ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز الميزات الجديدة في إصدار scikit-learn 1.1#
يسعدنا الإعلان عن إصدار scikit-learn 1.1! تم إصلاح العديد من الأخطاء وإجراء العديد من التحسينات، بالإضافة إلى بعض الميزات الرئيسية الجديدة. نستعرض أدناه بعض الميزات الرئيسية لهذا الإصدار. للاطلاع على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى release notes.
لتثبيت أحدث إصدار (باستخدام pip):
pip install --upgrade scikit-learn
أو باستخدام conda:
conda install -c conda-forge scikit-learn
خسارة الكمية في HistGradientBoostingRegressor#
HistGradientBoostingRegressor يمكنه نمذجة الكميات مع
loss="quantile" ومعامل quantile الجديد.
from sklearn.ensemble import HistGradientBoostingRegressor
import numpy as np
import matplotlib.pyplot as plt
# دالة انحدار بسيطة لـ X * cos(X)
rng = np.random.RandomState(42)
X_1d = np.linspace(0, 10, num=2000)
X = X_1d.reshape(-1, 1)
y = X_1d * np.cos(X_1d) + rng.normal(scale=X_1d / 3)
quantiles = [0.95, 0.5, 0.05]
parameters = dict(loss="quantile", max_bins=32, max_iter=50)
hist_quantiles = {
f"quantile={quantile:.2f}": HistGradientBoostingRegressor(
**parameters, quantile=quantile
).fit(X, y)
for quantile in quantiles
}
fig, ax = plt.subplots()
ax.plot(X_1d, y, "o", alpha=0.5, markersize=1)
for quantile, hist in hist_quantiles.items():
ax.plot(X_1d, hist.predict(X), label=quantile)
_ = ax.legend(loc="lower left")
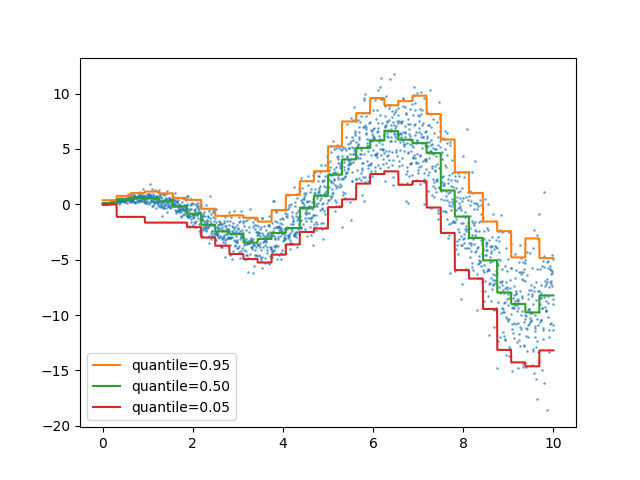
لمثال على الاستخدام، راجع الميزات في أشجار التعزيز المتدرج للهيستوغرام
get_feature_names_out متاحة في جميع المحولات#
get_feature_names_out متاحة الآن في جميع المحولات. هذا يمكّن
Pipeline من إنشاء أسماء الميزات الناتجة عن أنابيب أكثر تعقيدًا:
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.impute import SimpleImputer
from sklearn.feature_selection import SelectKBest
from sklearn.datasets import fetch_openml
from sklearn.linear_model import LogisticRegression
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
numeric_features = ["age", "fare"]
numeric_transformer = make_pipeline(SimpleImputer(strategy="median"), StandardScaler())
categorical_features = ["embarked", "pclass"]
preprocessor = ColumnTransformer(
[
("num", numeric_transformer, numeric_features),
(
"cat",
