ملاحظة
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
أهمية التبديل مقابل أهمية ميزة الغابة العشوائية (MDI)#
في هذا المثال، سنقارن أهمية الميزة القائمة على الشوائب لـ
RandomForestClassifier مع أهمية
التبديل على مجموعة بيانات تيتانيك باستخدام
permutation_importance. سنوضح أن أهمية الميزة القائمة على الشوائب يمكن أن تبالغ في أهمية الميزات الرقمية.
علاوة على ذلك، تعاني أهمية الميزة القائمة على الشوائب للغابات العشوائية من حسابها على إحصائيات مشتقة من مجموعة بيانات التدريب: يمكن أن تكون الأهمية عالية حتى بالنسبة للميزات التي لا تتوقع المتغير الهدف، طالما أن النموذج لديه القدرة على استخدامها للملاءمة الزائدة.
يوضح هذا المثال كيفية استخدام أهمية التبديل كبديل يمكن أن يخفف من هذه القيود.
المراجع
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
تحميل البيانات وهندسة الميزات#
دعونا نستخدم الباندا لتحميل نسخة من مجموعة بيانات تيتانيك. يوضح ما يلي كيفية تطبيق معالجة مسبقة منفصلة على الميزات الرقمية والفئوية.
نقوم أيضًا بتضمين متغيرين عشوائيين غير مرتبطين بأي شكل من الأشكال بالمتغير الهدف (survived):
random_numهو متغير رقمي ذو عدد كبير من القيم الفريدة (بنفس عدد القيم الفريدة مثل السجلات).random_catهو متغير فئوي ذو عدد قليل من القيم الفريدة (3 قيم ممكنة).
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
rng = np.random.RandomState(seed=42)
X["random_cat"] = rng.randint(3, size=X.shape[0])
X["random_num"] = rng.randn(X.shape[0])
categorical_columns = ["pclass", "sex", "embarked", "random_cat"]
numerical_columns = ["age", "sibsp", "parch", "fare", "random_num"]
X = X[categorical_columns + numerical_columns]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
نقوم بتعريف نموذج تنبؤي قائم على غابة عشوائية. لذلك، سنتخذ خطوات المعالجة المسبقة التالية:
استخدام
OrdinalEncoderلتشفير الميزات الفئوية؛استخدام
SimpleImputerلملء القيم المفقودة للميزات الرقمية باستخدام إستراتيجية المتوسط.
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OrdinalEncoder
categorical_encoder = OrdinalEncoder(
handle_unknown="use_encoded_value", unknown_value=-1, encoded_missing_value=-1
)
numerical_pipe = SimpleImputer(strategy="mean")
preprocessing = ColumnTransformer(
[
("cat", categorical_encoder, categorical_columns),
("num", numerical_pipe, numerical_columns),
],
verbose_feature_names_out=False,
)
rf = Pipeline(
[
("preprocess", preprocessing),
("classifier", RandomForestClassifier(random_state=42)),
]
)
rf.fit(X_train, y_train)
دقة النموذج#
قبل فحص أهمية الميزات، من المهم التحقق من أن أداء النموذج التنبؤي مرتفع بما فيه الكفاية. في الواقع، سيكون هناك اهتمام ضئيل بفحص الميزات المهمة لنموذج غير تنبؤي.
هنا يمكن للمرء أن يلاحظ أن دقة التدريب عالية جدًا (نموذج الغابة لديه قدرة كافية لحفظ مجموعة التدريب بالكامل) ولكنه لا يزال بإمكانه التعميم بشكل جيد بما فيه الكفاية على مجموعة الاختبار بفضل التجميع المدمج للغابات العشوائية.
قد يكون من الممكن التخلي عن بعض الدقة في مجموعة التدريب للحصول على دقة أفضل قليلاً في مجموعة الاختبار عن طريق الحد من قدرة الأشجار (على سبيل المثال عن طريق تعيين min_samples_leaf=5 أو min_samples_leaf=10) للحد من الملاءمة الزائدة مع عدم إدخال الكثير من نقص الملاءمة.
