ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
التصنيف الاستقرائي#
يمكن أن تكون عملية التصنيف مكلفة، خاصة عندما تحتوي مجموعتنا البياناتية على ملايين النقاط البياناتية. العديد من خوارزميات التصنيف ليست استقرائية، وبالتالي لا يمكن تطبيقها مباشرة على عينات بيانات جديدة دون إعادة حساب التصنيف، والذي قد يكون غير قابل للحساب. بدلاً من ذلك، يمكننا استخدام التصنيف لتعلم نموذج استقرائي باستخدام مصنف، والذي له عدة فوائد:
يسمح للتصنيفات بالتوسع والتطبيق على بيانات جديدة
على عكس إعادة ملاءمة التصنيفات لعينات جديدة، فإنه يضمن اتساق إجراء التصنيف بمرور الوقت
يسمح لنا باستخدام القدرات الاستدلالية للمصنف لوصف أو شرح التصنيفات
يوضح هذا المثال تنفيذًا عامًا لمصنف ميتا والذي يوسع التصنيف من خلال استنتاج مصنف من تسميات التصنيف.
# المؤلفون: مطوري سكايت-ليرن
# معرف الترخيص: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.base import BaseEstimator, clone
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.utils.metaestimators import available_if
from sklearn.utils.validation import check_is_fitted
N_SAMPLES = 5000
RANDOM_STATE = 42
def _classifier_has(attr):
"""تحقق إذا كان يمكننا تفويض طريقة إلى المصنف الأساسي.
أولاً، نتحقق من المصنف الملائم الأول إذا كان متاحًا، وإلا فإننا
نتحقق من المصنف غير الملائم.
"""
return lambda estimator: (
hasattr(estimator.classifier_, attr)
if hasattr(estimator, "classifier_")
else hasattr(estimator.classifier, attr)
)
class InductiveClusterer(BaseEstimator):
def __init__(self, clusterer, classifier):
self.clusterer = clusterer
self.classifier = classifier
def fit(self, X, y=None):
self.clusterer_ = clone(self.clusterer)
self.classifier_ = clone(self.classifier)
y = self.clusterer_.fit_predict(X)
self.classifier_.fit(X, y)
return self
@available_if(_classifier_has("predict"))
def predict(self, X):
check_is_fitted(self)
return self.classifier_.predict(X)
@available_if(_classifier_has("decision_function"))
def decision_function(self, X):
check_is_fitted(self)
return self.classifier_.decision_function(X)
def plot_scatter(X, color, alpha=0.5):
return plt.scatter(X[:, 0], X[:, 1], c=color, alpha=alpha, edgecolor="k")
# توليد بعض بيانات التدريب من التصنيف
X, y = make_blobs(
n_samples=N_SAMPLES,
cluster_std=[1.0, 1.0, 0.5],
centers=[(-5, -5), (0, 0), (5, 5)],
random_state=RANDOM_STATE,
)
# تدريب خوارزمية التصنيف على بيانات التدريب والحصول على تسميات التصنيف
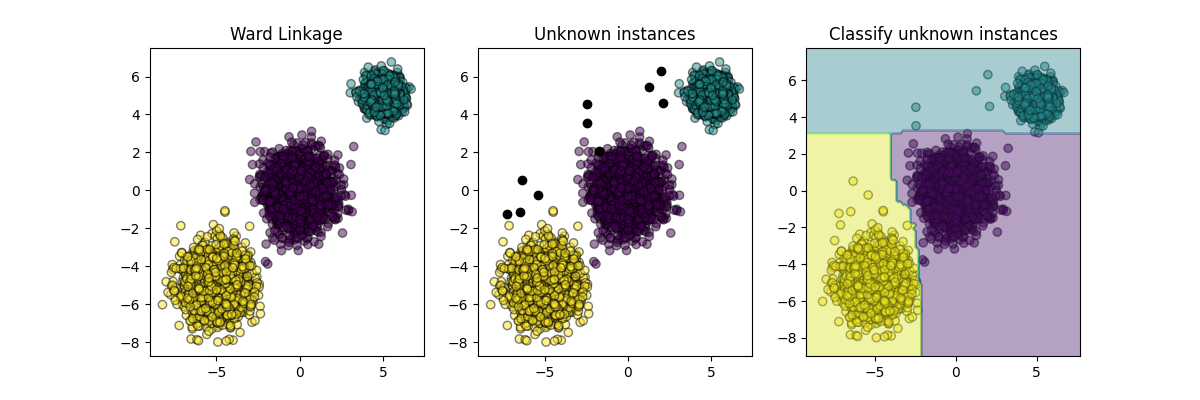
clusterer = AgglomerativeClustering(n_clusters=3)
cluster_labels = clusterer.fit_predict(X)
plt.figure(figsize=(12, 4))
plt.subplot(131)
plot_scatter(X, cluster_labels)
plt.title("Ward Linkage")
# توليد عينات جديدة ورسمها جنبًا إلى جنب مع مجموعة البيانات الأصلية
X_new, y_new = make_blobs(
n_samples=10, centers=[(-7, -1), (-2, 4), (3, 6)], random_state=RANDOM_STATE
)
plt.subplot(132)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, "black", 1)
plt.title("Unknown instances")
# إعلان نموذج التعلم الاستقرائي الذي سيتم استخدامه للتنبؤ بعضوية التصنيف للعينات غير المعروفة
classifier = RandomForestClassifier(random_state=RANDOM_STATE)
inductive_learner = InductiveClusterer(clusterer, classifier).fit(X)
probable_clusters = inductive_learner.predict(X_new)
ax = plt.subplot(133)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, probable_clusters)
# رسم مناطق القرار
DecisionBoundaryDisplay.from_estimator(
inductive_learner, X, response_method="predict", alpha=0.4, ax=ax
)
plt.title("Classify unknown instances")
plt.show()
Total running time of the script: (0 minutes 2.481 seconds)
Related examples