ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أبرز ميزات الإصدار 0.22 من scikit-learn#
يسعدنا أن نعلن عن إصدار scikit-learn 0.22، والذي يأتي مع العديد من الإصلاحات للمشاكل والميزات الجديدة! نستعرض أدناه بعض الميزات الرئيسية لهذا الإصدار. للحصول على قائمة شاملة بجميع التغييرات، يرجى الرجوع إلى ملاحظات الإصدار.
لتثبيت أحدث إصدار (مع pip):
pip install --upgrade scikit-learn
أو مع conda:
conda install -c conda-forge scikit-learn
# المؤلفون: مطوري scikit-learn
# معرف الترخيص: BSD-3-Clause
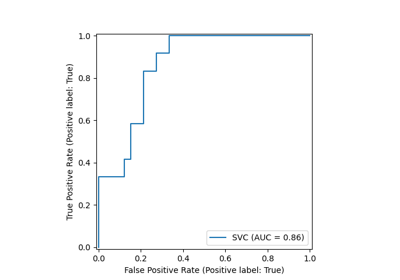
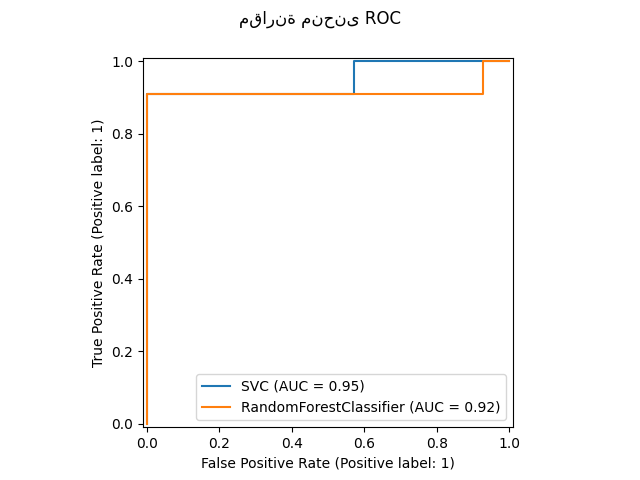
واجهة برمجة التطبيقات الجديدة للرسم#
تتوفر واجهة برمجة تطبيقات جديدة لإنشاء الرسوم البيانية. تسمح هذه الواجهة الجديدة
بالتعديل السريع للمظهر المرئي للرسم البياني دون الحاجة إلى إعادة الحساب. كما أنه من الممكن
إضافة مخططات مختلفة إلى نفس
الشكل. يوضح المثال التالي plot_roc_curve،
ولكن يتم دعم المرافق الأخرى للمخططات مثل
plot_partial_dependence،
plot_precision_recall_curve، و
plot_confusion_matrix. اقرأ المزيد حول هذه الواجهة الجديدة في
دليل المستخدم.
import matplotlib
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
# from sklearn.metrics import plot_roc_curve
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.utils.fixes import parse_version
X, y = make_classification(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
svc = SVC(random_state=42)
svc.fit(X_train, y_train)
rfc = RandomForestClassifier(random_state=42)
rfc.fit(X_train, y_train)
# plot_roc_curve تم إزالته في الإصدار 1.2. بدءًا من الإصدار 1.2، استخدم RocCurveDisplay بدلاً من ذلك.
# svc_disp = plot_roc_curve(svc, X_test, y_test)
# rfc_disp = plot_roc_curve(rfc, X_test, y_test, ax=svc_disp.ax_)
svc_disp = RocCurveDisplay.from_estimator(svc, X_test, y_test)
rfc_disp = RocCurveDisplay.from_estimator(rfc, X_test, y_test, ax=svc_disp.ax_)
rfc_disp.figure_.suptitle("مقارنة منحنى ROC")
plt.show()
مصنف التكديس والمُرجع#
StackingClassifier و
StackingRegressor
تسمح لك بوجود مجموعة من المُقدرات مع مُقدر نهائي أو
مُرجع.
يتكون التكديس العام من تكديس ناتج المُقدرات الفردية واستخدام مُصنف لحساب التوقع النهائي. يسمح التكديس
باستخدام قوة كل مُقدر فردي من خلال استخدام ناتجهم
كمدخل لمُقدر نهائي.
يتم تكييف المُقدرات الأساسية على "X" الكاملة بينما
يتم تدريب المُقدر النهائي باستخدام تنبؤات مُصادقة عبر القيمة باستخدام "cross_val_predict".
