ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
التصنيف متعدد التصنيفات باستخدام سلسلة المصنفات#
يوضح هذا المثال كيفية استخدام ClassifierChain لحل
مشكلة التصنيف متعدد التصنيفات.
تتمثل الاستراتيجية الأكثر بساطة لحل مثل هذه المهمة في تدريب مصنف ثنائي بشكل مستقل على كل تسمية (أي كل عمود من المتغير الهدف). في وقت التنبؤ، يتم استخدام مجموعة المصنفات الثنائية لتجميع تنبؤ متعدد المهام.
لا تسمح هذه الاستراتيجية بنمذجة العلاقة بين المهام المختلفة.
ClassifierChain هو المُقدر الميتا (أي مُقدر
يأخذ مُقدرًا داخليًا) الذي ينفذ استراتيجية أكثر تقدمًا. يتم استخدام مجموعة
المصنفات الثنائية كسلسلة حيث يتم استخدام تنبؤ مصنف في السلسلة كميزة لتدريب
المصنف التالي على تسمية جديدة. لذلك، تسمح هذه الميزات الإضافية لكل سلسلة
باستغلال الارتباطات بين التسميات.
يميل Jaccard similarity score للسلسلة إلى أن يكون أكبر من ذلك لمجموعة النماذج الأساسية المستقلة.
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
تحميل مجموعة بيانات#
لهذا المثال، نستخدم مجموعة بيانات الخميرة <https://www.openml.org/d/40597>`_ التي تحتوي على 2,417 نقطة بيانات، كل منها يحتوي على 103 ميزات و14 تسمية محتملة. تحتوي كل نقطة بيانات على تسمية واحدة على الأقل. كخط أساس، نقوم أولاً بتدريب مصنف الانحدار اللوجستي لكل من التسميات الـ 14. لتقييم أداء هذه المصنفات، نقوم بالتنبؤ بمجموعة اختبار محجوزة ونحسب تشابه جاكبارد لكل عينة.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
# تحميل مجموعة بيانات متعددة التسميات من https://www.openml.org/d/40597
X, Y = fetch_openml("yeast", version=4, return_X_y=True)
Y = Y == "TRUE"
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
ملاءمة النماذج#
نلائم LogisticRegression ملفوفة بواسطة
OneVsRestClassifier ومجموعة من
ClassifierChain.
LogisticRegression ملفوفة بواسطة OneVsRestClassifier#
نظرًا لأن LogisticRegression لا يمكنه
التعامل مع البيانات ذات الأهداف المتعددة بشكل افتراضي، نحتاج إلى استخدام
OneVsRestClassifier.
بعد ملاءمة النموذج، نحسب تشابه جاكبارد.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import jaccard_score
from sklearn.multiclass import OneVsRestClassifier
base_lr = LogisticRegression()
ovr = OneVsRestClassifier(base_lr)
ovr.fit(X_train, Y_train)
Y_pred_ovr = ovr.predict(X_test)
ovr_jaccard_score = jaccard_score(Y_test, Y_pred_ovr, average="samples")
سلسلة من المصنفات الثنائية#
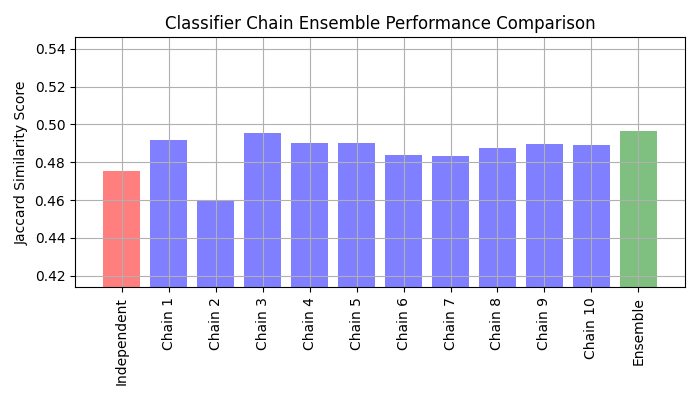
نظرًا لأن النماذج في كل سلسلة مرتبة عشوائيًا، هناك تباين كبير في الأداء بين السلاسل. يفترض أن هناك ترتيبًا أمثل لفئات السلسلة التي ستعطي أفضل أداء. ومع ذلك، لا نعرف هذا الترتيب مسبقًا. بدلاً من ذلك، يمكننا بناء مجموعة تصويت من سلاسل المصنفات عن طريق حساب متوسط التنبؤات الثنائية للسلاسل وتطبيق عتبة 0.5. تكون درجة تشابه جاكبارد للمجموعة أكبر من النماذج المستقلة وتميل إلى تجاوز درجة كل سلسلة في المجموعة (على الرغم من أن هذا غير مضمون مع السلاسل ذات الترتيب العشوائي).
from sklearn.multioutput import ClassifierChain
chains = [ClassifierChain(base_lr, order="random", random_state=i) for i in range(10)]
for chain in chains:
chain.fit(X_train, Y_train)
Y_pred_chains = np.array([chain.predict_proba(X_test) for chain in chains])
chain_jaccard_scores = [
jaccard_score(Y_test, Y_pred_chain >= 0.5, average="samples")
for Y_pred_chain in Y_pred_chains
]
Y_pred_ensemble = Y_pred_chains.mean(axis=0)
ensemble_jaccard_score = jaccard_score(
Y_test, Y_pred_ensemble >= 0.5, average="samples"
)
رسم النتائج#
رسم درجات تشابه جاكبارد للنموذج المستقل، وكل من السلاسل، والمجموعة (ملاحظة أن المحور الرأسي في هذا الرسم لا يبدأ من 0).
model_scores = [ovr_jaccard_score] + chain_jaccard_scores + [ensemble_jaccard_score]
model_names = (
"Independent",
"Chain 1",
"Chain 2",
"Chain 3",
"Chain 4",
"Chain 5",
"Chain 6",
"Chain 7",
"Chain 8",
"Chain 9",
"Chain 10",
"Ensemble",
)
x_pos = np.arange(len(model_names))
fig, ax = plt.subplots(figsize=(7, 4))
ax.grid(True)
ax.set_title("Classifier Chain Ensemble Performance Comparison")
ax.set_xticks(x_pos)
ax.set_xticklabels(model_names, rotation="vertical")
ax.set_ylabel("Jaccard Similarity Score")
ax.set_ylim([min(model_scores) * 0.9, max(model_scores) * 1.1])
colors = ["r"] + ["b"] * len(chain_jaccard_scores) + ["g"]
ax.bar(x_pos, model_scores, alpha=0.5, color=colors)
plt.tight_layout()
plt.show()
تفسير النتائج#
هناك ثلاث نتائج رئيسية من هذا الرسم:
النموذج المستقل الملفوف بواسطة
OneVsRestClassifierيؤدي بشكل أسوأ من مجموعة سلاسل المصنفات وبعض السلاسل الفردية. وهذا ناتج عن حقيقة أن الانحدار اللوجستي لا ينمذج العلاقة بين التسميات.ClassifierChainيستفيد من الارتباط بين التسميات ولكن بسبب الطبيعة العشوائية لترتيب التسميات، يمكن أن يؤدي إلى نتيجة أسوأ من النموذج المستقل.تؤدي مجموعة السلاسل أداءً أفضل لأنها لا تقوم فقط بالتقاط العلاقة بين التسميات ولكنها أيضًا لا تفترض افتراضات قوية حول ترتيبها الصحيح.
Total running time of the script: (0 minutes 2.618 seconds)
Related examples
نظرة عامة على الميتا-مقدّرات التدريب متعدد التصنيفات