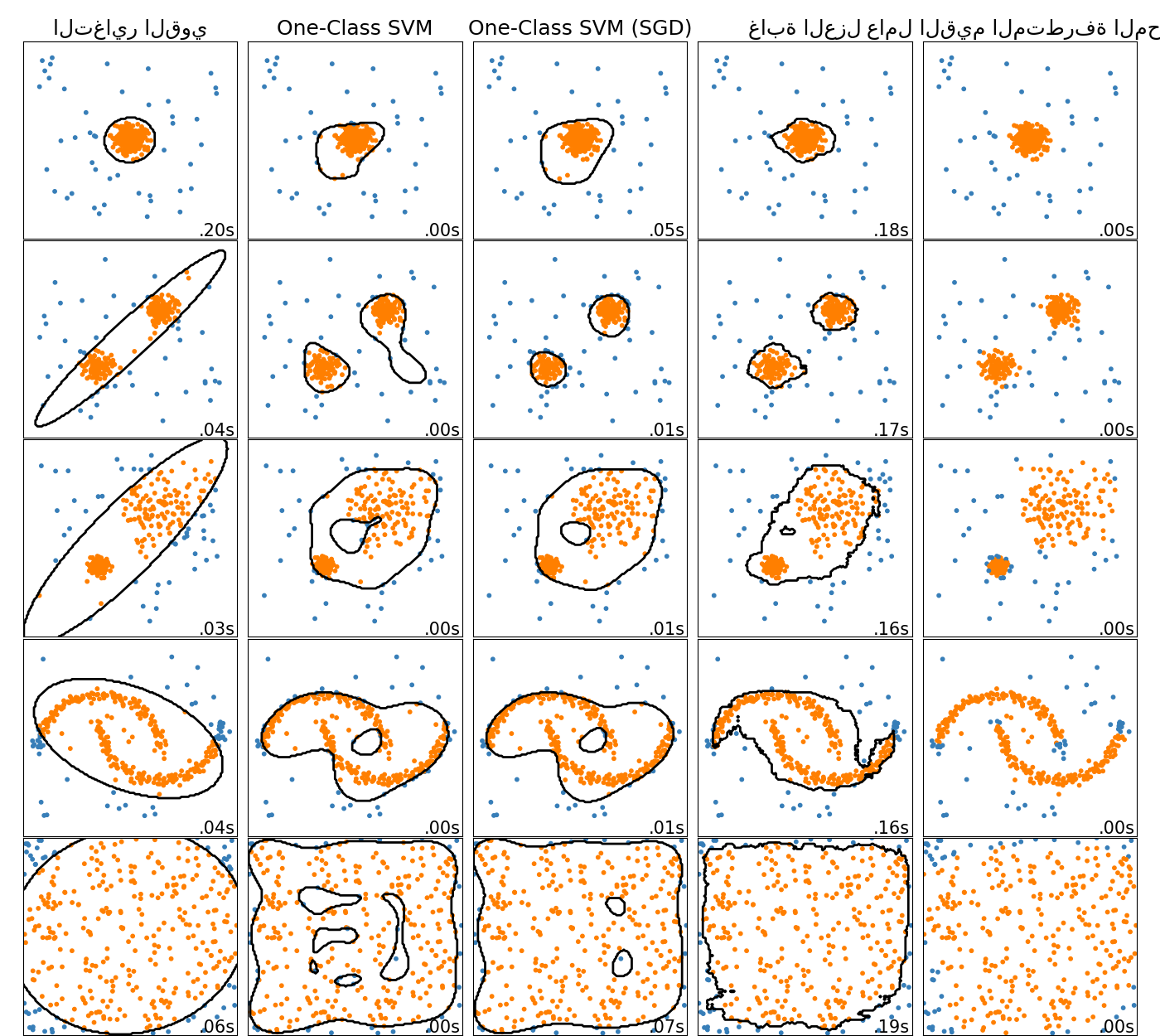
SVM من الفئة الواحدة عبر الإنترنت#
تنفذ الفئة الجديدة SGDOneClassSVM إصدارًا خطيًا عبر الإنترنت
من SVM من الفئة الواحدة باستخدام الانحدار التدريجي العشوائي.
عند دمجها مع تقنيات تقريب النواة،
يمكن استخدام SGDOneClassSVM لتقريب حل
SVM من الفئة الواحدة المطبق على النواة، المنفذ في OneClassSVM، مع
تعقيد وقت التجهيز الخطي في عدد العينات. يرجى ملاحظة أن
تعقيد SVM من الفئة الواحدة المطبق على النواة هو على الأكثر تربيعي في عدد
العينات. SGDOneClassSVM مناسب جيدًا
لمجموعات البيانات ذات عدد كبير من عينات التدريب (> 10,000) والتي يمكن أن يكون فيها متغير SGD أسرع بعدة رتب من حيث الحجم. يرجى التحقق من هذا
المثال
<sphx_glr_auto_examples_miscellaneous_plot_anomaly_comparison.py>` لمعرفة كيفية استخدامه، و دليل المستخدم للحصول على مزيد من التفاصيل.
نماذج التعزيز التدريجي القائمة على المنحنيات أصبحت مستقرة الآن#
HistGradientBoostingRegressor و
HistGradientBoostingClassifier لم تعد تجريبية
ويمكن استيرادها واستخدامها ببساطة كما يلي:
from sklearn.ensemble import HistGradientBoostingClassifier
تحسينات التوثيق الجديدة#
يتضمن هذا الإصدار العديد من التحسينات على التوثيق. من بين أكثر من 2100 طلبات السحب المدمجة، حوالي 800 منها هي تحسينات على توثيقنا.
Total running time of the script: (0 minutes 0.018 seconds)
Related examples