ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
الترميز الداخلي للهدف عبر الملاءمة#
يستبدل TargetEncoder كل فئة من الميزات الفئوية بالمتوسط
المقلص للمتغير الهدف لتلك الفئة. هذه الطريقة مفيدة
في الحالات التي توجد فيها علاقة قوية بين الميزة الفئوية
والهدف. لمنع الإفراط في الملاءمة، يستخدم TargetEncoder.fit_transform
مخطط cross fitting داخلي لترميز بيانات التدريب لاستخدامها
بواسطة نموذج أسفل البئر. يتضمن هذا المخطط تقسيم البيانات إلى k folds
وترميز كل fold باستخدام الترميزات التي تم تعلمها باستخدام الـ k-1 folds الأخرى.
في هذا المثال، نوضح أهمية إجراء الملاءمة
عبر الوقاية من الإفراط في الملاءمة.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
إنشاء مجموعة بيانات صناعية#
لهذا المثال، نقوم ببناء مجموعة بيانات بثلاث ميزات فئوية:
ميزة إخبارية ذات ترتيب متوسط ("informative")
ميزة غير إخبارية ذات ترتيب متوسط ("shuffled")
ميزة غير إخبارية ذات ترتيب عالٍ ("near_unique")
أولاً، نقوم بتوليد الميزة الإخبارية:
import numpy as np
from sklearn.preprocessing import KBinsDiscretizer
n_samples = 50_000
rng = np.random.RandomState(42)
y = rng.randn(n_samples)
noise = 0.5 * rng.randn(n_samples)
n_categories = 100
kbins = KBinsDiscretizer(
n_bins=n_categories,
encode="ordinal",
strategy="uniform",
random_state=rng,
subsample=None,
)
X_informative = kbins.fit_transform((y + noise).reshape(-1, 1))
# إزالة العلاقة الخطية بين y وفهرس bin عن طريق تبديل قيم X_informative:
permuted_categories = rng.permutation(n_categories)
X_informative = permuted_categories[X_informative.astype(np.int32)]
يتم توليد الميزة غير الإخبارية ذات الترتيب المتوسط عن طريق تبديل الميزة الإخبارية وإزالة العلاقة مع الهدف:
X_shuffled = rng.permutation(X_informative)
يتم توليد الميزة غير الإخبارية ذات الترتيب العالي بحيث تكون
مستقلة عن المتغير الهدف. سنظهر أن الترميز المستهدف بدون
cross fitting سيسبب إفراطًا كارثيًا في الملاءمة للـ regressor. هذه الميزات ذات الترتيب العالي هي في الأساس محددات فريدة
للعينات التي يجب إزالتها بشكل عام من مجموعات بيانات التعلم الآلي.
في هذا المثال، نقوم بتوليدها لإظهار كيف أن سلوك TargetEncoder الافتراضي
cross fitting يخفف من مشكلة الإفراط في الملاءمة تلقائيًا.
X_near_unique_categories = rng.choice(
int(0.9 * n_samples), size=n_samples, replace=True
).reshape(-1, 1)
أخيرًا، نقوم بتجميع مجموعة البيانات وإجراء تقسيم تدريبي اختباري:
import pandas as pd
from sklearn.model_selection import train_test_split
X = pd.DataFrame(
np.concatenate(
[X_informative, X_shuffled, X_near_unique_categories],
axis=1,
),
columns=["informative", "shuffled", "near_unique"],
)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
تدريب ريدغ ريجريسور#
في هذا القسم، نقوم بتدريب ريدغ ريجريسور على مجموعة البيانات مع الترميز وبدونه واستكشاف تأثير الترميز المستهدف مع وعبر الملاءمة الداخلية. أولاً، نرى أن نموذج ريدغ المدرب على الميزات الخام سيكون له أداء منخفض. هذا لأننا قمنا بتبديل ترتيب الميزة الإخبارية مما يعني أن X_informative غير إخبارية عندما تكون خام:
import sklearn
from sklearn.linear_model import Ridge
# تكوين المحولات لإخراج DataFrames دائمًا
sklearn.set_config(transform_output="pandas")
ridge = Ridge(alpha=1e-6, solver="lsqr", fit_intercept=False)
raw_model = ridge.fit(X_train, y_train)
print("Raw Model score on training set: ", raw_model.score(X_train, y_train))
print("Raw Model score on test set: ", raw_model.score(X_test, y_test))
