ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
إيقاف مبكر لنزول التدرج العشوائي#
نزول التدرج العشوائي هي تقنية تحسين تقلل من دالة الخسارة بطريقة عشوائية، حيث تقوم بخطوة نزول التدرج للعينة تلو الأخرى. وهي طريقة فعالة للغاية لملاءمة النماذج الخطية.
باعتبارها طريقة عشوائية، فإن دالة الخسارة لا تنخفض بالضرورة في كل تكرار، والتقارب مضمون فقط في المتوسط. لهذا السبب، قد يكون من الصعب مراقبة التقارب على دالة الخسارة.
هناك نهج آخر وهو مراقبة التقارب على درجة التحقق. في هذه الحالة، يتم تقسيم بيانات الإدخال إلى مجموعة تدريب ومجموعة تحقق. ثم يتم ملاءمة النموذج على مجموعة التدريب ومعيار التوقف يعتمد على درجة التنبؤ المحسوبة على مجموعة التحقق. هذا يمكننا من إيجاد أقل عدد من التكرارات الكافية لبناء نموذج يعمم جيداً على البيانات غير المرئية ويقلل من فرصة الإفراط في ملاءمة بيانات التدريب.
يتم تنشيط استراتيجية الإيقاف المبكر هذه إذا كان early_stopping=True؛ وإلا فإن معيار التوقف يستخدم فقط خسارة التدريب على كامل بيانات الإدخال. وللسيطرة بشكل أفضل على استراتيجية الإيقاف المبكر، يمكننا تحديد معامل validation_fraction الذي يحدد نسبة مجموعة البيانات التي نضعها جانباً لحساب درجة التحقق. سيستمر التحسين حتى لا تتحسن درجة التحقق على الأقل tol خلال آخر n_iter_no_change تكرارات. العدد الفعلي للتكرارات متاح في الخاصية n_iter_.
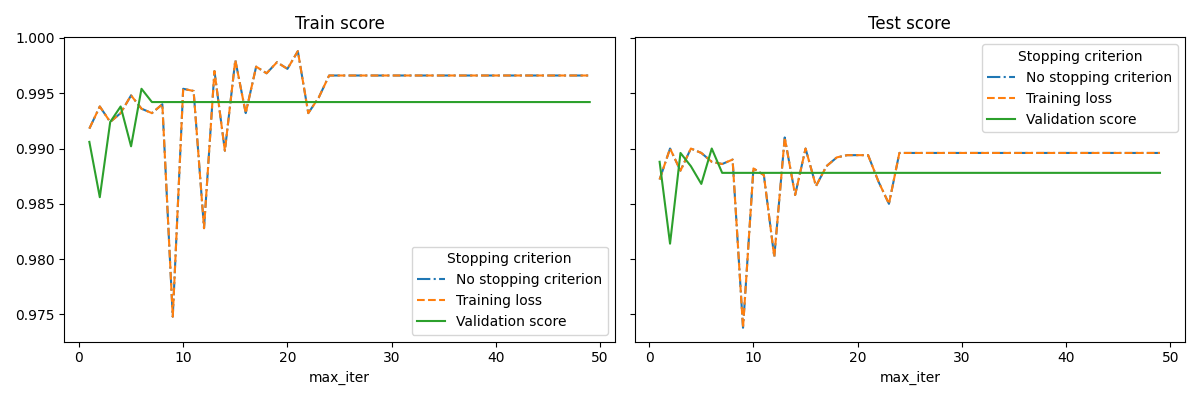
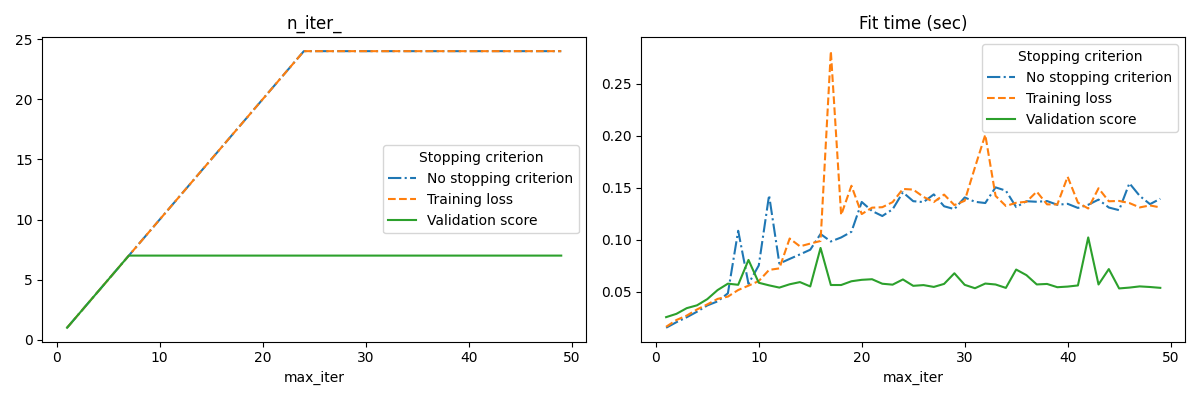
يوضح هذا المثال كيف يمكن استخدام الإيقاف المبكر في نموذج SGDClassifier لتحقيق دقة تقريباً نفس النموذج المبني بدون إيقاف مبكر. هذا يمكن أن يقلل بشكل كبير من وقت التدريب. لاحظ أن الدرجات تختلف بين معايير التوقف حتى من التكرارات المبكرة لأن بعض بيانات التدريب يتم استبعادها مع معيار التوقف على درجة التحقق.
