ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
عرض توضيحي لخوارزمية التجميع الطيفي المشترك#
هذا المثال يوضح كيفية إنشاء مجموعة بيانات وتجميعها باستخدام خوارزمية التجميع الطيفي المشترك.
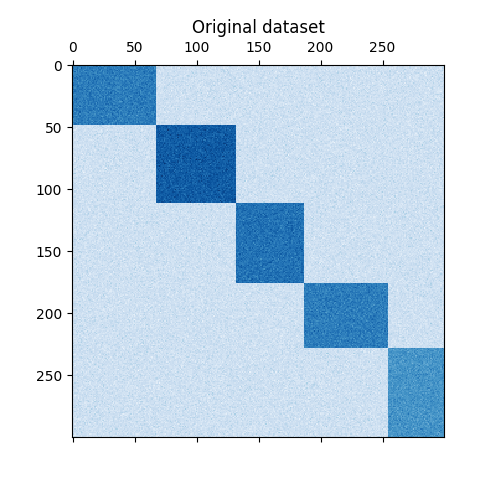
تم إنشاء مجموعة البيانات باستخدام الدالة make_biclusters، والتي
تنشئ مصفوفة من القيم الصغيرة وتزرع مجموعات التجميع الفرعية ذات القيم الكبيرة. يتم بعد ذلك خلط الصفوف والأعمدة وتمريرها إلى
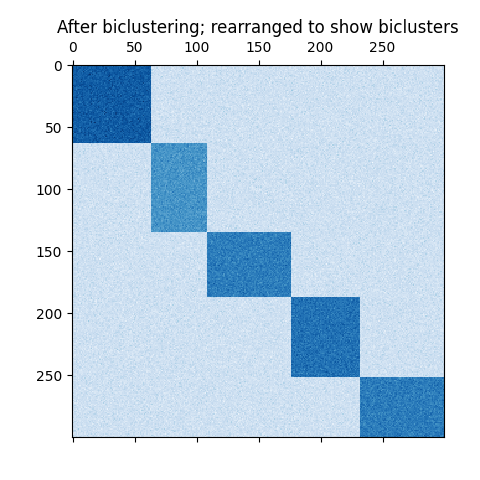
خوارزمية التجميع الطيفي المشترك. إعادة ترتيب المصفوفة المخلوطة لجعل مجموعات التجميع الفرعية متجاورة يُظهر مدى دقة الخوارزمية في العثور
على مجموعات التجميع الفرعية.

consensus score: 1.000
# المؤلفون: مطوري سكايلرن
# معرف الترخيص: BSD-3-Clause
import numpy as np
from matplotlib import pyplot as plt
from sklearn.cluster import SpectralCoclustering
from sklearn.datasets import make_biclusters
from sklearn.metrics import consensus_score
data, rows, columns = make_biclusters(
shape=(300, 300), n_clusters=5, noise=5, shuffle=False, random_state=0
)
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Original dataset")
# shuffle clusters
rng = np.random.RandomState(0)
row_idx = rng.permutation(data.shape[0])
col_idx = rng.permutation(data.shape[1])
data = data[row_idx][:, col_idx]
plt.matshow(data, cmap=plt.cm.Blues)
plt.title("Shuffled dataset")
model = SpectralCoclustering(n_clusters=5, random_state=0)
model.fit(data)
score = consensus_score(
model.biclusters_, (rows[:, row_idx], columns[:, col_idx]))
print("consensus score: {:.3f}".format(score))
fit_data = data[np.argsort(model.row_labels_)]
fit_data = fit_data[:, np.argsort(model.column_labels_)]
plt.matshow(fit_data, cmap=plt.cm.Blues)
plt.title("After biclustering; rearranged to show biclusters")
plt.show()
Total running time of the script: (0 minutes 0.435 seconds)
Related examples

التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك
التجميع الثنائي للمستندات باستخدام خوارزمية التجميع الطيفي المشترك