Raw Model score on training set: 0.0049896314219657345
Raw Model score on test set: 0.00457762158146513
بعد ذلك، نقوم بإنشاء خط أنابيب مع الترميز المستهدف ونموذج ريدغ. يستخدم خط الأنابيب
TargetEncoder.fit_transform الذي يستخدم cross fitting. نرى أن النموذج
يلائم البيانات جيدًا ويتعمم على مجموعة الاختبار:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import TargetEncoder
model_with_cf = make_pipeline(TargetEncoder(random_state=0), ridge)
model_with_cf.fit(X_train, y_train)
print("Model with CF on train set: ", model_with_cf.score(X_train, y_train))
print("Model with CF on test set: ", model_with_cf.score(X_test, y_test))
Model with CF on train set: 0.8000184677460302
Model with CF on test set: 0.7927845601690917
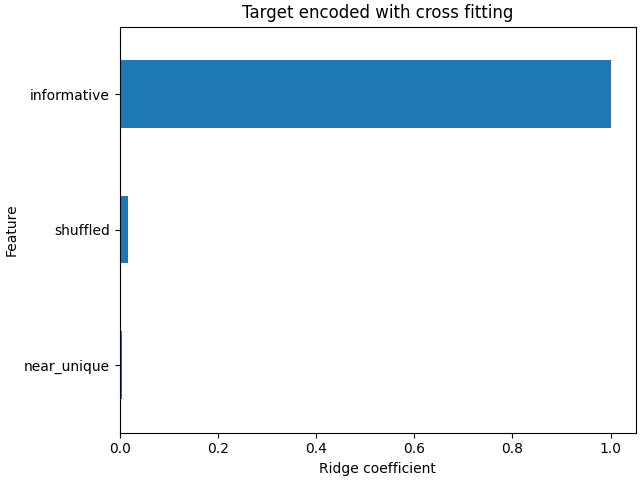
تُظهر معاملات النموذج الخطي أن معظم الوزن يقع على الميزة في فهرس العمود 0، والتي هي الميزة الإخبارية
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams["figure.constrained_layout.use"] = True
coefs_cf = pd.Series(
model_with_cf[-1].coef_, index=model_with_cf[-1].feature_names_in_
).sort_values()
ax = coefs_cf.plot(kind="barh")
_ = ax.set(
title="Target encoded with cross fitting",
xlabel="Ridge coefficient",
ylabel="Feature",
)
في حين أن TargetEncoder.fit_transform يستخدم مخطط
cross fitting داخلي لتعلم الترميزات لمجموعة التدريب،
TargetEncoder.transform نفسه لا يفعل ذلك.
يستخدم مجموعة التدريب الكاملة لتعلم الترميزات وتحويل الميزات الفئوية. وبالتالي، يمكننا استخدام TargetEncoder.fit متبوعًا
بـ TargetEncoder.transform لتعطيل cross fitting. يتم تمرير هذا
الترميز بعد ذلك إلى نموذج ريدغ.
target_encoder = TargetEncoder(random_state=0)
target_encoder.fit(X_train, y_train)
X_train_no_cf_encoding = target_encoder.transform(X_train)
X_test_no_cf_encoding = target_encoder.transform(X_test)
model_no_cf = ridge.fit(X_train_no_cf_encoding, y_train)
نقيم النموذج الذي لم يستخدم cross fitting عند الترميز ونرى أنه يفرط في الملاءمة:
print(
"Model without CF on training set: ",
model_no_cf.score(X_train_no_cf_encoding, y_train),
)
print(
"Model without CF on test set: ",
model_no_cf.score(
X_test_no_cf_encoding,
y_test,
),
)
Model without CF on training set: 0.858486250088675
Model without CF on test set: 0.6338211367102146
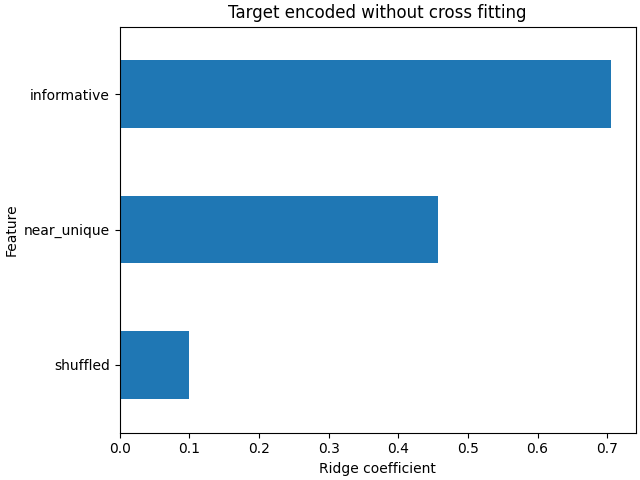
يفرط نموذج ريدغ في الملاءمة لأنه يعطي وزنًا أكبر بكثير للميزة غير الإخبارية ذات الترتيب العالي للغاية ("near_unique") والترتيب المتوسط ("shuffled") مقارنةً عندما استخدم النموذج cross fitting لترميز الميزات.
coefs_no_cf = pd.Series(
model_no_cf.coef_, index=model_no_cf.feature_names_in_
).sort_values()
ax = coefs_no_cf.plot(kind="barh")
_ = ax.set(
title="Target encoded without cross fitting",
xlabel="Ridge coefficient",
ylabel="Feature",
)
الخلاصة#
يوضح هذا المثال أهمية TargetEncoder's internal
cross fitting. من المهم استخدام
TargetEncoder.fit_transform لترميز بيانات التدريب قبل تمريرها
إلى نموذج التعلم الآلي. عندما يكون TargetEncoder جزءًا من
Pipeline ويتم ملاءمة خط الأنابيب، سيقوم خط الأنابيب
باستدعاء TargetEncoder.fit_transform واستخدام
cross fitting عند ترميز بيانات التدريب.
Total running time of the script: (0 minutes 0.348 seconds)
Related examples
مقارنة بين HuberRegressor و Ridge على مجموعة بيانات تحتوي على قيم شاذة قوية