ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
الاحتفاظ بأقرب الجيران في الذاكرة المؤقتة#
هذا المثال يوضح كيفية حساب أقرب الجيران مسبقًا قبل استخدامهم في KNeighborsClassifier. يمكن لـ KNeighborsClassifier حساب أقرب الجيران داخليًا، ولكن حسابهم مسبقًا يمكن أن يوفر عدة فوائد، مثل التحكم الدقيق في المعاملات، والاحتفاظ بالنتائج للاستخدامات المتعددة، أو التطبيقات المخصصة.
هنا نستخدم خاصية الاحتفاظ بالنتائج في الأنابيب لحفظ أقرب الجيران بين عمليات التهيئة المتعددة لـ KNeighborsClassifier. تكون المكالمة الأولى بطيئة لأنها تحسب مخطط الجيران، بينما تكون المكالمات اللاحقة أسرع لأنها لا تحتاج إلى إعادة حساب المخطط. هنا تكون المدة قصيرة لأن مجموعة البيانات صغيرة، ولكن يمكن أن يكون التحسن أكثر وضوحًا عندما تنمو مجموعة البيانات بشكل أكبر، أو عندما تكون شبكة المعاملات المراد البحث فيها كبيرة.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
from tempfile import TemporaryDirectory
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier, KNeighborsTransformer
from sklearn.pipeline import Pipeline
X, y = load_digits(return_X_y=True)
n_neighbors_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# يحسب المحول مخطط أقرب الجيران باستخدام أكبر عدد من الجيران
# الضروري في البحث الشبكي. يقوم نموذج التصنيف بتصفية
# مخطط أقرب الجيران كما يتطلب معامل n_neighbors الخاص به.
graph_model = KNeighborsTransformer(n_neighbors=max(n_neighbors_list), mode="distance")
classifier_model = KNeighborsClassifier(metric="precomputed")
# لاحظ أننا نعطي الذاكرة المؤقتة دليلًا لحفظ حساب المخطط
# الذي سيتم استخدامه عدة مرات عند ضبط معاملات نموذج التصنيف.
with TemporaryDirectory(prefix="sklearn_graph_cache_") as tmpdir:
full_model = Pipeline(
steps=[("graph", graph_model), ("classifier", classifier_model)], memory=tmpdir
)
param_grid = {"classifier__n_neighbors": n_neighbors_list}
grid_model = GridSearchCV(full_model, param_grid)
grid_model.fit(X, y)
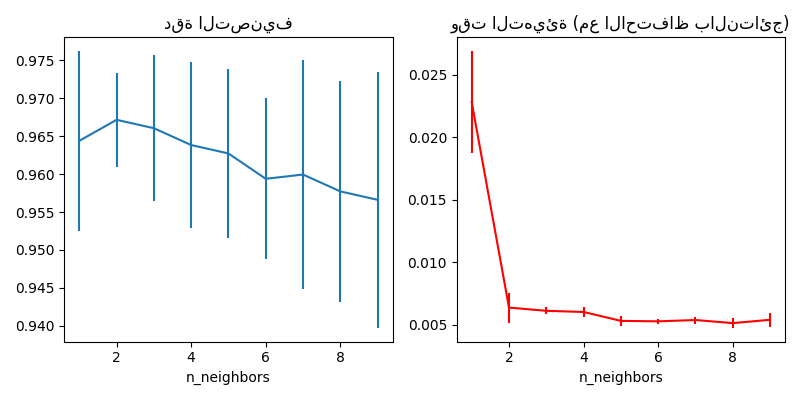
# رسم نتائج البحث الشبكي.
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
axes[0].errorbar(
x=n_neighbors_list,
y=grid_model.cv_results_["mean_test_score"],
yerr=grid_model.cv_results_["std_test_score"],
)
axes[0].set(xlabel="n_neighbors", title="دقة التصنيف")
axes[1].errorbar(
x=n_neighbors_list,
y=grid_model.cv_results_["mean_fit_time"],
yerr=grid_model.cv_results_["std_fit_time"],
color="r",
)
axes[1].set(xlabel="n_neighbors", title="وقت التهيئة (مع الاحتفاظ بالنتائج)")
fig.tight_layout()
plt.show()
Total running time of the script: (0 minutes 1.839 seconds)
Related examples

اختيار تقليل الأبعاد باستخدام Pipeline و GridSearchCV