ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
انحدار التعزيز المتدرج#
يوضح هذا المثال التعزيز المتدرج لإنتاج نموذج تنبؤي من مجموعة من النماذج التنبؤية الضعيفة. يمكن استخدام التعزيز المتدرج لمشاكل الانحدار والتصنيف. هنا، سوف نقوم بتدريب نموذج لمعالجة مهمة انحدار مرض السكري. سنحصل على النتائج من
GradientBoostingRegressor مع خسارة المربعات الصغرى و 500 شجرة انحدار بعمق 4.
ملاحظة: لمجموعات البيانات الأكبر (n_samples >= 10000)، يرجى الرجوع إلى
HistGradientBoostingRegressor. انظر
الميزات في أشجار التعزيز المتدرج للهيستوغرام للحصول على مثال يعرض بعض المزايا الأخرى لـ
HistGradientBoostingRegressor.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, ensemble
from sklearn.inspection import permutation_importance
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.utils.fixes import parse_version
تحميل البيانات#
أولاً، نحتاج إلى تحميل البيانات.
diabetes = datasets.load_diabetes()
X, y = diabetes.data, diabetes.target
تجهيز البيانات#
بعد ذلك، سنقوم بتقسيم مجموعة البيانات لدينا لاستخدام 90٪ للتدريب وترك الباقي للاختبار. سنقوم أيضًا بتعيين معلمات نموذج الانحدار. يمكنك اللعب بهذه المعلمات لمعرفة كيفية تغير النتائج.
n_estimators : عدد مراحل التعزيز التي سيتم إجراؤها.
لاحقًا، سنقوم برسم الانحراف مقابل تكرارات التعزيز.
max_depth : يحد من عدد العقد في الشجرة.
تعتمد أفضل قيمة على تفاعل متغيرات الإدخال.
min_samples_split : الحد الأدنى لعدد العينات المطلوبة لتقسيم
عقدة داخلية.
learning_rate : مقدار انكماش مساهمة كل شجرة.
loss : دالة الخسارة المراد تحسينها. يتم استخدام دالة المربعات الصغرى في
هذه الحالة، ومع ذلك، هناك العديد من الخيارات الأخرى (انظر
GradientBoostingRegressor ).
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=13
)
params = {
"n_estimators": 500,
"max_depth": 4,
"min_samples_split": 5,
"learning_rate": 0.01,
"loss": "squared_error",
}
ملاءمة نموذج الانحدار#
الآن سنبدأ منحنيات انحدار التعزيز المتدرج ونلائمها مع بيانات التدريب الخاصة بنا. دعونا نلقي نظرة أيضًا على متوسط مربع الخطأ في بيانات الاختبار.
reg = ensemble.GradientBoostingRegressor(**params)
reg.fit(X_train, y_train)
mse = mean_squared_error(y_test, reg.predict(X_test))
print("متوسط مربع الخطأ (MSE) في مجموعة الاختبار: {:.4f}".format(mse))
متوسط مربع الخطأ (MSE) في مجموعة الاختبار: 3014.8748
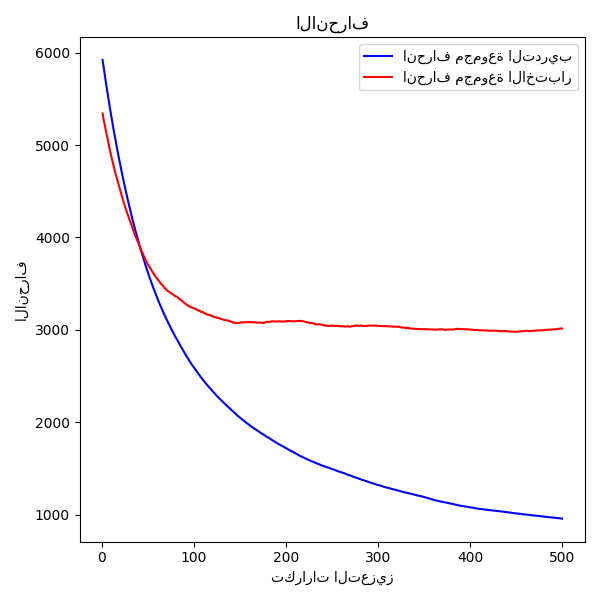
رسم انحراف التدريب#
أخيرًا، سنقوم بتصور النتائج. للقيام بذلك، سنقوم أولاً بحساب انحراف مجموعة الاختبار ثم رسمه مقابل تكرارات التعزيز.
