ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
تحليلات مجموعة بيانات الوجوه#
يطبق هذا المثال على The Olivetti faces dataset طرقًا مختلفة لتحليل المصفوفة غير الخاضعة للإشراف (تقليل الأبعاد) من الوحدة
sklearn.decomposition (انظر فصل الوثائق
تحليل الإشارات إلى مكونات (مشاكل تحليل المصفوفات)).
المؤلفون: Vlad Niculae, Alexandre Gramfort
الترخيص: BSD 3 clause
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
إعداد مجموعة البيانات#
تحميل ومعالجة مجموعة بيانات وجوه Olivetti.
import logging
import matplotlib.pyplot as plt
from numpy.random import RandomState
from sklearn import cluster, decomposition
from sklearn.datasets import fetch_olivetti_faces
rng = RandomState(0)
# عرض سجلات التقدم على stdout
logging.basicConfig(level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s")
faces, _ = fetch_olivetti_faces(
return_X_y=True, shuffle=True, random_state=rng)
n_samples, n_features = faces.shape
# توسيط عام (التركيز على ميزة واحدة، توسيط جميع العينات)
faces_centered = faces - faces.mean(axis=0)
# توسيط محلي (التركيز على عينة واحدة، توسيط جميع الميزات)
faces_centered -= faces_centered.mean(axis=1).reshape(n_samples, -1)
print("تتكون مجموعة البيانات من %d وجه" % n_samples)
downloading Olivetti faces from https://ndownloader.figshare.com/files/5976027 to /root/scikit_learn_data
تتكون مجموعة البيانات من 400 وجه
تعريف دالة أساسية لرسم معرض الوجوه.
n_row, n_col = 2, 3
n_components = n_row * n_col
image_shape = (64, 64)
def plot_gallery(title, images, n_col=n_col, n_row=n_row, cmap=plt.cm.gray):
fig, axs = plt.subplots(
nrows=n_row,
ncols=n_col,
figsize=(2.0 * n_col, 2.3 * n_row),
facecolor="white",
constrained_layout=True,
)
fig.set_constrained_layout_pads(w_pad=0.01, h_pad=0.02, hspace=0, wspace=0)
fig.set_edgecolor("black")
fig.suptitle(title, size=16)
for ax, vec in zip(axs.flat, images):
vmax = max(vec.max(), -vec.min())
im = ax.imshow(
vec.reshape(image_shape),
cmap=cmap,
interpolation="nearest",
vmin=-vmax,
vmax=vmax,
)
ax.axis("off")
fig.colorbar(im, ax=axs, orientation="horizontal",
shrink=0.99, aspect=40, pad=0.01)
plt.show()
لنلقِ نظرة على بياناتنا. يشير اللون الرمادي إلى القيم السالبة، ويشير اللون الأبيض إلى القيم الموجبة.
plot_gallery("وجوه من مجموعة البيانات", faces_centered[:n_components])

التحليل#
تهيئة مقدرات مختلفة للتحليل وملاءمة كل منها على جميع الصور ورسم بعض النتائج. يستخرج كل مقدر 6 مكونات كمتجهات \(h \in \mathbb{R}^{4096}\). لقد عرضنا هذه المتجهات فقط في تصور سهل الاستخدام كصور 64 × 64 بكسل.
اقرأ المزيد في دليل المستخدم.
الوجوه الذاتية - PCA باستخدام SVD العشوائي#
تقليل الأبعاد الخطي باستخدام تحليل القيمة المفردة (SVD) للبيانات لإسقاطها إلى مساحة ذات أبعاد أقل.
ملاحظة
يوفر مقدر الوجوه الذاتية، عبر sklearn.decomposition.PCA،
أيضًا noise_variance_ عددي (متوسط التباين لكل بكسل)
الذي لا يمكن عرضه كصورة.
pca_estimator = decomposition.PCA(
n_components=n_components, svd_solver="randomized", whiten=True
)
pca_estimator.fit(faces_centered)
plot_gallery(
"الوجوه الذاتية - PCA باستخدام SVD العشوائي", pca_estimator.components_[
:n_components]
)

المكونات غير السالبة - NMF#
تقدير البيانات الأصلية غير السالبة كنتاج لمصفوفتين غير سالبتين.
nmf_estimator = decomposition.NMF(n_components=n_components, tol=5e-3)
nmf_estimator.fit(faces) # مجموعة البيانات الأصلية غير السالبة
plot_gallery("المكونات غير السالبة - NMF",
nmf_estimator.components_[:n_components])