OneHotEncoder(handle_unknown="ignore", sparse_output=False),
categorical_features,
),
],
verbose_feature_names_out=False,
)
log_reg = make_pipeline(preprocessor, SelectKBest(k=7), LogisticRegression())
log_reg.fit(X, y)
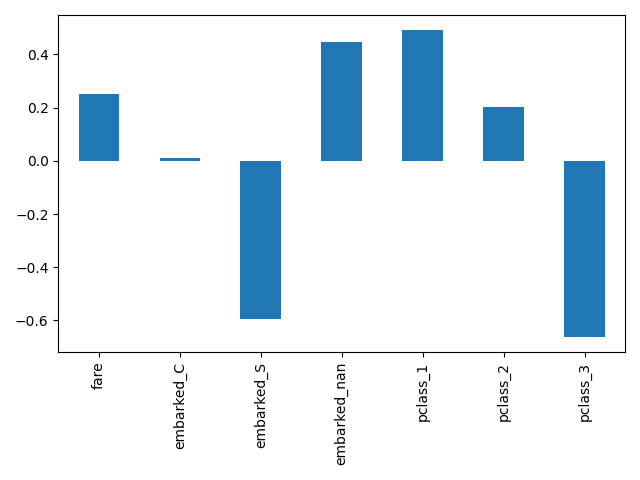
هنا نقوم بتقسيم الأنابيب لإدراج جميع الخطوات باستثناء الأخيرة. أسماء الميزات الناتجة عن هذا الجزء من الأنابيب هي الميزات التي يتم إدخالها في الانحدار اللوجستي. هذه الأسماء تقابل مباشرة المعاملات في الانحدار اللوجستي:
import pandas as pd
log_reg_input_features = log_reg[:-1].get_feature_names_out()
pd.Series(log_reg[-1].coef_.ravel(), index=log_reg_input_features).plot.bar()
plt.tight_layout()
تجميع الفئات غير المتكررة في OneHotEncoder#
OneHotEncoder يدعم تجميع الفئات غير المتكررة في ناتج
واحد لكل ميزة. المعاملات لتمكين تجميع الفئات غير المتكررة هي min_frequency
و max_categories. راجع User Guide
لمزيد من التفاصيل.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
X = np.array(
[["dog"] * 5 + ["cat"] * 20 + ["rabbit"] * 10 + ["snake"] * 3], dtype=object
).T
enc = OneHotEncoder(min_frequency=6, sparse_output=False).fit(X)
enc.infrequent_categories_
[array(['dog', 'snake'], dtype=object)]
نظرًا لأن الكلب والأفعى فئات غير متكررة، يتم تجميعها معًا عند التحويل:
encoded = enc.transform(np.array([["dog"], ["snake"], ["cat"], ["rabbit"]]))
pd.DataFrame(encoded, columns=enc.get_feature_names_out())
تحسينات الأداء#
تم إعادة هيكلة الحسابات على المسافات الزوجية للمجموعات الكثيفة من النوع
float64 للاستفادة بشكل أفضل من تعددية الخيوط غير الحاجبة. على سبيل
المثال، يمكن أن يكون neighbors.NearestNeighbors.kneighbors و
neighbors.NearestNeighbors.radius_neighbors أسرع بمقدار 20 و 5
مرة على التوالي من السابق. وباختصار، فإن الدوال والمقدرات التالية تستفيد
الآن من تحسينات الأداء:
لمعرفة المزيد عن التفاصيل التقنية لهذا العمل، يمكنك قراءة هذه السلسلة من المقالات.
علاوة على ذلك، تم إعادة هيكلة حسابات دالات الخسارة باستخدام Cython، مما أدى إلى تحسينات في الأداء للمقدرات التالية:
MiniBatchNMF: نسخة عبر الإنترنت من NMF#
الفئة الجديدة MiniBatchNMF تنفذ نسخة أسرع ولكنها
أقل دقة من التحليل المصفوفي غير السلبي
(NMF). MiniBatchNMF تقسم
البيانات إلى مجموعات صغيرة وتُحسّن نموذج NMF بطريقة عبر الإنترنت عن طريق
الدوران عبر المجموعات الصغيرة، مما يجعلها أكثر ملاءمة للمجموعات الكبيرة.