اقرأ المزيد في دليل المستخدم.
from sklearn.datasets import load_iris
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
X, y = load_iris(return_X_y=True)
estimators = [
("rf", RandomForestClassifier(n_estimators=10, random_state=42)),
("svr", make_pipeline(StandardScaler(), LinearSVC(dual="auto", random_state=42))),
]
clf = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
clf.fit(X_train, y_train).score(X_test, y_test)
0.9473684210526315
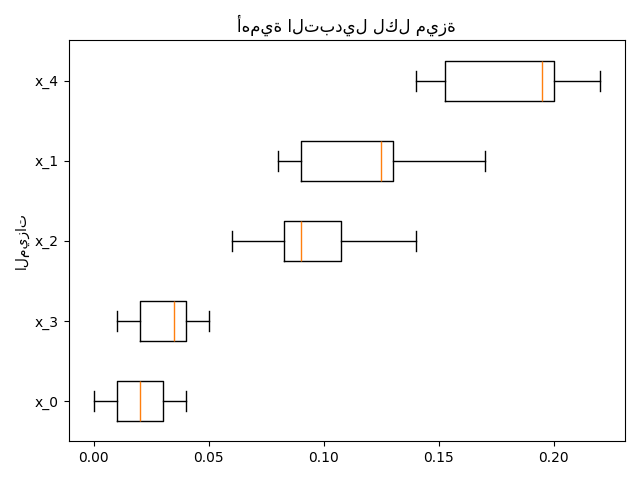
أهمية الميزات القائمة على التبديل#
يمكن استخدام inspection.permutation_importance للحصول على
تقدير لأهمية كل ميزة، لأي مُقدر مُدرب:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
X, y = make_classification(random_state=0, n_features=5, n_informative=3)
feature_names = np.array([f"x_{i}" for i in range(X.shape[1])])
rf = RandomForestClassifier(random_state=0).fit(X, y)
result = permutation_importance(rf, X, y, n_repeats=10, random_state=0, n_jobs=2)
fig, ax = plt.subplots()
sorted_idx = result.importances_mean.argsort()
# تم إيقاف `labels` argument في boxplot في matplotlib 3.9 وتمت إعادة تسميته إلى `tick_labels`. يتعامل الكود التالي مع هذا، ولكن كمستخدم لـ scikit-learn، يمكنك على الأرجح كتابة كود أبسط من خلال استخدام `labels=...`
# (matplotlib < 3.9) أو `tick_labels=...` (matplotlib >= 3.9).
tick_labels_parameter_name = (
"tick_labels"
if parse_version(matplotlib.__version__) >= parse_version("3.9")
else "labels"
)
tick_labels_dict = {tick_labels_parameter_name: feature_names[sorted_idx]}
ax.boxplot(result.importances[sorted_idx].T, vert=False, **tick_labels_dict)
ax.set_title("أهمية التبديل لكل ميزة")
ax.set_ylabel("الميزات")
fig.tight_layout()
plt.show()
الدعم الأصلي للقيم المفقودة للتعزيز التدريجي#
ensemble.HistGradientBoostingClassifier
و ensemble.HistGradientBoostingRegressor لديهم الآن دعم أصلي
للقيم المفقودة (NaNs). وهذا يعني أنه لا توجد حاجة
لملء البيانات عند التدريب أو التنبؤ.
from sklearn.ensemble import HistGradientBoostingClassifier
X = np.array([0, 1, 2, np.nan]).reshape(-1, 1)
y = [0, 0, 1, 1]
gbdt = HistGradientBoostingClassifier(min_samples_leaf=1).fit(X, y)
print(gbdt.predict(X))
[0 0 1 1]
رسم الجيران الأقرب القريب المُسبق#
معظم المُقدرات القائمة على رسوم الجيران الأقرب تقبل الآن الرسوم البيانية المُسبقة
المتناثرة كمدخل، لإعادة استخدام نفس الرسم البياني لعدة مُقدرات.
لاستخدام هذه الميزة في خط أنابيب، يمكنك استخدام معلمة "memory"، إلى جانب
أحد المحولين الجديدين،
neighbors.KNeighborsTransformer و
neighbors.RadiusNeighborsTransformer. يمكن أيضًا إجراء عملية ما قبل الحساب
بواسطة مُقدرات مخصصة لاستخدام التنفيذ البديل، مثل
أساليب الجيران الأقرب التقريبية.
راجع المزيد من التفاصيل في دليل المستخدم.
from tempfile import TemporaryDirectory
from sklearn.manifold import Isomap
from sklearn.neighbors import KNeighborsTransformer
from sklearn.pipeline import make_pipeline
X, y = make_classification(random_state=0)
with TemporaryDirectory(prefix="sklearn_cache_") as tmpdir:
estimator = make_pipeline(
KNeighborsTransformer(n_neighbors=10, mode="distance"),
Isomap(n_neighbors=10, metric="precomputed"),
memory=tmpdir,
)
estimator.fit(X)
# يمكننا تقليل عدد الجيران ولن يتم إعادة حساب الرسم البياني.
estimator.set_params(isomap__n_neighbors=5)
estimator.fit(X)
KNN Based Imputation#
نحن ندعم الآن إكمال القيم المفقودة باستخدام k-Nearest Neighbors.
