ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تحويل الميزات باستخدام مجموعات الأشجار#
قم بتحويل ميزاتك إلى مساحة متفرقة ذات أبعاد أعلى. ثم قم بتدريب نموذج خطي على هذه الميزات.
قم بتدريب مجموعة من الأشجار (أشجار عشوائية تمامًا، أو غابة عشوائية، أو أشجار معززة بالتدرج) على مجموعة التدريب. بعد ذلك، يتم تعيين فهرس ميزة عشوائي ثابت لكل ورقة من كل شجرة في المجموعة في مساحة ميزات جديدة. يتم بعد ذلك ترميز هذه المؤشرات الورقية بطريقة "واحد مقابل الكل".
يمر كل عينة عبر قرارات كل شجرة في المجموعة وتنتهي في ورقة واحدة لكل شجرة. يتم ترميز العينة عن طريق تعيين قيم الميزات لهذه الأوراق إلى 1 وقيم الميزات الأخرى إلى 0.
بعد ذلك، يكون المحول الناتج قد تعلم تضمينًا فئويًا إشرافيًا، متفرقًا، عالي الأبعاد للبيانات.
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
أولاً، سنقوم بإنشاء مجموعة بيانات كبيرة وتقسيمها إلى ثلاث مجموعات:
مجموعة لتدريب طرق المجموعة والتي ستستخدم لاحقًا كمحول هندسة ميزات؛
مجموعة لتدريب النموذج الخطي؛
مجموعة لاختبار النموذج الخطي.
من المهم تقسيم البيانات بهذه الطريقة لتجنب الإفراط في الملاءمة عن طريق تسريب البيانات.
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingClassifier, RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=80_000, random_state=10)
X_full_train, X_test, y_full_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=10
)
X_train_ensemble, X_train_linear, y_train_ensemble, y_train_linear = train_test_split(
X_full_train, y_full_train, test_size=0.5, random_state=10
)
بالنسبة لكل من طرق المجموعة، سنستخدم 10 مقدرات وعمقًا أقصى يبلغ 3 مستويات.
n_estimators = 10
max_depth = 3
أولاً، سنبدأ بتدريب الغابة العشوائية والتعزيز التدرجي على مجموعة التدريب المنفصلة
random_forest = RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth, random_state=10
)
random_forest.fit(X_train_ensemble, y_train_ensemble)
gradient_boosting = GradientBoostingClassifier(
n_estimators=n_estimators, max_depth=max_depth, random_state=10
)
_ = gradient_boosting.fit(X_train_ensemble, y_train_ensemble)
لاحظ أن HistGradientBoostingClassifier أسرع بكثير من GradientBoostingClassifier بدءًا
من مجموعات البيانات المتوسطة (n_samples >= 10_000)، والتي لا تنطبق على
المثال الحالي.
RandomTreesEmbedding هي طريقة غير مشرفة
وبالتالي لا تحتاج إلى التدريب بشكل مستقل.
from sklearn.ensemble import RandomTreesEmbedding
random_tree_embedding = RandomTreesEmbedding(
n_estimators=n_estimators, max_depth=max_depth, random_state=0
)
الآن، سنقوم بإنشاء ثلاث خطوط أنابيب ستستخدم التضمين أعلاه كـ مرحلة ما قبل المعالجة.
يمكن أن يتم تضمين الأشجار العشوائية مباشرة مع الانحدار اللوجستي لأنه محول قياسي في scikit-learn.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
rt_model = make_pipeline(random_tree_embedding,
LogisticRegression(max_iter=1000))
rt_model.fit(X_train_linear, y_train_linear)
بعد ذلك، يمكننا أن ندمج الغابة العشوائية أو التعزيز التدرجي مع الانحدار اللوجستي. ومع ذلك، سيحدث تحويل الميزة عن طريق استدعاء
الطريقة apply. يتوقع خط الأنابيب في scikit-learn استدعاء لـ transform.