على وجه الخصوص، تنفذ partial_fit، والتي يمكن استخدامها للتعلم عبر
الإنترنت عندما لا تكون البيانات متاحة بسهولة من البداية، أو عندما لا
تتناسب البيانات مع الذاكرة.
import numpy as np
from sklearn.decomposition import MiniBatchNMF
rng = np.random.RandomState(0)
n_samples, n_features, n_components = 10, 10, 5
true_W = rng.uniform(size=(n_samples, n_components))
true_H = rng.uniform(size=(n_components, n_features))
X = true_W @ true_H
nmf = MiniBatchNMF(n_components=n_components, random_state=0)
for _ in range(10):
nmf.partial_fit(X)
W = nmf.transform(X)
H = nmf.components_
X_reconstructed = W @ H
print(
f"relative reconstruction error: ",
f"{np.sum((X - X_reconstructed) ** 2) / np.sum(X**2):.5f}",
)
relative reconstruction error: 0.00364
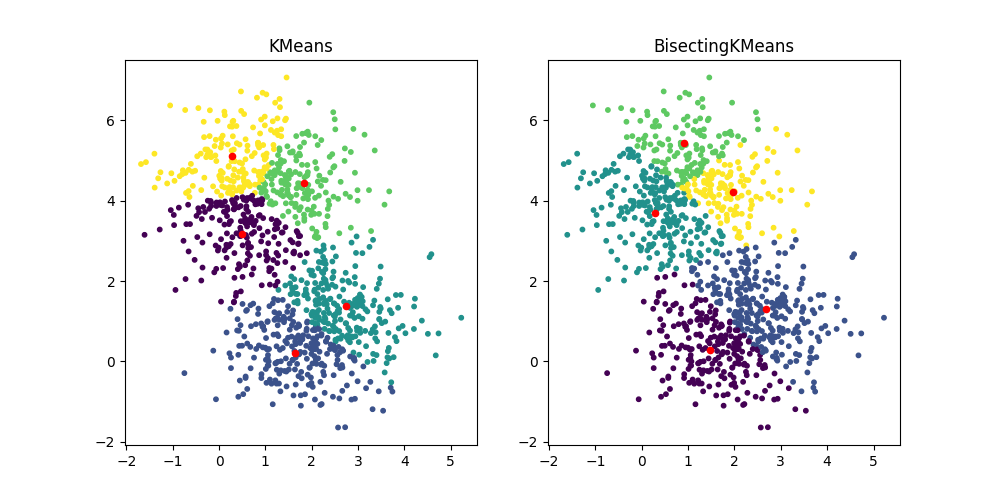
BisectingKMeans: التقسيم والتجميع#
الفئة الجديدة BisectingKMeans هي نسخة من
KMeans، تستخدم التجميع الهرمي التقسيمي. بدلاً من
إنشاء جميع المراكز في وقت واحد، يتم اختيار المراكز تدريجياً بناءً على
التجميع السابق: يتم تقسيم التجميع إلى تجميعين جديدين بشكل متكرر حتى
يتم الوصول إلى عدد التجميعات المستهدف، مما يعطي هيكلًا هرميًا
للتجميع.
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans, BisectingKMeans
import matplotlib.pyplot as plt
X, _ = make_blobs(n_samples=1000, centers=2, random_state=0)
km = KMeans(n_clusters=5, random_state=0, n_init="auto").fit(X)
bisect_km = BisectingKMeans(n_clusters=5, random_state=0).fit(X)
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].scatter(X[:, 0], X[:, 1], s=10, c=km.labels_)
ax[0].scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1], s=20, c="r")
ax[0].set_title("KMeans")
ax[1].scatter(X[:, 0], X[:, 1], s=10, c=bisect_km.labels_)
ax[1].scatter(
bisect_km.cluster_centers_[:, 0], bisect_km.cluster_centers_[:, 1], s=20, c="r"
)
_ = ax[1].set_title("BisectingKMeans")
Total running time of the script: (0 minutes 1.370 seconds)
Related examples

sphx_glr_auto_examples_applications_plot_topics_extraction_with_nmf_lda.py