test_score = np.zeros((params["n_estimators"],), dtype=np.float64)
for i, y_pred in enumerate(reg.staged_predict(X_test)):
test_score[i] = mean_squared_error(y_test, y_pred)
fig = plt.figure(figsize=(6, 6))
plt.subplot(1, 1, 1)
plt.title("الانحراف")
plt.plot(
np.arange(params["n_estimators"]) + 1,
reg.train_score_,
"b-",
label="انحراف مجموعة التدريب",
)
plt.plot(
np.arange(params["n_estimators"]) + 1, test_score, "r-", label="انحراف مجموعة الاختبار"
)
plt.legend(loc="upper right")
plt.xlabel("تكرارات التعزيز")
plt.ylabel("الانحراف")
fig.tight_layout()
plt.show()
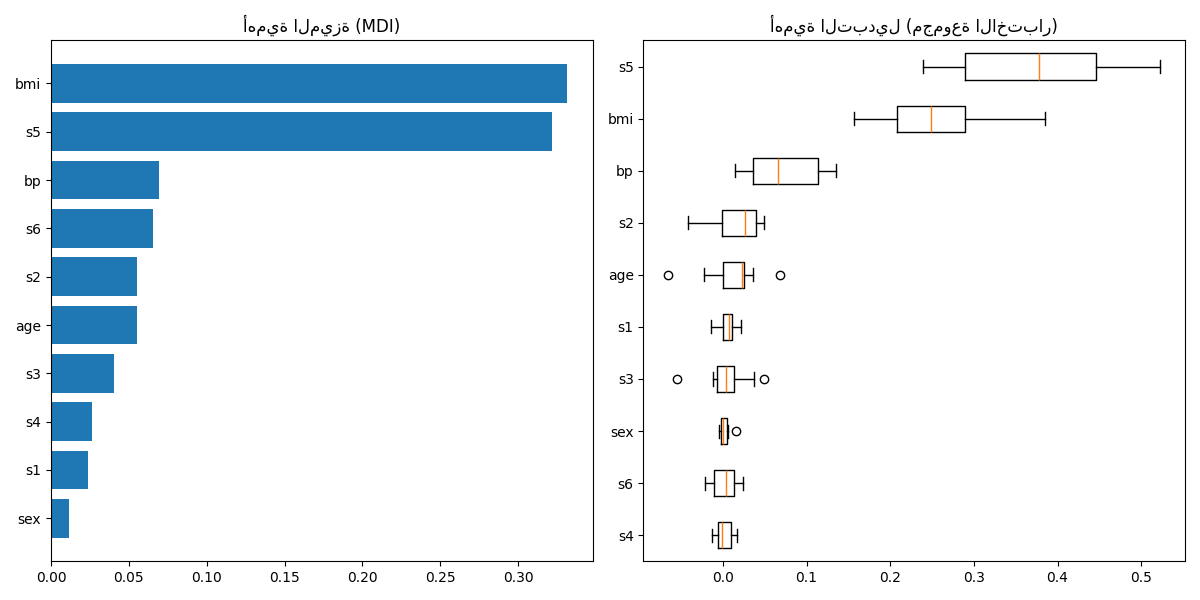
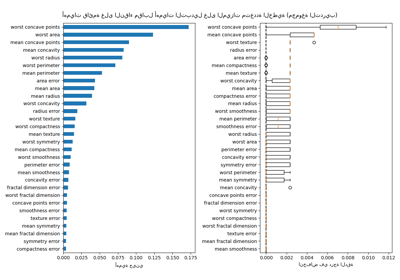
رسم أهمية الميزة#
تحذير
احذر، يمكن أن تكون أهمية الميزات المستندة إلى الشوائب مضللة للميزات ذات
الأهمية العالية (العديد من القيم الفريدة). كبديل،
يمكن حساب أهمية التبديل لـ reg في
مجموعة اختبار معلقة. انظر أهمية التبديل لمزيد من التفاصيل.
في هذا المثال، تحدد طرق الشوائب والتبديل نفس الميزتين التنبؤيتين القويتين ولكن ليس بنفس الترتيب. الميزة التنبؤية الثالثة، "bp"، هي أيضًا نفسها بالنسبة للطريقتين. الميزات المتبقية أقل تنبؤيةً وتُظهر أشرطة الخطأ في مخطط التبديل أنها تتداخل مع 0.
feature_importance = reg.feature_importances_
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
fig = plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.barh(pos, feature_importance[sorted_idx], align="center")
plt.yticks(pos, np.array(diabetes.feature_names)[sorted_idx])
plt.title("أهمية الميزة (MDI)")
result = permutation_importance(
reg, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_idx = result.importances_mean.argsort()
plt.subplot(1, 2, 2)
# تم إهمال وسيطة `labels` في boxplot في matplotlib 3.9 وتمت
# إعادة تسميتها إلى `tick_labels`. يتعامل الكود التالي مع هذا، ولكن بصفتك
# مستخدمًا لـ scikit-learn، فمن المحتمل أن تتمكن من كتابة كود أبسط باستخدام `labels=...`
# (matplotlib < 3.9) أو `tick_labels=...` (matplotlib >= 3.9).
tick_labels_parameter_name = (
"tick_labels"
if parse_version(matplotlib.__version__) >= parse_version("3.9")
else "labels"
)
tick_labels_dict = {
tick_labels_parameter_name: np.array(diabetes.feature_names)[sorted_idx]
}
plt.boxplot(result.importances[sorted_idx].T, vert=False, **tick_labels_dict)
plt.title("أهمية التبديل (مجموعة الاختبار)")
fig.tight_layout()
plt.show()
Total running time of the script: (0 minutes 1.928 seconds)
Related examples
أهمية التبديل مع الميزات متعددة الخطية أو المرتبطة
أهمية التبديل مقابل أهمية ميزة الغابة العشوائية (MDI)