المكونات المستقلة - FastICA#
يفصل تحليل المكونات المستقلة متجهات متعددة المتغيرات إلى مكونات فرعية مضافة مستقلة إلى أقصى حد.
ica_estimator = decomposition.FastICA(
n_components=n_components, max_iter=400, whiten="arbitrary-variance", tol=15e-5
)
ica_estimator.fit(faces_centered)
plot_gallery(
"المكونات المستقلة - FastICA", ica_estimator.components_[:n_components]
)

المكونات المتناثرة - MiniBatchSparsePCA#
يستخرج Mini-batch sparse PCA (MiniBatchSparsePCA)
مجموعة المكونات المتناثرة التي تعيد بناء البيانات بشكل أفضل. هذا المتغير
أسرع ولكنه أقل دقة من SparsePCA المماثل.
batch_pca_estimator = decomposition.MiniBatchSparsePCA(
n_components=n_components, alpha=0.1, max_iter=100, batch_size=3, random_state=rng
)
batch_pca_estimator.fit(faces_centered)
plot_gallery(
"المكونات المتناثرة - MiniBatchSparsePCA",
batch_pca_estimator.components_[:n_components],
)

تعلم القاموس#
افتراضيًا، يقوم MiniBatchDictionaryLearning
بتقسيم البيانات إلى مجموعات صغيرة ويحسنها بطريقة متصلة بالإنترنت
عن طريق التدوير على المجموعات الصغيرة لعدد التكرارات المحدد.
batch_dict_estimator = decomposition.MiniBatchDictionaryLearning(
n_components=n_components, alpha=0.1, max_iter=50, batch_size=3, random_state=rng
)
batch_dict_estimator.fit(faces_centered)
plot_gallery("تعلم القاموس", batch_dict_estimator.components_[:n_components])

مراكز التجميع - MiniBatchKMeans#
sklearn.cluster.MiniBatchKMeans فعال من الناحية الحسابية
وينفذ التعلم عبر الإنترنت باستخدام طريقة
partial_fit. لهذا السبب
قد يكون من المفيد تحسين بعض الخوارزميات التي تستغرق وقتًا طويلاً باستخدام
MiniBatchKMeans.
kmeans_estimator = cluster.MiniBatchKMeans(
n_clusters=n_components,
tol=1e-3,
batch_size=20,
max_iter=50,
random_state=rng,
)
kmeans_estimator.fit(faces_centered)
plot_gallery(
"مراكز التجميع - MiniBatchKMeans",
kmeans_estimator.cluster_centers_[:n_components],
)

مكونات تحليل العوامل - FA#
يشبه FactorAnalysis
PCA ولكنه يتميز بنمذجة
التباين في كل اتجاه لمساحة الإدخال بشكل مستقل (ضوضاء غير متجانسة). اقرأ المزيد في دليل المستخدم.
fa_estimator = decomposition.FactorAnalysis(
n_components=n_components, max_iter=20)
fa_estimator.fit(faces_centered)
plot_gallery("تحليل العوامل (FA)", fa_estimator.components_[:n_components])
# --- Pixelwise variance
plt.figure(figsize=(3.2, 3.6), facecolor="white", tight_layout=True)
vec = fa_estimator.noise_variance_
vmax = max(vec.max(), -vec.min())
plt.imshow(
vec.reshape(image_shape),
cmap=plt.cm.gray,
interpolation="nearest",
vmin=-vmax,
vmax=vmax,
)
plt.axis("off")
plt.title("التباين لكل بكسل من \n تحليل العوامل (FA)", size=16, wrap=True)
plt.colorbar(orientation="horizontal", shrink=0.8, pad=0.03)
plt.show()


التحليل: تعلم القاموس#
في القسم التالي، دعونا نفكر في تعلم القاموس بمزيد من الدقة. تعلم القاموس هو مشكلة ترقى إلى إيجاد تمثيل متناثر لبيانات الإدخال كمزيج من العناصر البسيطة. تشكل هذه العناصر البسيطة قاموسًا. من الممكن تقييد القاموس و/أو معاملات الترميز لتكون موجبة لتتناسب مع القيود التي قد تكون موجودة في البيانات.
ينفذ MiniBatchDictionaryLearning نسخة
أسرع، ولكن أقل دقة من خوارزمية تعلم القاموس
وهي أكثر ملاءمة لمجموعات البيانات الكبيرة. اقرأ المزيد في دليل المستخدم.
ارسم نفس العينات من مجموعة البيانات الخاصة بنا ولكن باستخدام خريطة ألوان أخرى. يشير اللون الأحمر إلى القيم السالبة، ويشير اللون الأزرق إلى القيم الموجبة، ويمثل اللون الأبيض الأصفار.
plot_gallery("وجوه من مجموعة البيانات",
faces_centered[:n_components], cmap=plt.cm.RdBu)