ومع ذلك، دعونا نحتفظ بنموذج الغابة العشوائية عالي القدرة لدينا في الوقت الحالي لتوضيح بعض المزالق المتعلقة بأهمية الميزات على المتغيرات التي تحتوي على العديد من القيم الفريدة.
print(f"دقة تدريب RF: {rf.score(X_train, y_train):.3f}")
print(f"دقة اختبار RF: {rf.score(X_test, y_test):.3f}")
دقة تدريب RF: 1.000
دقة اختبار RF: 0.814
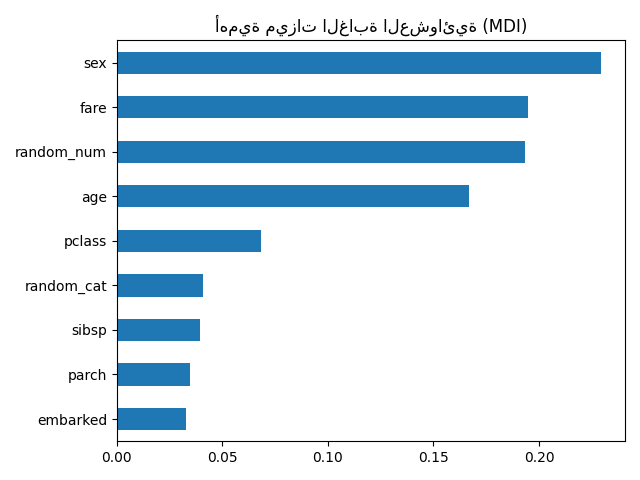
أهمية ميزة الشجرة من متوسط الانخفاض في الشوائب (MDI)#
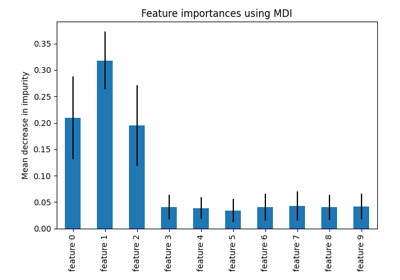
تصنف أهمية الميزة القائمة على الشوائب الميزات الرقمية على أنها أهم الميزات. نتيجة لذلك، يتم تصنيف المتغير غير التنبؤي random_num كواحد من أهم الميزات!
تنبع هذه المشكلة من قيدين لأهمية الميزات القائمة على الشوائب:
أهمية الميزات القائمة على الشوائب متحيزة تجاه الميزات ذات العدد الكبير من القيم الفريدة؛
يتم حساب أهمية الميزات القائمة على الشوائب على إحصائيات مجموعة التدريب، وبالتالي لا تعكس قدرة الميزة على أن تكون مفيدة في عمل تنبؤات تعمم على مجموعة الاختبار (عندما يكون للنموذج قدرة كافية).
التحيز تجاه الميزات ذات العدد الكبير من القيم الفريدة يفسر سبب كون random_num ذات أهمية كبيرة حقًا مقارنة بـ random_cat بينما نتوقع أن يكون لكلا الميزتين العشوائيتين أهمية معدومة.
حقيقة أننا نستخدم إحصائيات مجموعة التدريب تفسر سبب كون كل من ميزتي random_num و random_cat ذات أهمية غير معدومة.