لذلك، قمنا بتغليف استدعاء apply داخل FunctionTransformer.
from sklearn.preprocessing import FunctionTransformer, OneHotEncoder
def rf_apply(X, model):
return model.apply(X)
rf_leaves_yielder = FunctionTransformer(
rf_apply, kw_args={"model": random_forest})
def rf_apply(X, model):
return model.apply(X)
rf_leaves_yielder = FunctionTransformer(
rf_apply, kw_args={"model": random_forest})
rf_model = make_pipeline(
rf_leaves_yielder,
OneHotEncoder(handle_unknown="ignore"),
LogisticRegression(max_iter=1000),
)
rf_model.fit(X_train_linear, y_train_linear)
def gbdt_apply(X, model):
return model.apply(X)[:, :, 0]
gbdt_leaves_yielder = FunctionTransformer(
gbdt_apply, kw_args={"model": gradient_boosting}
)
gbdt_model = make_pipeline(
gbdt_leaves_yielder,
OneHotEncoder(handle_unknown="ignore"),
LogisticRegression(max_iter=1000),
)
gbdt_model.fit(X_train_linear, y_train_linear)
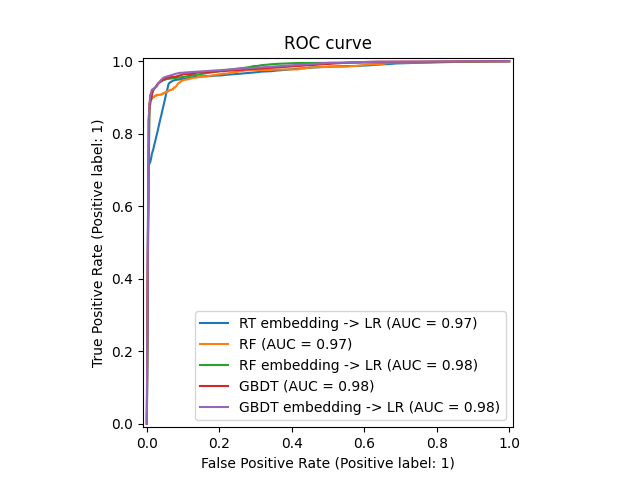
يمكننا أخيرًا عرض منحنيات ROC المختلفة لجميع النماذج.
from sklearn.metrics import RocCurveDisplay
_, ax = plt.subplots()
models = [
("RT embedding -> LR", rt_model),
("RF", random_forest),
("RF embedding -> LR", rf_model),
("GBDT", gradient_boosting),
("GBDT embedding -> LR", gbdt_model),
]
model_displays = {}
for name, pipeline in models:
model_displays[name] = RocCurveDisplay.from_estimator(
pipeline, X_test, y_test, ax=ax, name=name
)
_ = ax.set_title("ROC curve")
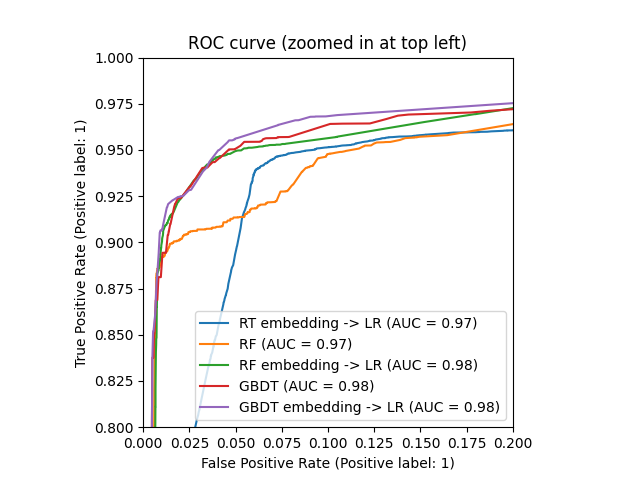
_, ax = plt.subplots()
for name, pipeline in models:
model_displays[name].plot(ax=ax)
ax.set_xlim(0, 0.2)
ax.set_ylim(0.8, 1)
_ = ax.set_title("ROC curve (zoomed in at top left)")
Total running time of the script: (0 minutes 2.852 seconds)
Related examples

رسم أسطح القرار لمجموعات الأشجار على مجموعة بيانات إيريس
مقارنة الغابات العشوائية ومقدر المخرجات المتعددة التلوي