يتم إكمال القيم المفقودة لكل عينة باستخدام متوسط القيمة من
"n_neighbors" الأقرب للجيران الذين تم العثور عليهم في مجموعة التدريب. العينتان قريبتان إذا كانت الميزات التي لا يفتقدها أي منهما قريبة.
بشكل افتراضي، يتم استخدام مقياس المسافة
الذي يدعم القيم المفقودة،
nan_euclidean_distances، للعثور على الجيران الأقرب.
اقرأ المزيد في دليل المستخدم.
from sklearn.impute import KNNImputer
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)
print(imputer.fit_transform(X))
[[1. 2. 4. ]
[3. 4. 3. ]
[5.5 6. 5. ]
[8. 8. 7. ]]
تقليم الشجرة#
أصبح من الممكن الآن تقليم معظم المُقدرات القائمة على الشجرة بمجرد بناء الأشجار. يعتمد التقليم على الحد الأدنى من التكلفة والتعقيد. اقرأ المزيد في دليل المستخدم للحصول على التفاصيل.
X, y = make_classification(random_state=0)
rf = RandomForestClassifier(random_state=0, ccp_alpha=0).fit(X, y)
print(
"متوسط عدد العقد بدون تقليم {:.1f}".format(
np.mean([e.tree_.node_count for e in rf.estimators_])
)
)
rf = RandomForestClassifier(random_state=0, ccp_alpha=0.05).fit(X, y)
print(
"متوسط عدد العقد مع التقليم {:.1f}".format(
np.mean([e.tree_.node_count for e in rf.estimators_])
)
)
متوسط عدد العقد بدون تقليم 22.3
متوسط عدد العقد مع التقليم 6.4
استرجاع جداول البيانات من OpenML#
datasets.fetch_openml يمكنه الآن إرجاع جداول بيانات Pandas وبالتالي
التعامل بشكل صحيح مع مجموعات البيانات ذات البيانات غير المتجانسة:
from sklearn.datasets import fetch_openml
titanic = fetch_openml("titanic", version=1, as_frame=True, parser="pandas")
print(titanic.data.head()[["pclass", "embarked"]])
pclass embarked
0 1 S
1 1 S
2 1 S
3 1 S
4 1 S
التحقق من توافق scikit-learn لمُقدر#
يمكن للمطورين التحقق من توافق مُقدراتهم المتوافقة مع scikit-learn باستخدام check_estimator. على
سبيل المثال، تمرير "check_estimator(LinearSVC())".
نحن نوفر الآن مُزخرف "pytest" محدد يسمح لـ "pytest" بتشغيل جميع الفحوصات بشكل مستقل والإبلاغ عن الفحوصات التي تفشل.
- ..note::
تم تحديث هذا الإدخال بشكل طفيف في الإصدار 0.24، حيث لم يعد دعم تمرير الفئات : قم بتمرير الحالات بدلاً من ذلك.
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.utils.estimator_checks import parametrize_with_checks
@parametrize_with_checks([LogisticRegression(), DecisionTreeRegressor()])
def test_sklearn_compatible_estimator(estimator, check):
check(estimator)
ROC AUC الآن يدعم التصنيف متعدد الفئات#
يمكن أيضًا استخدام دالة roc_auc_score في التصنيف متعدد الفئات.
يتم دعم استراتيجيتي المتوسط حاليًا: خوارزمية "one-vs-one" تحسب متوسط درجات ROC AUC الزوجية، و
تحسب خوارزمية "one-vs-rest" متوسط درجات ROC AUC لكل
فئة مقابل جميع الفئات الأخرى. في كلتا الحالتين، يتم حساب درجات ROC AUC متعددة الفئات
من تقديرات الاحتمالية التي تنتمي عينة إلى فئة معينة وفقًا للنموذج. تدعم خوارزميتا OvO و OvR
الوزن بشكل موحد (average='macro') والوزن حسب الانتشار
(average='weighted').
اقرأ المزيد في دليل المستخدم.
from sklearn.datasets import make_classification
from sklearn.metrics import roc_auc_score
from sklearn.svm import SVC
X, y = make_classification(n_classes=4, n_informative=16)
clf = SVC(decision_function_shape="ovo", probability=True).fit(X, y)
print(roc_auc_score(y, clf.predict_proba(X), multi_class="ovo"))
0.9992000000000001
Total running time of the script: (0 minutes 1.687 seconds)
Related examples