import pandas as pd
feature_names = rf[:-1].get_feature_names_out()
mdi_importances = pd.Series(
rf[-1].feature_importances_, index=feature_names
).sort_values(ascending=True)
ax = mdi_importances.plot.barh()
ax.set_title("أهمية ميزات الغابة العشوائية (MDI)")
ax.figure.tight_layout()
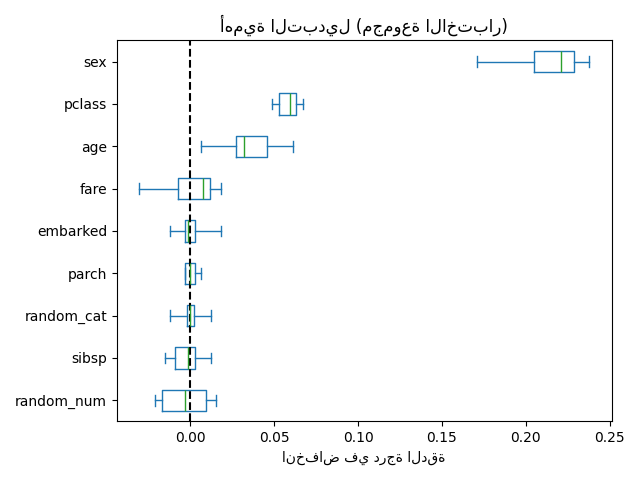
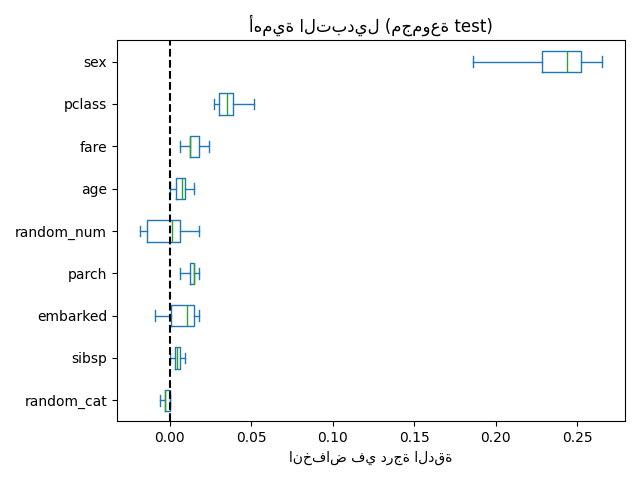
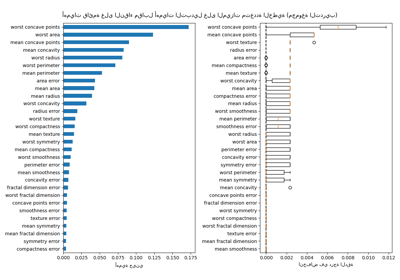
كبديل، يتم حساب أهمية التبديل لـ rf على مجموعة اختبار معلقة. يوضح هذا أن الميزة الفئوية ذات العدد القليل من القيم الفريدة، sex و pclass، هي أهم الميزات. في الواقع، سيؤدي تبديل قيم هذه الميزات إلى أكبر انخفاض في درجة دقة النموذج على مجموعة الاختبار.
لاحظ أيضًا أن كلا الميزتين العشوائيتين لهما أهمية منخفضة جدًا (قريبة من 0) كما هو متوقع.
from sklearn.inspection import permutation_importance
result = permutation_importance(
rf, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = result.importances_mean.argsort()
importances = pd.DataFrame(
result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
ax = importances.plot.box(vert=False, whis=10)
ax.set_title("أهمية التبديل (مجموعة الاختبار)")
ax.axvline(x=0, color="k", linestyle="--")
ax.set_xlabel("انخفاض في درجة الدقة")
ax.figure.tight_layout()
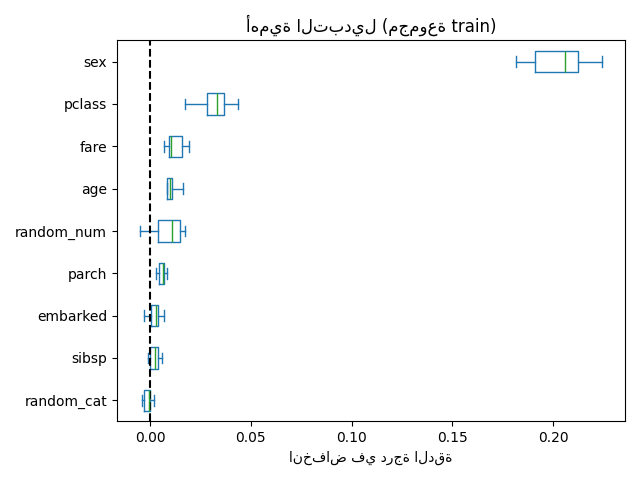
من الممكن أيضًا حساب أهمية التبديل على مجموعة التدريب. يكشف هذا أن random_num و random_cat يحصلان على تصنيف أهمية أعلى بكثير مما هو عليه عند حسابهما على مجموعة الاختبار. الفرق بين هذين المخططين هو تأكيد على أن نموذج RF لديه قدرة كافية لاستخدام هذه الميزات الرقمية والفئوية العشوائية للملاءمة الزائدة.