No stopping criterion: .................................................
Training loss: .................................................
Validation score: .................................................
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
import sys
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import linear_model
from sklearn.datasets import fetch_openml
from sklearn.exceptions import ConvergenceWarning
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from sklearn.utils._testing import ignore_warnings
def load_mnist(n_samples=None, class_0="0", class_1="8"):
"""تحميل MNIST، اختيار فئتين، الخلط وإرجاع n_samples فقط."""
# تحميل البيانات من http://openml.org/d/554
mnist = fetch_openml("mnist_784", version=1, as_frame=False)
# أخذ فئتين فقط للتصنيف الثنائي
mask = np.logical_or(mnist.target == class_0, mnist.target == class_1)
X, y = shuffle(mnist.data[mask], mnist.target[mask], random_state=42)
if n_samples is not None:
X, y = X[:n_samples], y[:n_samples]
return X, y
@ignore_warnings(category=ConvergenceWarning)
def fit_and_score(estimator, max_iter, X_train, X_test, y_train, y_test):
"""ملاءمة المحلل على مجموعة التدريب وتقييمه على المجموعتين"""
estimator.set_params(max_iter=max_iter)
estimator.set_params(random_state=0)
start = time.time()
estimator.fit(X_train, y_train)
fit_time = time.time() - start
n_iter = estimator.n_iter_
train_score = estimator.score(X_train, y_train)
test_score = estimator.score(X_test, y_test)
return fit_time, n_iter, train_score, test_score
# تحديد المحللين للمقارنة
estimator_dict = {
"No stopping criterion": linear_model.SGDClassifier(n_iter_no_change=3),
"Training loss": linear_model.SGDClassifier(
early_stopping=False, n_iter_no_change=3, tol=0.1
),
"Validation score": linear_model.SGDClassifier(
early_stopping=True, n_iter_no_change=3, tol=0.0001, validation_fraction=0.2
),
}
# تحميل مجموعة البيانات
X, y = load_mnist(n_samples=10000)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
results = []
for estimator_name, estimator in estimator_dict.items():
print(estimator_name + ": ", end="")
for max_iter in range(1, 50):
print(".", end="")
sys.stdout.flush()
fit_time, n_iter, train_score, test_score = fit_and_score(
estimator, max_iter, X_train, X_test, y_train, y_test
)
results.append(
(estimator_name, max_iter, fit_time, n_iter, train_score, test_score)
)
print("")
# تحويل النتائج إلى جدول بيانات للرسم بسهولة
columns = [
"Stopping criterion",
"max_iter",
"Fit time (sec)",
"n_iter_",
"Train score",
"Test score",
]
results_df = pd.DataFrame(results, columns=columns)
# تحديد ما سيتم رسمه
lines = "Stopping criterion"
x_axis = "max_iter"
styles = ["-.", "--", "-"]
# الرسم الأول: درجات التدريب والاختبار
fig, axes = plt.subplots(nrows=1, ncols=2, sharey=True, figsize=(12, 4))
for ax, y_axis in zip(axes, ["Train score", "Test score"]):
for style, (criterion, group_df) in zip(styles, results_df.groupby(lines)):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax, style=style)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
# الرسم الثاني: n_iter و fit time
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 4))
for ax, y_axis in zip(axes, ["n_iter_", "Fit time (sec)"]):
for style, (criterion, group_df) in zip(styles, results_df.groupby(lines)):
group_df.plot(x=x_axis, y=y_axis, label=criterion, ax=ax, style=style)
ax.set_title(y_axis)
ax.legend(title=lines)
fig.tight_layout()
plt.show()
Total running time of the script: (0 minutes 27.930 seconds)
Related examples
نموذج لاصو: اختيار النموذج باستخدام معايير AIC-BIC والتحقق المتقاطع