على غرار الأمثلة السابقة، نقوم بتغيير المعلمات وتدريب
مقدر MiniBatchDictionaryLearning على جميع
الصور. بشكل عام، يقوم تعلم القاموس والترميز المتناثر
بتحليل بيانات الإدخال إلى مصفوفات القاموس ومعاملات الترميز. \(X
\approx UV\)، حيث \(X = [x_1, . . . , x_n]\)، \(X \in
\mathbb{R}^{m×n}\)، قاموس \(U \in \mathbb{R}^{m×k}\)، معاملات الترميز
\(V \in \mathbb{R}^{k×n}\).
تظهر أدناه أيضًا النتائج عندما يكون القاموس ومعاملات الترميز مقيدة بشكل إيجابي.
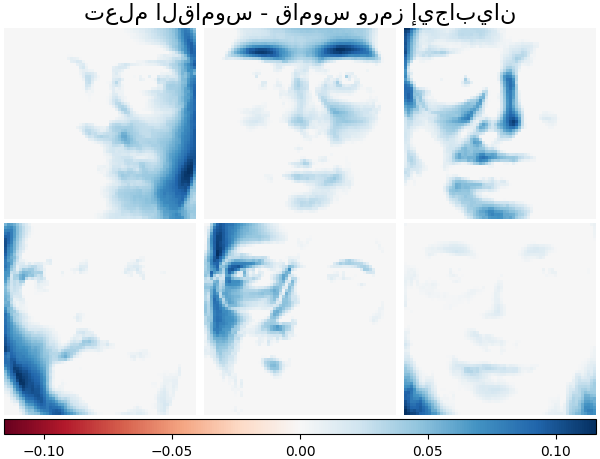
تعلم القاموس - قاموس إيجابي#
في القسم التالي، نفرض الإيجابية عند إيجاد القاموس.
dict_pos_dict_estimator = decomposition.MiniBatchDictionaryLearning(
n_components=n_components,
alpha=0.1,
max_iter=50,
batch_size=3,
random_state=rng,
positive_dict=True,
)
dict_pos_dict_estimator.fit(faces_centered)
plot_gallery(
"تعلم القاموس - قاموس إيجابي",
dict_pos_dict_estimator.components_[:n_components],
cmap=plt.cm.RdBu,
)

تعلم القاموس - رمز إيجابي#
أدناه نقيد معاملات الترميز كمصفوفة موجبة.
dict_pos_code_estimator = decomposition.MiniBatchDictionaryLearning(
n_components=n_components,
alpha=0.1,
max_iter=50,
batch_size=3,
fit_algorithm="cd",
random_state=rng,
positive_code=True,
)
dict_pos_code_estimator.fit(faces_centered)
plot_gallery(
"تعلم القاموس - رمز إيجابي",
dict_pos_code_estimator.components_[:n_components],
cmap=plt.cm.RdBu,
)

تعلم القاموس - قاموس ورمز إيجابيان#
تظهر أدناه أيضًا النتائج إذا كانت قيم القاموس ومعاملات الترميز مقيدة بشكل إيجابي.
dict_pos_estimator = decomposition.MiniBatchDictionaryLearning(
n_components=n_components,
alpha=0.1,
max_iter=50,
batch_size=3,
fit_algorithm="cd",
random_state=rng,
positive_dict=True,
positive_code=True,
)
dict_pos_estimator.fit(faces_centered)
plot_gallery(
"تعلم القاموس - قاموس ورمز إيجابيان",
dict_pos_estimator.components_[:n_components],
cmap=plt.cm.RdBu,
)
Total running time of the script: (0 minutes 12.434 seconds)
Related examples
اختيار النموذج باستخدام التحليل الرئيسي للمكونات الاحتمالي وتحليل العوامل (FA)

مثال على التعرف على الوجوه باستخدام الوجوه المميزة وآلات المتجهات الداعمة
sphx_glr_auto_examples_decomposition_plot_incremental_pca.py