result = permutation_importance(
rf, X_train, y_train, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = result.importances_mean.argsort()
importances = pd.DataFrame(
result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
ax = importances.plot.box(vert=False, whis=10)
ax.set_title("أهمية التبديل (مجموعة التدريب)")
ax.axvline(x=0, color="k", linestyle="--")
ax.set_xlabel("انخفاض في درجة الدقة")
ax.figure.tight_layout()
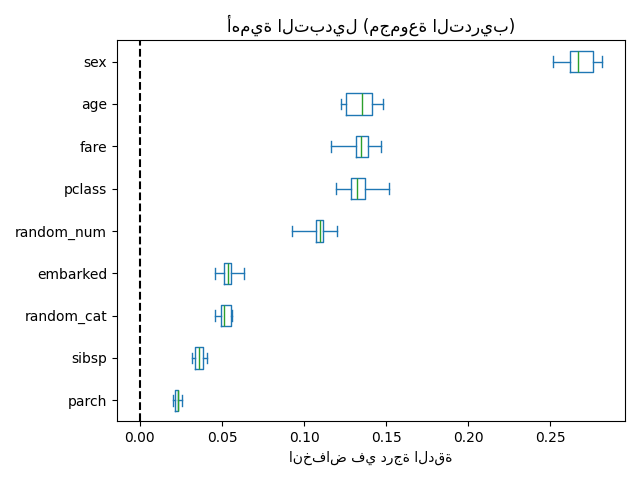
يمكننا أيضًا إعادة محاولة التجربة عن طريق الحد من قدرة الأشجار على الملاءمة الزائدة عن طريق تعيين min_samples_leaf على 20 نقطة بيانات.
rf.set_params(classifier__min_samples_leaf=20).fit(X_train, y_train)
بملاحظة درجة الدقة على مجموعتي التدريب والاختبار، نلاحظ أن كلا المقياسين متشابهان جدًا الآن. لذلك، لم يعد نموذجنا يعاني من ملاءمة زائدة. يمكننا بعد ذلك التحقق من أهمية التبديل مع هذا النموذج الجديد.
print(f"دقة تدريب RF: {rf.score(X_train, y_train):.3f}")
print(f"دقة اختبار RF: {rf.score(X_test, y_test):.3f}")
دقة تدريب RF: 0.810
دقة اختبار RF: 0.832
train_result = permutation_importance(
rf, X_train, y_train, n_repeats=10, random_state=42, n_jobs=2
)
test_results = permutation_importance(
rf, X_test, y_test, n_repeats=10, random_state=42, n_jobs=2
)
sorted_importances_idx = train_result.importances_mean.argsort()
train_importances = pd.DataFrame(
train_result.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
test_importances = pd.DataFrame(
test_results.importances[sorted_importances_idx].T,
columns=X.columns[sorted_importances_idx],
)
for name, importances in zip(["train", "test"], [train_importances, test_importances]):
ax = importances.plot.box(vert=False, whis=10)
ax.set_title(f"أهمية التبديل (مجموعة {name})")
ax.set_xlabel("انخفاض في درجة الدقة")
ax.axvline(x=0, color="k", linestyle="--")
ax.figure.tight_layout()
الآن، يمكننا أن نلاحظ أنه في كلا المجموعتين، تتمتع ميزات random_num و random_cat بأهمية أقل مقارنة بغابة عشوائية ذات ملاءمة زائدة. ومع ذلك، فإن الاستنتاجات المتعلقة بأهمية الميزات الأخرى لا تزال سارية.
Total running time of the script: (0 minutes 6.479 seconds)
Related examples
أهمية التبديل مع الميزات متعددة الخطية أو المرتبطة